Lexical Resources
Christophe Cerisara
2023/2024
Lexical Resources: introduction
Course plan (indicative !)
| CM | Topic |
|---|---|
| 07/12 | intro: get/build Lex Res |
| 08/01 | Overview of embeddings |
| 15/01 | WordNet + FrameNet |
| 22/01 | VerbNet + PropBank |
| 29/01 | Transformers 1 |
| 05/02 | Transformers 2 |
| 16/02 | Examen |
Course requirements:
- Basics of python
- Access to a computer (in & outside class)
- With python + numpy + scipy + nltk + pytorch installed
- Internet access in & outside class (eduroam)
- Any question:
- cerisara@loria.fr
- slides: https://members.loria.fr/CCerisara/#courses/lexical_resources/
Content of the course
- How to create (transform) LR
Manually: annotation guides, quality…- Automatically
Scrap/curate texts, RDF extraction…- Text processing: Ngram, embeddings, LLM
- How to use LR
From XML files (
SPARQL…)- From python: NLTK, words embeddings, LLM
Today’s concepts
- Motivation, concepts about LR
- Where to get LR from
- How to process LR; example: Wiktionary
Concepts
What is a lexical resource ?
- Axel Herold: “collection of lexical items, together with linguistic information and/or classification of these items”
- lexical items = words, multi-words, sub-word units
- dictionary = usable by humans
- LR = usable by machines
- information: spelling, phonetics, category, relations (semantics…)
Usable by machines ?
- Ideally: standard formats (XML, TEI, RDF…)
- In practice:
- ad-hoc formats (CoNLL, JSON, text…)
- Examples: CoNLL, TextGrid, TEI, LMF
Formats
CoNLL example
1 They they PRON PRP Case=Nom|Number=Plur 2 nsubj 2:nsubj|4:nsubj
2 buy buy VERB VBP Number=Plur|Person=3|Tense=Pres 0 root 0:root
3 and and CONJ CC _ 4 cc 4:cc
4 sell sell VERB VBP Number=Plur|Person=3|Tense=Pres 2 conj 0:root|2:conj
5 books book NOUN NNS Number=Plur 2 obj 2:obj|4:obj
6 . . PUNCT . _ 2 punct 2:punctTextGrid example
item [1]:
class = "IntervalTier"
name = "sentence"
xmin = 0
xmax = 2.3
intervals: size = 1
intervals [1]:
xmin = 0
xmax = 2.3
text = "říkej ""ahoj"" dvakrát"
item [2]:
class = "IntervalTier"
name = "phonemes"
xmin = 0
xmax = 2.3
intervals: size = 3
intervals [1]:
xmin = 0
xmax = 0.7
text = "r̝iːkɛj"
intervals [2]:
xmin = 0.7
xmax = 1.6
text = "ʔaɦɔj"Text Encoding Initiative
- different views of a dictionary:
- typographic view: “the two-dimensional printed page” (include page layout)
- editorial view: “one-dimensional sequence of tokens”
- lexical view: structured lexicographical information, may include lexical data not present in the text
- TEI guidelines: encode one view with primary XML structure; another view in XML attributes
- lexical view = most important for Lexical Resources, so encoded in XML structure
<entry xml:id="a_1">
<form>
<orth>Bahnhof</orth>
</form>
<gramGrp>
<pos value="N" />
<gen value="masculine" />
</gramGrp>
<sense>
<def>...</def>
<cit>
<quote>der Zug fährt in den Bahnhof ein</quote>
</cit>
</sense>
<!-- ... -->
<sense>
<def>...</def>
</sense>
</entry>- “entry” = basic unit of information
- includes “form” and “sense”
- “gramGrp” = grammatical information
- may also be put as a child of “form”, to make it depend on a specific form
- reference to the CLARIN concept registry:
<gramGrp>
<pos value="N"
dcr:datcat="http://hdl.handle.net/11459/CCR_C-5524_d8864ad4-1bdf-ee56-594e-784312129ea7"
dcr:valueDatcat="http://hdl.handle.net/11459/CCR_C-3347_7face0f5-7a72-7ec2-c988-7adba256cea9" />
</gramGrp>Lexical Markup Format
- focus only on the lexical representation of data == lexical view of TEI
- goal = meta-model for all types of NLP lexicons
- reference to data category registry mandatory
- Packages: core, morphology, MWE, syntax…
<LexicalEntry>
<feat att="partOfSpeech" val="noun" />
<feat att="gender" val="masculine" />
<Lemma>
<feat att="writtenForm" val="Bahnhof" />
</Lemma>
<WordForm>
<feat att="writtenForm" val="Bahnhof" />
<feat att="grammaticalNumber" val="singular" />
</WordForm>
<WordForm>
<feat att="writtenForm" val="Bahnhöfe" />
<feat att="grammaticalNumber" val="plural" />
</WordForm>
<Sense id="s1">
</Sense>
<!-- ... -->
<Sense id="sn">
</Sense>
</LexicalEntry>- LMF only focuses on NLP, so much tighter than TEI
- so easier for electronic lexicographic resources
- XML serialization: RELISH, KYOTO, LIRICS…
Content of LR
Two types of LR
- Manually built
- WordNet, FrameNet, VerbNet, PropBank, DBPedia, BabelNet, Wiktionary…
- Example: BDLEX
- contains 440k inflected forms
- source: Univ. Paul Sabatier
- distributor: ELRA (2k€ non commercial)
Two types of LR
- “Automatically” built
- Google Ngrams
- Words embeddings, LLM
- no XML any more !
