Transformers
Inductive bias and attention
- CNN: local weighting based on positions
- RNN: info cumulates, oldest are forgotten
- Semantic structure may go farther in the past!
- CNN: the context is weighted by positions
- RNN: most recent context is the most important
- Attention: context is weighted by content
- 2014: Bahdanau attention
- 2018: “attention is all your need”
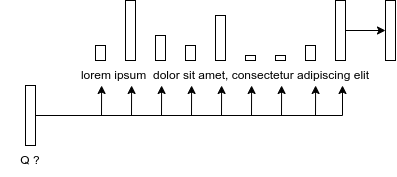
- Concepts of Query / Key / Value
- inspired by retrieval systems: ex. google search
- query = what you type in the search bar
- keys = indexes of web pages stored by google
- values = results you get
- QKV in sentences?
- ex. translation FR to EN:
- Q = repr. of the current target EN word being translated
- K = repr. of each FR input word
- V = repr. of each FR word in EN
- ex. self-attention:
- Q = repr. of the target word we want to contextualize
- K = repr. of all words in the sentence
- V = repr. of the useful context from each word
- QKV concretely:
- Each word in the voc is equipped with a static embedding \(X\)
- A \(W_Q\) matrix transforms every \(X\) into a query: \(Q = W_Q X\)
- A \(W_K\) matrix transforms every \(X\) into a key: \(K = W_K X\)
- A \(W_V\) matrix transforms every \(X\) into a value: \(V = W_V X\)
- the similarity btw \(Q\) anv \(V\) is computed with dot product
- sentence structures are hierarchic
- a single step of attention is not enough
- transformer = stack of self-attention layers
- “transformer” because transforms input embeddings into contextual
embeddings
- training: store info about preferred relations
- Solve limitations of previous models
- No bottleneck of information (as in ConvNet, RNN, seq2seq…)
- No preference for “recent tokens” (as in RNN)
- No constraints of locality (as in CNN)
Desirable properties
- Can scale
- more layers => capture more information
- Can “absorb” huge datasets
- store information == same as database?
- Can “compress” information
- much better than database!
- Transformers progressively replaced other models in many modalites:
- Image: token = small piece of image
- Audio: token = small segment of sound
- Video, code, DNA…

- Language models: a special place
- “Absorb” the written web == all human knowledge
- by far the largest transformers
- 2021: Wu Dao 2.0: 1.75 trillion parameters
- Central wrt other modalities (e.g., CLIP)
- How to try these models:
Transformers store knowledge
- “Give me a recipe to cook bacon”
- “place the bacon in a large skillet and cook over medium heat until crisp.”
- “The main characters in Shakespeare’s play Richard III are”
- “Richard of Gloucester, his brother Edward, and his nephew, John of Gaunt”
Transformers reason?
- “On a shelf, there are five books: a gray book, a red book, a purple
book, a blue book, and a black book. The red book is to the right of the
gray book. The black book is to the left of the blue book. The blue book
is to the left of the gray book. The purple book is the second from the
right. Which book is the leftmost book?”
- “The black book”
Self-attention
- For each target word:
- Compute its dot-product with every word
- Normalize them all with softmax
- Replace its vector by the weighted average of all words
- Let \(X_i\) be the vector of word \(i\)
- Let’s consider target word \(u=X_q\)
- For every word \(v=X_{k}\):
- compute \(a_k = u \cdot v\)
- Normalize the attention vector: \[\alpha = Softmax(a_1,\cdots,a_N) = \left[ \frac{e^{a_i}}{\sum_j e^{a_j}} \right]_i\]
- Often represented by a heat map over the words of the sentence

- We give each word a different representation when target and when key
- Consider all possible “target” words: \(Q\) and \(K\) are matrices:
- \(Q=[q_{w_1},\dots,q_{w_N}]^T\)
\[\alpha = Softmax(QK^T)\]
- \(q\) and \(k\) are \(d_k\)-dimensional vectors
- assume \(q_i\) has mean 0 and var 1, \(k\) constant
- then \(q\cdot k\) has var \(d_k\) (var of sum = sum of vars)
- so we scale the dot-product to get var=1: \(var(\frac{q\cdot k}{\sqrt{d_k}}) = d_k var(\frac{q}{\sqrt{d_k}})\) \(var(\frac{q}{\sqrt{d_k}}) = E[\frac{q^2}{d_k}] - E[\frac{q}{\sqrt{d_k}}]^2 = \frac 1 {d_k} (E[q^2]-E[q]^2) = \frac 1 {d_k} var(q)\)
- Pulling vectors together into a matrix for the whole sentence:
\[ \left[ \begin{array}{ccc} - & q_1 & - \\ - & \vdots & - \\ - & q_T & - \\ \end{array} \right] \left[ \begin{array}{ccc} | & \cdots & | \\ k_1 & \cdots & k_T \\ | & \cdots & | \\ \end{array} \right] \]
\[\alpha = Softmax\left( \frac{QK^T}{\sqrt{d_k}} \right) \]
We give each word a repr \(V_{w}\)
Pool them into a matrix for the sentence: \(V = [V_{w_1},\dots,V_{w_N}]^T\)
We replace every target word repr by the average over its context (weighted by \(\alpha\))
\[ X' = Softmax\left( \frac{QK^T}{\sqrt{d_k}} \right) V\]
- Caution about the matrices dimensions !