- Info contained in LLMs:
- lexical, morphosyntax, syntax
- semantics
- dialogic, multilingual, multimodal
- common sense, (historical) facts, emotions…
Usage of LLM
- As a dictionary (for you)
- just ask the LLM
- As a Lexical Resource
- through embeddings:
- input -> LLM -> representation
- repr -> code/ML -> task
- through text generation:
- input -> LLM -> text
- text -> parsing -> code/ML
- through embeddings:
Availability of manual LR
Non-free Lex Res
Main distributors:
- ELRA/ELDA (Europe)
- European companies/univ. (CNRS)
- 1400 resources
- CoNLL,
- very few free resources:
- MLCC Multilingual and Parallel Corpora
Non-free Lex Res
- LDC (Linguistic Data Consortium) (USA)
- funded by ARPA and NSF
- hosted by Univ. Pennsylvania
- catalogue: 100s of resources
- TIMIT, Switchboard, Gigaword…
“Freely” available
- Distributed by Univ./organisms
- EuroParl: https://www.statmt.org/europarl/
- CNRTL/ATILF:
- TLFi, Morphalou, Frantext…
- ORTOLANG:
- 500 resources: Dicovalence, patois de St-Martin-la-Porte…
- Isidore.science: 20 datasets
- …
International Networks
- https://live.european-language-grid.eu/
- 2000 links to resources (e.g. to ELRA…)
- LINDAT
- linghub.org
European Open Science Cloud
- CLARIN
- VLO (Virtual Language Observatory): 800k resources
International Networks
- Linguistic Linked Open Data (LLOD) initiative
- Principles:
- Creative Commons licenses
- Accessible via URI
- RDF Standard
- Linked Data
- Principles:
Uniform Resource Identifier
- URI = unique identification
- may be URN or URL
- example of URN:
- urn:isbn:0-486-27557-4
- Specific edition of Shakespeare’s play Romeo and Juliet
- example of URL: http://example.org/wiki/Main_Page
Resource Description Framework
- family of W3C specifications
- based on triples:
- Subject: a resource
- Predicate: relation
- Object: another resource
(cf. course of Mathieu D’Aquin)
LOD vision
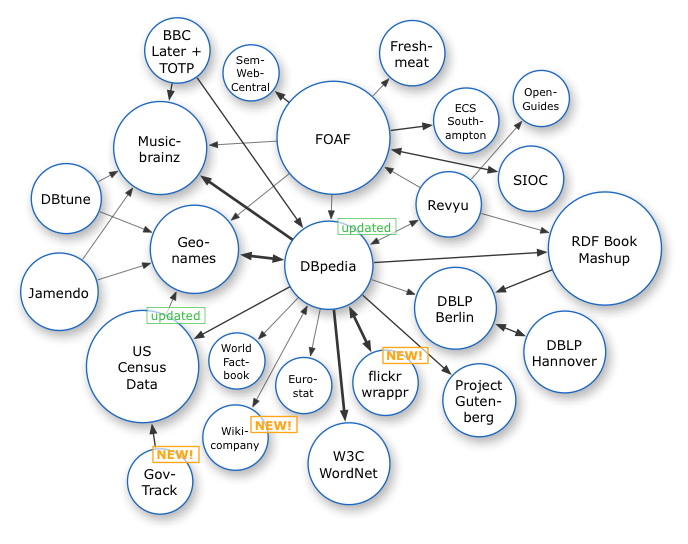
Ex: Princeton WordNet
<LexicalEntry id ='w44919'>
<Lemma writtenForm='quantification' partOfSpeech='n'/>
<Sense id='w44919_01003570-n' synset='eng-10-01003570-n'/>
<Sense id='w44919_06165623-n' synset='eng-10-06165623-n'/>
</LexicalEntry> [...]
<Synset id='eng-10-01003570-n' baseConcept='3'>
<Definition gloss="the act of discovering or expressing the quantity of something"> </Definition>
<SynsetRelations>
<SynsetRelation targets='eng-10-00996969-n' relType='hype'/>
<SynsetRelation targets='eng-10-01003729-n' relType='hypo'/>
</SynsetRelations>
</Synset>Collection of RDF triples
- In theory = labeled directed multi-graph
- In practice:
- Relational database
- or Triplestores
- cf. course on Semantic Web
- Tutorial on LOD
Development of LLOD
- 2016: OntoLex-Lemon vocabulary (W3C)
- WebAnnotation (W3C)
SPARQL to access RDF
- Summer Datathon on LLOD
- H2020 project “Prêt-à-LLOD”
ELEXIS project “European Lexicographic Infrastructure”
Resources
(Chiarcos, IWLTP’2020):
“Working with RDF normally requires a certain level of technical expertise, i.e., basic knowledge of SPARQL and at least one RDF format.”
Resources
https://livebook.manning.com/book/linked-data/chapter-2/1
Availability of LLM
- LLMs can be more or less open / closed
- Totally closed LLMs:
- ChatGPT, Bard, Claude…
- Open:
- distribute weights, training data + scripts + docs/logs
- permissive license (commercial? use LLM outputs?…)
- respect legislation? (RGPD, EU AI Act…)

- LLM most compliant with AI-Act: Bloom!
- RAIL ‘responsible’ license: open
- but cannot use it for healthcare diagnostics!
- Llama license: no commercial usage
- Llama2 license: no training on outputs
- …
400k LLMs available on Huggingface Hub !
Building LR from texts
- Relying on manual LR is rarely a good option:
- too costly & rare
- Exception: collaborative LRs like Wiktionary!
- Ex: you want a list of words in some domain
- WordNet does not cover every domain
- WordNet is not up-to-date
- Better alternative: create target LR from raw data
- can be specific for any domain/language/…
- small cost
- Ex: you want a list of words in some domain
- grab in-domain texts; extract lexicon
- Note: LLMs are LRs extracted from raw data
… But WordNet has much richer relations (antonyms, hypernyms…) than list of words!
- cf. the old debate ML (coverage) vs. expertise/symbolic (precision, richness)
- Not true anymore with LLMs:
- LLMs know about most relations: antonyms, hypernyms…
- and LLMs can learn more complex relations
- So the best approach today:
- extract in-domain LR and enrich them with LLM
Text sources
- Generic
- Many (English) texts available: CommonCrawl, ThePile, RedPajama (30T tokens)…
- Rare languages? (7000 languages known)
- Bible: 800-2000 languages
- Lexicons: 1000s languagues
- Internet: 100s languages
- Specific
- Ex: on github, 13T tokens of code + language
- Shall be obtained: PDF scans, on-site speech recordings…
Required quantity
- Depends on the objective/task
- Training a new LLM:
- cf. Chinchilla scaling laws
- Adapting an LLM to a new language:
- 1M tokens
- Adapting an LLM to a domain:
- 1000s tokens
- few-shot learning
- zero-shot learning
Text analysis in this course
- Challenges:
- Choose one or multiple sources of texts
- Scrap the texts (see other course)
- Preprocess texts (see other course)
- Extract lexical information
Sources of texts
- Generic information or specialized domain (healthcare…) ?
- Large variability in language:
- Casual: forums, conversations…
- Micro-blog
- Formal: books…
- Journalistic: news
- Educative: moocs, tutorials…
- …
Sources of texts
Have I the right to scrap the text ?
It’s not because it’s public that you can copy it !!
- Check whether there is a license, like Creative Commons, otherwise: “all rights reserved”
- Beyond legal aspects, more and more concerns about privacy & right to be forgotten
- Anonymization does not guarantee privacy !
Sources of texts
Have I the right to scrap the text ?
- Twitter provided API to download some data, but forbids you to keep them on your harddrive.
- You cannot redistribute texts without explicit CC-BY licence
(Wait… doesn’t Google scrap the whole web since many years ?)
Sources of texts
- Unsafe sources of texts:
- Social media
- Most web pages
- Safe sources of texts:
- Wikipedia & derivatives (CC-BY)
- Scientific papers: arXiv, pubMed, HAL…
- Gutenberg, Gallica…
- Owners datasets? AskUbuntu archives, reddit archives, (Common Crawl), (WebTimeMachine)…
Open text sources
- The Pile
- 825GB of text
- CommonCrawl, PubMed, ArXiv, OpenWebText2, Bibliotik, Subtitles, Gutenberg…
- C4 dataset
- 380GB in JSON
- CommonCrawl curated
Sources of texts
- Is there a limit?