- Compute each repr \(Q\), \(K\) and \(V\) from the word embedding through a different MLP
- Repeat with different MLPs to get multiple heads
![]()
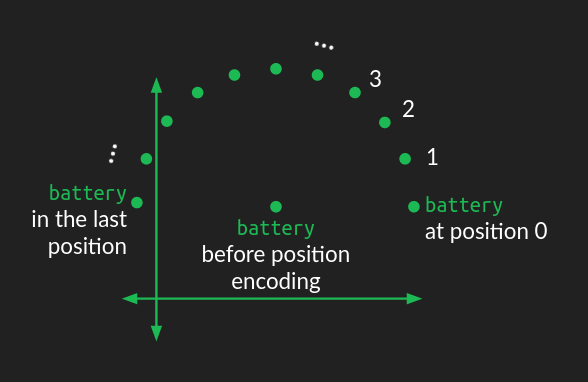
Positional Encodings
- Self-attention gives the same repr when you shuffle the words !
- Inject information about position through a vector that encodes the position of each word
- Naive approaches:
- \(p=1,\dots,N\): not normalized + never seen N
- \(p=0,0.06,\dots,1\): \(\Delta p\) depends on sentence length
- Better approach:
- inspired by spectral analysis
- positions are encoded along sinusoidal cycles of various frequencies
\[p_t^{(i)} = \begin{cases} sin(w_k \cdot t), \text{if }i=2k \\ cos(w_k \cdot t), \text{if }i=2k+1 \end{cases}\]
with \(d\) encoding dim and
\[w_k = \frac 1 {10000^{2k/d}}\]
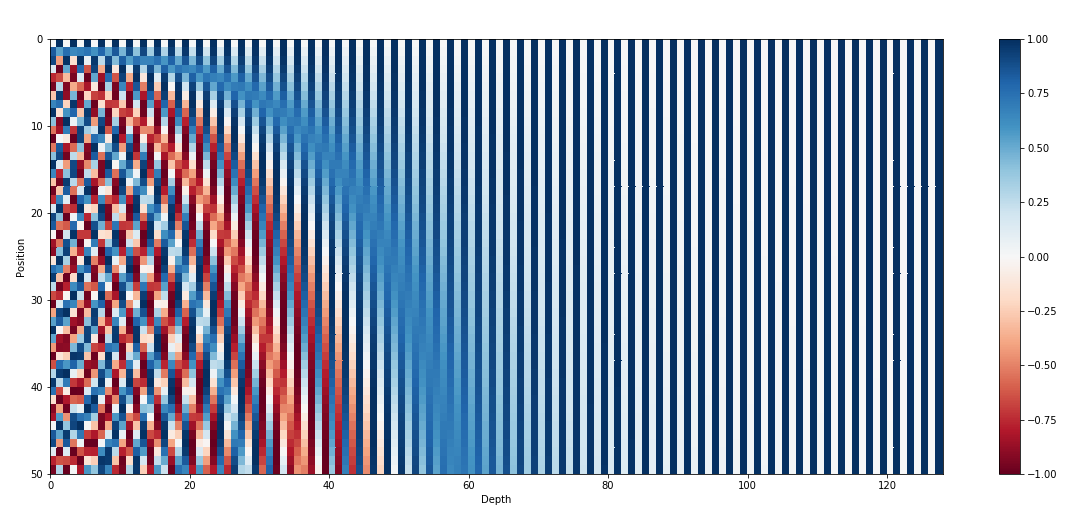
- Remarks:
- by giving positional encodings the same dimension as word embeddings, we can sum them together
- most positional information is encoded in the first dimensions, so summing them with word embeddings enable the model to “let” the first dimensions free of semantics and dedicate them to positions.