Scrapping texts
There are several ways to download corpora:
- APIs: not standard, may change, heavy for servers
- dumps archive (wikipedia, reddit…)
- peer-to-peer (academic torrents)
- OAI-PMH
- …
See course on basic NLP techniques (Yannick Parmentier)
Pre-processing texts
- Texts comes with metadata, in XML, JSON…
- Use adequate parsers
- Then:
- Filter out garbage (other language, errors…)
- Segmentation + tokenization
- Normalize (dates…)
- Compute features (POStags…)
See Claire Gardent’s course.
Example: wiktionary
- Goal: build a LR that associate French words to their etymology from Wiktionary
- Access dumps: https://dumps.wikimedia.org/frwiktionary/
- Download this version (500MB): https://olki.loria.fr/cerisara/lexres/frwik.xml.bz2
First look at the data
- look at the beginning of the file
- locate the XML structure
- locate the MediaWiki format
- Easiest way to do that: bash!
- linux OK, Mac OK, Windows: WSL
bzcat frwik.xml.bz2 | less
- find the position of the article about Nancy:
bzcat frwik.xml.bz2 | grep -n '<title>Nancy</title>'- look at the page:
bzcat frwik.xml.bz2 | tail -n +12872178 | less <title>Nancy</title>
<ns>0</ns>
<id>271346</id>
<revision>
<id>29517974</id>
<parentid>28848867</parentid>
<timestamp>2021-06-10T00:19:11Z</timestamp>
<contributor>
<username>Lingua Libre Bot</username>
<id>229398</id>
</contributor>
<comment>Ajout d'un fichier audio de prononciation depuis Lingua Libre</comment>
<model>wikitext</model>
<format>text/x-wiki</format>
<text bytes="7282" xml:space="preserve">{{voir|nancy}}
== {{langue|fr}} ==
=== {{S|étymologie}} ===
: {{date|lang=fr|1073}} La première trace écrite de Nancy date du 29 avril 1073 (mention dans la charte de Pibon, évêque de Toul : « Olry, voué de Nancy » (« ''Odelrici advocati de Nanceio'' »). Le nom serait cependant d’origine celtique, car on le rapproche du gaulois ''{{lien|nantu-|gaulois}}''/''{{lien|nanto-|gaulois}}'', qui signifie « [[val]], [[vallée]] », ou de {{recons|lang-mot-vedette=fr|nantus|gaulois}} (« ruisseau »).
=== {{S|nom de famille|fr}} ===
'''Nancy''' {{pron|nɑ̃.si|fr}}
# Nom de famille.
=== {{S|nom propre|fr}} ===
{{fr-inv|nɑ̃.si|inv_titre=Nom propre}}
'''Nancy''' {{pron|nɑ̃.si|fr}}
# {{localités|fr|du département de la Meurthe-et-Moselle}} [[commune|Commune]], [[ville]] et [[chef-lieu de département]] [[français]], situé dans le département de la [[Meurthe-et-Moselle]].
#* '''''Nancy''' est une ville d’ordre et de lumières où dès le XVII{{e}} et le XVIII{{e}} siècle, des ducs intelligents furent, sans le savoir, les précurseurs heureux de nos urbanistes modernes.'' {{source|{{Citation/Ludovic Naudeau/La France se regarde/1931}}}}
#* ''La verrerie de '''Nancy''' est de fondation récente, puisqu’elle date de 1875 seulement.'' {{source|Gustave Fraipont; ''Les Vosges'', 1923}}Using APIs
- after pip install wikipedia
import wikipedia
print(wikipedia.summary("Nancy, France"))Nancy is the capital of the northeastern French department of Meurthe-et-Moselle, the former capital of the Duchy of Lorraine, and then the French province of the same name. The metropolitan area of Nancy had a population of 511,257 inhabitants at the 2018 census, making it the 16th largest urban area in France and the Lorraine's largest. The population of the city of Nancy proper is 104,885.
The motto of the city is Non inultus premor, Latin for '"I am not injured unavenged"'—a reference to the thistle, which is a symbol of Lorraine.