![]()
Details of the stack
- Add a normalization after self-attention
- parametric center+scale 1 vec across dimensions
- keep gradient small (cf arxiv.org/pdf/2002.04745)
- Add another MLP to transform the output
- Add residual connections: smooth loss landscape
![]()
- Stack this block \(N\) times
- not so much about abstraction
- about redundancy
- about having multiple/concurrent circuits
- The transformer is designed for Seq2Seq
- So it contains both an encoder and decoder
- Same approach for decoder
- with cross-attention from encoder to decoder matching layers
- with masks to prevent decoder from looking at words \(t+1, t+2\dots\) when predicting \(t\)
- GPT family: only the decoder stack
- BERT family: only the encoder stack (+ classifier on top)
- T5, BART family: enc-dec
- Implementation details of the transformer:
- great resource:
- see The annotated transformer
Pretraining
Principle:
- Train model on very large textual datasets
- With a task that forces them to:
- model how words are formed, tokenized
- capture syntactic/semantic/coref relations
- remember facts stated before
Which tasks ?
- predict next token (GPT)
- predict masked token (BERT)
- next sentence prediction (BERT)
- denoising texts (BART)
- pool of “standard” NLP tasks (T5, T0pp):
- NLI, sentiment, MT, summarization, QA…
Multilingual models:
- XLM-R
- paper
- trained on 100 languages
- Bloom, M-BERT, M-GPT…
Next token prediction
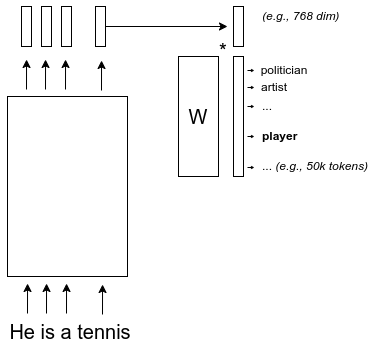
Training steps:
- Compute prediction error:
- cross-entropy
- set the gradient of the error at the output = 1
- Backprop gradient of the error in the model
- Update every parameter to reduce the final error
- Iterate to the next token, etc.
Key ingredients to success:
- The prediction task is forcing the model to learn every linguistic level
- The model must be able to attend long sequences
- Impossible with ngrams
- The model must have enough parameters
- Impossible without modern hardware
- The model must support a wide range of functions
- Impossible before neural networks
- The data source must be huge
Exploiting
- With Zero-Shot learning
- With few-shot learning
- As frozen embeddings
- With fine-tuning
- With prompt tuning
- With Zero-label Unsupervised Data Generation
- …
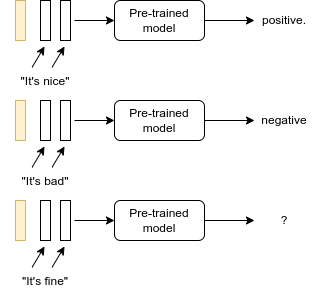
Zero-Shot Learning (teaser)
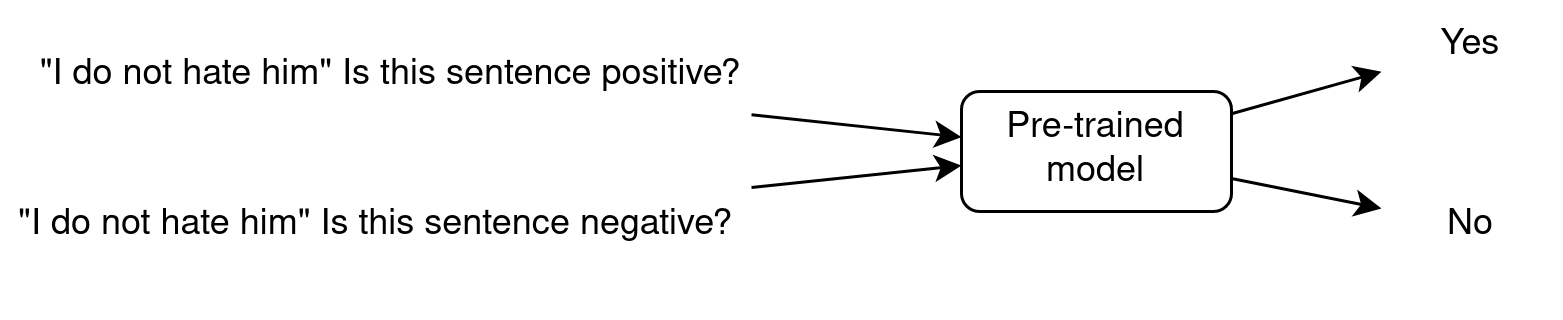
- Zero-Shot because the LLM has been trained on task A (next word prediction) and is used on task B (sentiment analysis) without showing it any example.