Place Stanislas, a large square built between March 1752 and November 1755 by Stanislaus I of Poland to link the medieval old town of Nancy and the new town built under Charles III in the 17th century, is a UNESCO World Heritage Site, the first place in France and in the top four in the world. The city also has many buildings listed as historical monuments and is one of the European centers of Art Nouveau thanks to the École de Nancy. Nancy is also one of the main university cities and, with the Centre Hospitalier Régional Universitaire de Brabois, the conurbation is home to one of the main health centers in Europe, renowned for its innovations in surgical robotics.- Python API lib:
- easy way to access a few data
- uses Wikipedia API (online only)
- not all details, not designed for batch processing
- XML processing:
- works offline, all data accessible
- (very) hard to parse XML
Working from JSon
- pre-converted Wiktionaries: https://kaikki.org/dictionary/French/index.html
- get definition:
grep Nancy kaikki.org-dictionary-French.jsonWorking from JSon
{"pos": "name", "heads": [{"template_name": "fr-proper noun"}], "word": "Nancy", "lang": "French", "lang_code": "fr", "sounds": [{"ipa": "/n\u0251\u0303.si/"}], "categories": ["Cities in France"], "senses": [{"categories": ["French female given names", "French given names"], "tags": ["feminine"], "glosses": ["A female given name from English borrowed from English."], "id": "Nancy-name"}]}
{"pos": "name", "heads": [{"template_name": "fr-proper noun"}], "categories": ["Cities in France"], "word": "Nancy", "lang": "French", "lang_code": "fr", "sounds": [{"ipa": "/n\u0251\u0303.si/"}], "senses": [{"glosses": ["Nancy (the city)."], "derived": [{"word": "nanc\u00e9ien"}, {"word": "Nanc\u00e9ien"}], "id": "Nancy-name"}]}
{"pos": "noun", "heads": [{"1": "m", "f": "Nanc\u00e9ienne", "template_name": "fr-noun"}], "forms": [{"form": "Nanc\u00e9iens", "tags": ["plural"]}, {"form": "Nanc\u00e9ienne", "tags": ["feminine"]}], "word": "Nanc\u00e9ien", "lang": "French", "lang_code": "fr", "senses": [{"tags": ["masculine"], "glosses": ["an inhabitant of the city of Nancy"], "categories": ["Demonyms"], "id": "Nanc\u00e9ien-noun"}]}- Better way to extract word definitions:
- json is easier to parse than MediaWiki-XML
Working from the dump
- Handle XML structure
- Handle WikiMedia encoding
<title>Nancy</title>
<ns>0</ns>
<id>271346</id>
<revision>
<id>29517974</id>
<parentid>28848867</parentid>
<timestamp>2021-06-10T00:19:11Z</timestamp>
<contributor>
<username>Lingua Libre Bot</username>
<id>229398</id>
</contributor>
<comment>Ajout d'un fichier audio de prononciation depuis Lingua Libre</comment>
<model>wikitext</model>
<format>text/x-wiki</format>
<text bytes="7282" xml:space="preserve">{{voir|nancy}}
== {{langue|fr}} ==
=== {{S|étymologie}} ===
: {{date|lang=fr|1073}} La première trace écrite de Nancy date du 29 avril 1073 (mention dans la charte de Pibon, évêque de Toul : « Olry, voué de Nancy » (« ''Odelrici advocati de Nanceio'' »). Le nom serait cependant d’origine celtique, car on le rapproche du gaulois ''{{lien|nantu-|gaulois}}''/''{{lien|nanto-|gaulois}}'', qui signifie « [[val]], [[vallée]] », ou de {{recons|lang-mot-vedette=fr|nantus|gaulois}} (« ruisseau »).
=== {{S|nom de famille|fr}} ===
'''Nancy''' {{pron|nɑ̃.si|fr}}
# Nom de famille.
=== {{S|nom propre|fr}} ===
{{fr-inv|nɑ̃.si|inv_titre=Nom propre}}
'''Nancy''' {{pron|nɑ̃.si|fr}}
# {{localités|fr|du département de la Meurthe-et-Moselle}} [[commune|Commune]], [[ville]] et [[chef-lieu de département]] [[français]], situé dans le département de la [[Meurthe-et-Moselle]].