In-context Few-Shot Learning
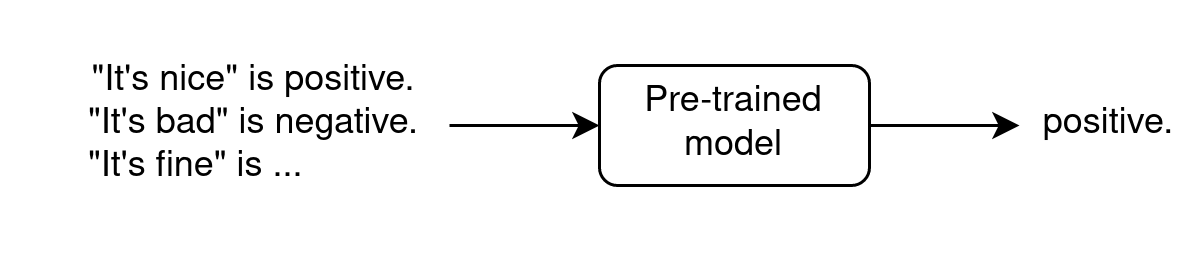
- requires very few annotated data
- In context because examples are shown as input
- does not modify parameters
- see paper “Towards Zero-Label Language Learning” (GoogleAI, sep 2021)
As frozen embeddings
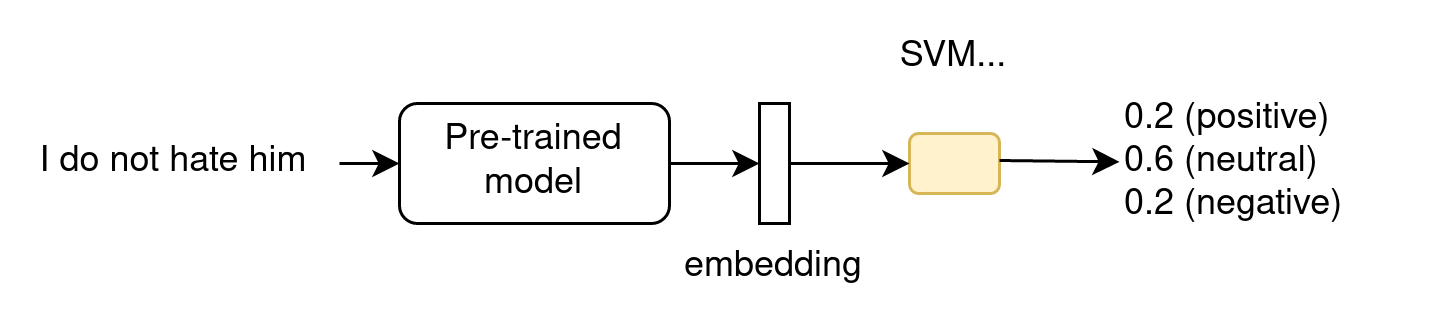
- does not modify the LLM parameters
- for ML-devs, as the LLM is part of a larger ML architecture
With fine-tuning
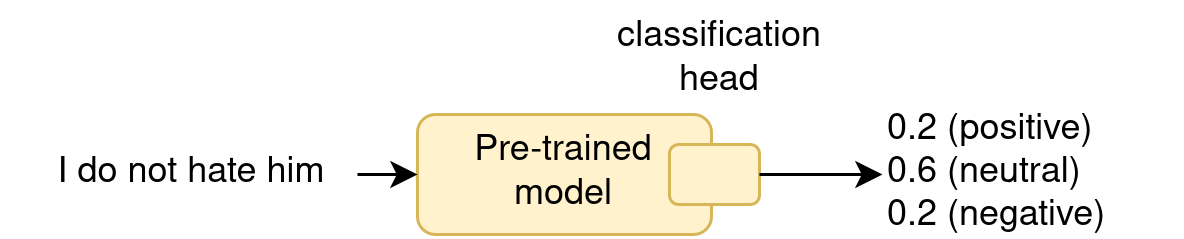
- == “continued pretraining” on target data
- does modify the LLM parameters !