#* '''''Nancy''' est une ville d’ordre et de lumières où dès le XVII{{e}} et le XVIII{{e}} siècle, des ducs intelligents furent, sans le savoir, les précurseurs heureux de nos urbanistes modernes.'' {{source|{{Citation/Ludovic Naudeau/La France se regarde/1931}}}}
#* ''La verrerie de '''Nancy''' est de fondation récente, puisqu’elle date de 1875 seulement.'' {{source|Gustave Fraipont; ''Les Vosges'', 1923}}Parsing XML structure
- Python code with xml.sax lib:
- create a XML SAX parser
- feed every line into the parser
- The parser calls user methods when:
- start of XML element
- end of XML element
- for every char in the element
import bz2
import xml.sax
class WikiXmlHandler(xml.sax.handler.ContentHandler):
def __init__(self):
xml.sax.handler.ContentHandler.__init__(self)
self._buffer = None
self._values = {}
self._current_tag = None
def characters(self, content):
"""Characters between opening and closing tags"""
if self._current_tag:
self._buffer.append(content)
def startElement(self, name, attrs):
"""Opening tag of element"""
if name in ('title', 'text'):
self._current_tag = name
self._buffer = []
def endElement(self, name):
"""Closing tag of element"""
if name == self._current_tag:
self._values[name] = ' '.join(self._buffer)
if name == 'page':
print(self._values['title'], self._values['text'])
handler = WikiXmlHandler()
parser = xml.sax.make_parser()
parser.setContentHandler(handler)
with bz2.open("frwik.xml.bz2", "rt") as f:
for line in f:
parser.feed(line)- Running the above code removes all XML structure:
accueil {{voir|Accueil}}
== {{langue|fr}} ==
=== {{S|étymologie}} ===
: {{siècle|XII}} {{déverbal|de=accueillir|lang=fr|m=1}}.
=== {{S|nom|fr}} ===
{{fr-rég|a.kœj}}
'''accueil''' {{pron|a.kœj|fr}} {{m}}
# [[cérémonie|Cérémonie]] ou [[prestation]] réservée à un nouvel [[arrivant]], consistant généralement à lui [[souhaiter]] la [[bienvenue]] et à l’aider dans son [[intégration]] ou ses [[démarche]]s.
#* ''Nous réservâmes aux nouveaux venus un '''accueil''' qui fut cordial et empressé, mais le temps n’était pas aux effusions et d’un commun avis, il fallait agir vite.'' {{source|{{w|Jean-Baptiste Charcot}}, ''Dans la mer du Groenland'', 1928}}
#* ''Partout elle avait trouvé bon '''accueil''', prompt assentiment, mais elle se propose d’aller plus outre.'' {{source|{{Citation/Jean Rogissart/Passantes d’Octobre/1958|}}}}
#* ''Notre hôte, absent au moment de notre arrivée, ne tarde pas à paraître et me fait l’'''accueil''' auquel je m'attendais de sa part.'' {{source|{{w|Frédéric Weisgerber}}, ''Trois mois de campagne au Maroc : étude géographique de la région parcourue'', Paris : Ernest Leroux, 1904, page 38}} Parsing MediaWiki
- Remove the MW tags from the title:
import mwparserfromhell
title = mwparserfromhell.parse(title)
s=title.strip_code().strip()
print(s)- We see that many non-interesting articles have a colon:
accueil
MediaWiki:Disclaimers
MediaWiki:Disclaimerpage
MediaWiki:Showhideminor
MediaWiki:Sitetitle
lire
encyclopédie
Discussion utilisateur:Romanito
Discussion utilisateur:Hippietrail
Utilisateur:Ryo
Utilisateur:Romanito
manga
Utilisateur:Ske
Utilisateur:Alno
Discussion utilisateur:Alno
Discussion utilisateur:Koxinga/2004-2008
ouvrage- So we can keep only interesting articles and look at the text:
import mwparserfromhell
title = mwparserfromhell.parse(title)
s=title.strip_code().strip()
if not ':' in s:
print("TITLE ",s)
wiki = mwparserfromhell.parse(text)
print(wiki)- Still a lot of MW information!
DEF lire
WW {{voir/lire}}
== {{langue|fr}} ==
=== {{S|étymologie}} ===
: ([[#fr-verb|Verbe]]) Du {{étyl|la|fr|mot=lego|dif=lĕgĕre|sens=''id.''}}, proprement « recueillir »
: ([[#fr-nom|Nom]]) De l’{{étyl|it|fr|mot=lira}}, du {{étyl|la|fr|libra}} (« [[livre]] », le poids).
=== {{S|verbe|fr}} ===
[[File:Reading Jane Eyre.jpg|thumb|Jeune fille qui '''lit'''. (1)]]
[[File:USMC-120302-M-PG598-001.jpg|thumb|Une adulte '''lit''' une histoire à un groupe d'enfants. (6)]]
'''lire''' {{pron|liʁ|fr}} {{conjugaison|fr}} {{conjugaison|fr|grp=3}}
# [[interpréter|Interpréter]] des [[information]]s écrites sous forme de [[mot]]s ou de [[dessin]]s sur un [[suppo
rt]].
#* ''On '''lit''' ce livre absolument comme au bord de la cascade on entendrait, rêveur, le gazouillement des eaux
.'' {{source|{{w|Jules Michelet}}, ''Du prêtre, de la femme, de la famille'', 3{{e}} éd., Hachette & Paulin, 1845
, page 133}} - No easy way to remove all MW metadata:
- Install locally a MediaWiki server, or
- Read the MW doc and implement a “small” parser for a subset of the MW format
- Try to guess the role of some MW tags and quickly write a few rules to get what you want
- To extract the etymology (from the “étyl” tag):
import re
import mwparserfromhell
etyl = re.compile(r'{{étyl\|([^\|]*)\|[^\|]*\|([^\|}]*)[^}]*}}')
def handleWikiMedia(title,text):
title = mwparserfromhell.parse(title)
s=title.strip_code().strip()
if not ':' in s:
print("DEF "+s)
wiki = mwparserfromhell.parse(text)
for l in str(wiki).split('\n'):
l = l.strip()
if l.startswith(':'):
l = etyl.sub("(\g<1>) \"\g<2>\"",l)
s=l[1:]
ss = mwparserfromhell.parse(s)
s = ss.strip_code(normalize=True, collapse=True, keep_template_params=False).strip()
if len(s)>0: print(" "+s)
print()
class WikiXmlHandler(xml.sax.handler.ContentHandler):
def __init__(self):
xml.sax.handler.ContentHandler.__init__(self)
self._buffer = None
self._values = {}
self._current_tag = None
def characters(self, content):
"""Characters between opening and closing tags"""
if self._current_tag:
self._buffer.append(content)
def startElement(self, name, attrs):
"""Opening tag of element"""
if name in ('title', 'text'):
self._current_tag = name
self._buffer = []
def endElement(self, name):
"""Closing tag of element"""
if name == self._current_tag:
self._values[name] = ' '.join(self._buffer)
if name == 'page':
# print(self._values['title'], self._values['text'])
handleWikiMedia(self._values['title'], self._values['text'])DEF lire
(Verbe) Du (la) "mot=lego", proprement « recueillir »
(Nom) De l’(it) "mot=lira", du (la) "libra" (« livre », le poids).
Du (la) "mot=lyra".
DEF encyclopédie
Du (la) "encyclopaedia" forgé à la Renaissance sur la base du (grc) "ἐγκύκλιος" — voir — et soit le sens de «
ensemble de toutes les sciences ».
DEF manga
Du (ja) "漫画".
Le mot manga a aussi été considéré comme féminin, mais l’usage tend à préférer le masculin.
Du (ja) "漫画".
(Nom commun 1) Du (la) "manica".
(Nom commun 2) Du (ja) "漫画".
Du (ja) "漫画".
Du (la) "manica".
(Nom commun 1) Du (la) "manica".
(Nom commun 2) Du (ms) "mangga".
Du (ja) "漫画".
DEF ouvrage
Dérivé de ouvrer, ancienne forme de œuvrer, avec le suffixe -age.
Par dérive populaire puis effet stylistique, on peut rencontrer le genre féminin.
C’est de la belle ouvrage.- In the previous code, all WikiMedia “templates” are removed, except the “etymology” template.
- A better quality may be obtained by installing a local instance of WikiMedia and extracting all definitions with calls to local API.
Wrap-up
- Several ways to extract words definitions:
- Scripts: fast, but very approximate
- Using Wikipedia API: does not scale
- Using preprocessed JSON files: not up-to-date
- From XML dumps: a bit tricky
- From local API: complex and costly
Hands-on
- Check on your laptop that the code above is running fine and that it does extract a list of word+etymology
- There are still a number of mistakes: try and improve the code to fix some of them
- how long would it take, in your laptop, to extract all definitions from the French Wiktionary ?