- often give the best results
- Warning with Fine-tuning:
- the resulting model gets specialized
- forgetting: lose its previous knowledge
- overfitting: cannot generalize any more
- Solutions:
- regularization, adapters, rehearsal…
With prompt-tuning
Zero-label Unsupervised Data Generation
- Generate synthetic samples with few-shot (just task desc. and samples, no labels, plus ask for sample for given label)
- Finetune a model on this dataset
Manual prompting
- When used in ZSL, we want the model to perform a given task with a given input
- Ex: “translate the following sentence in French: the weather is nice”
- “translate the following sentence in French” == prompt
- “the weather is nice” == input
Designing a good prompt is an art:
“Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy”
- “Positive”
“A is the son’s of B’s uncle. What is the family relationship between A and B?”
- “cousins”
“A is the son’s of B’s uncle. What is B for A?”
- “brother”
- A good prompt:
- makes the model focus on a specific task/request
- gives contextual information
- enables to control the output
- ex: “summarize the previous text with simple language so that five-years old children may understand it”
Prompt programming
- is the art of designing prompt to perform a task
- Prompting may be viewed as a way to constraint the generation
- You may describe the task
- You may give examples (in-context few-shots)
- You may give an imaginary context to “style” the result
- How to describe the task:
- direct task description
- proxy task description
- Direct task description:
- “translate French to English”
- Can be contextual:
- “French: … English: …”
- Direct description can combine tasks the model must know:
- “rephrase this paragraph so that a 2nd grade can understand it, emphasizing real-world applications”
- Proxy task description
This is a novel written in the style of J.R.R. Tolkien’s Lord of the Rings fantasy novel trilogy. It is a parody of the following passage:
“S. Jane Morland was born in Shoreditch …”
Tolkien rewrote the previous passage in a high-fantasy style, keeping the same meaning but making it sound like he wrote it as a fantasy; his parody follows:
- Few-shot prompts:
English: Writing about language models is fun. Roish: Writingro aboutro languagero modelsro isro funro. English: The weather is lovely! Roish:
- “chain of thoughts”:
- decompose a difficult task into steps
- only works with large models (>100GB)
- Applied to solve 2nd grade math problems
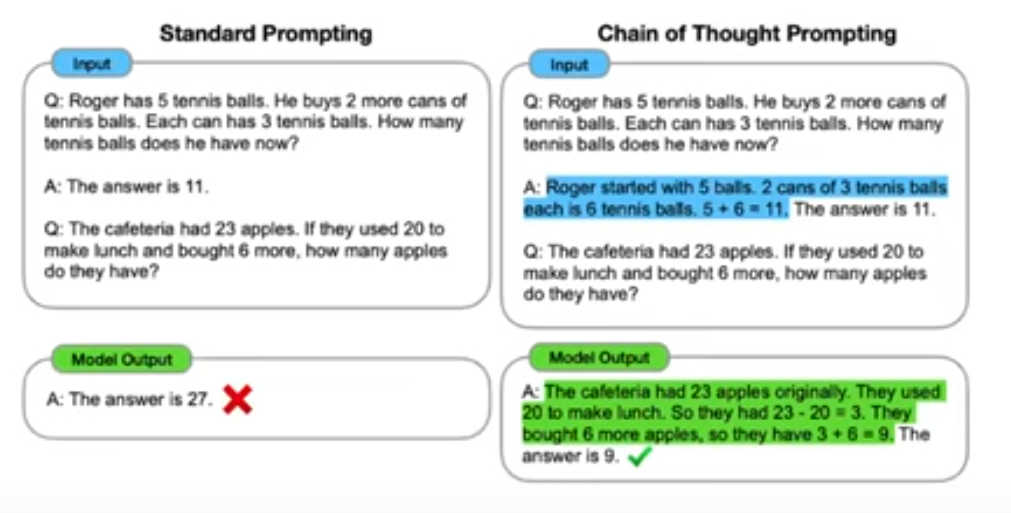
CoT requires large models:
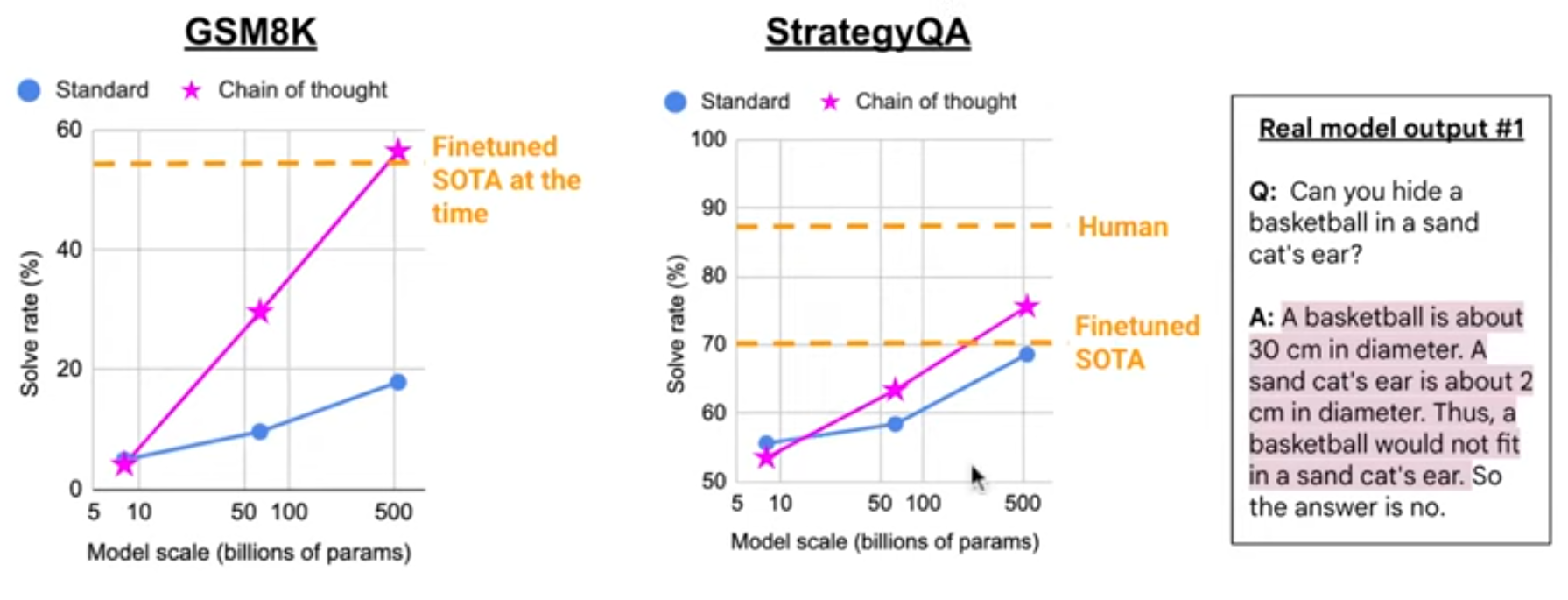
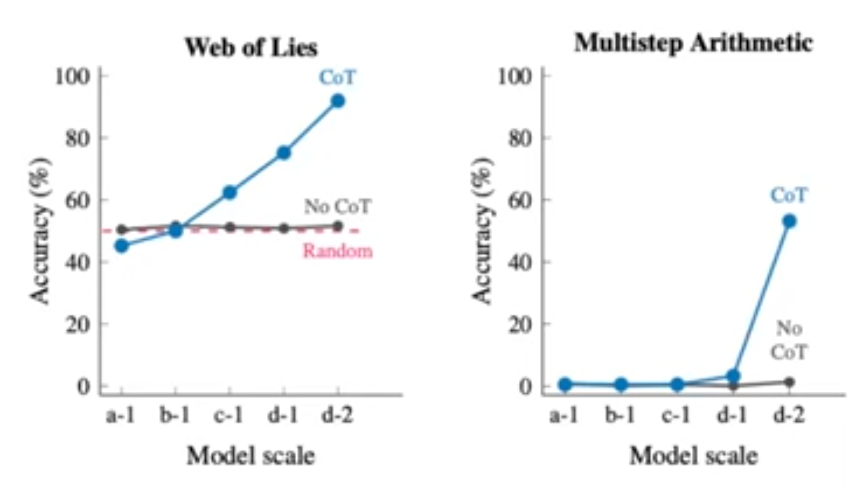
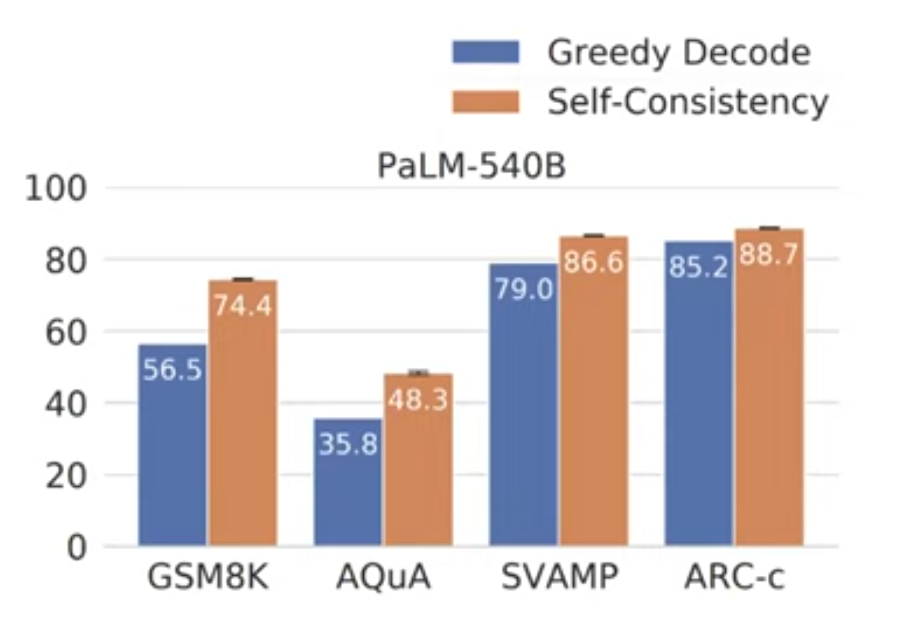
- Self-consistency greatly improves CoT prompting
- For one (CoT prompts, question) input, sample multiple outputs
- take majority vote among outputs
Analogy solving:
Directions: In the following question, a related pair of
words or phrases is followed by five pairs of words or
phrases. Choose the pair that best expresses a relationship
similar to that in the original pair.
braggart :: modesty
A) fledgling : experience
B) embezzler : greed
C) wallflower : timidity