N-grams
Unigrams
- Raw counts depend on the size of the data
- Normalized, give 1-gram:
\[P(w) = \frac {N(w)} {N(*)}\]
- Probability that a word occur in the language
Bigrams
- Count the sequences \(N(a,b)\)
- Divides by all sequences \(N(a,*)\)
- 2-gram gives probability that b follows a:
\[P(b|a) = \frac {N(a,b)} {N(a,*)}\]
Note:
\[P(b|a) = \frac {P(a,b)}{P(a)} = \frac{\frac{N(a,b)}{N(*,*)}}{\frac{N(a)}{N(*)}}\]
N-grams
- Generalisation to a sequence of length \(n\)
\[P(w_t|w_{t-n+1},\dots,w_{t-1}) = \frac{N(w_{t-n+1},\dots,w_{t-1},w_t)}{N(w_{t-n+1},\dots,w_{t-1},*)}\]
We’ll use N-grams for:
- diachronic analysis
- extracting collocations
- …
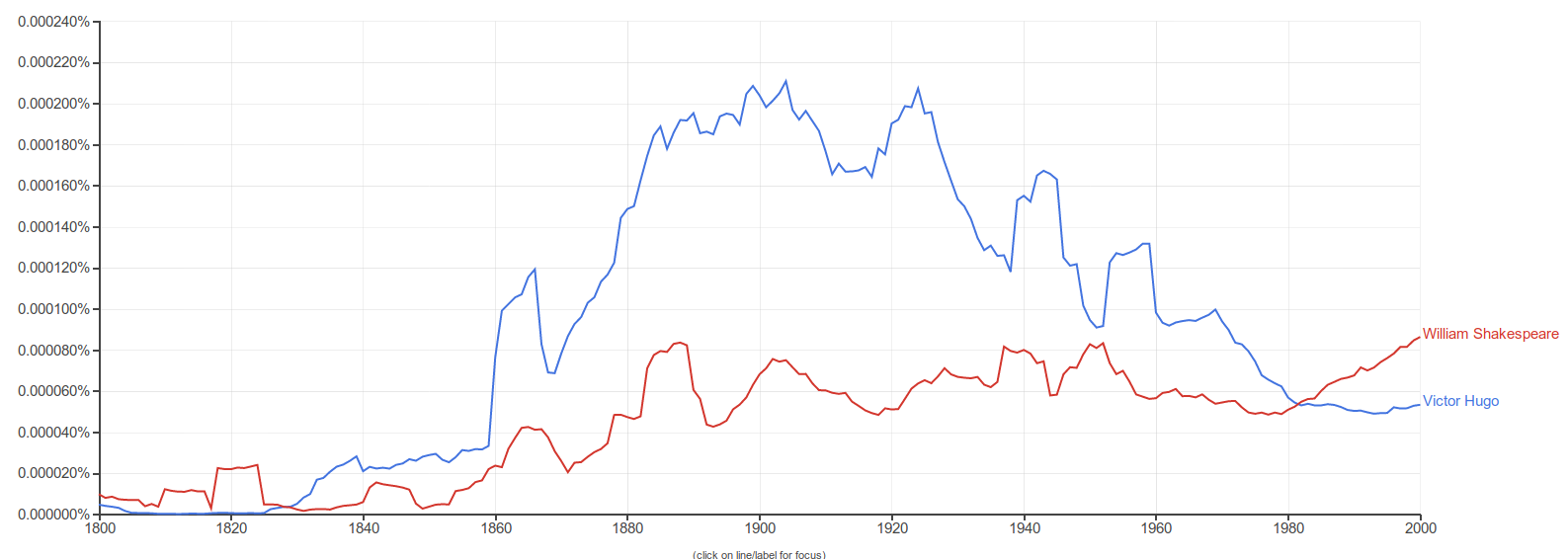
Training N-grams
- Easy to train:
- accumulate counts
- can be done online
- The most difficult is to scrap & pre-process texts, so:
- Google N-grams: https://books.google.com/ngrams
- Trained on 1,000G-tokens https://ai.googleblog.com/2006/08/all-our-n-gram-are-belong-to-you.html
- Free (trained on 430M-words) https://www.ngrams.info/
Rare/unseen sequences
- Sol 1: N-gram smoothing
- Add pseudo-count for every possible sequence
\[P(w_t|w_{t-n+1},\dots,w_{t-1}) = \frac{1+N(w_{t-n+1},\dots,w_{t-1},w_t)}{\sum_x \left( 1+ N(w_{t-n+1},\dots,w_{t-1},x) \right)}\]
- Other smoothings Good Turing, Kneser-Ney…
- Problem: all unseen sequences have the same probability
- Smoothing may be used in conjonction with backoff:
- linear interpolation: \[\hat P(w_t|w_{t-n+1},\dots,w_{t-1}) = \lambda P(w_t|w_{t-n+1},\dots,w_{t-1}) + \] \[(1-\lambda) P(w_t|w_{t-n+2},\dots,w_{t-1})\]
- Other backoffs: Katz…
- Sol 2: N-grams of sub-words
- Character n-grams
- Good for agglutinative languages…
- Capture common prefixes, suffixes…
- Very good at language detection
- Handle proper names
- Robust to typographic mistakes
- But requires much more data than words n-grams !
- Often combined with words n-grams
- Character n-grams
Limitations
- Number of potential n-grams increase exponentially
- Longer n-grams become very sparse:
- bad statistics
- cannot capture long dependencies
- In practice: maximum 5-grams