D) invalid : malady
E) candidate : ambition
To solve this problem, first we need to understand the
relationship that exists between braggart and modesty.
According to the sentence, 'braggart' is a person who talks
too much about himself or herself and is usually not
believed. On the other hand, 'modesty' is the opposite of
this and denotes a person who does not talk too much about
himself or herself. Thus, for 'modesty' to be a suitable
answer, it should show the opposite of 'braggart'.
Now let's see whether each pair expresses a relationship
similar to that between braggart and modesty.
Next we have 'fledgling', which means a person who is
inexperienced and 'experience' which means knowledge gained
through practical involvement. Thus, 'fledgling' is a person
who has no experience and 'experience' is knowledge gained
through practical involvement. Thus, 'fledgling' is the
opposite of 'experience'. The relationship between these two
words is similar to that between braggart and modesty, hence
'fledgling' is the answer.- Going further:
Scaling law for transformers
Open-source LLM community
More and more specialized:
- Foundation: Meta, Eleuther, LightOn, Mistral…
- Prompting: CoT, PoT, AoT…
- Finetuners: 80k models on Hugginface-hub
- Integration: LangChain, Coala…
- academics: why does it work so well?
LLM: a new empirical research

From observations to embryos of theories
- Observations:
- Memorisation, compression, structuration and generalisation
- Emergent capabilities
- Embryos of théories: scaling laws
- Chinchilla scaling laws
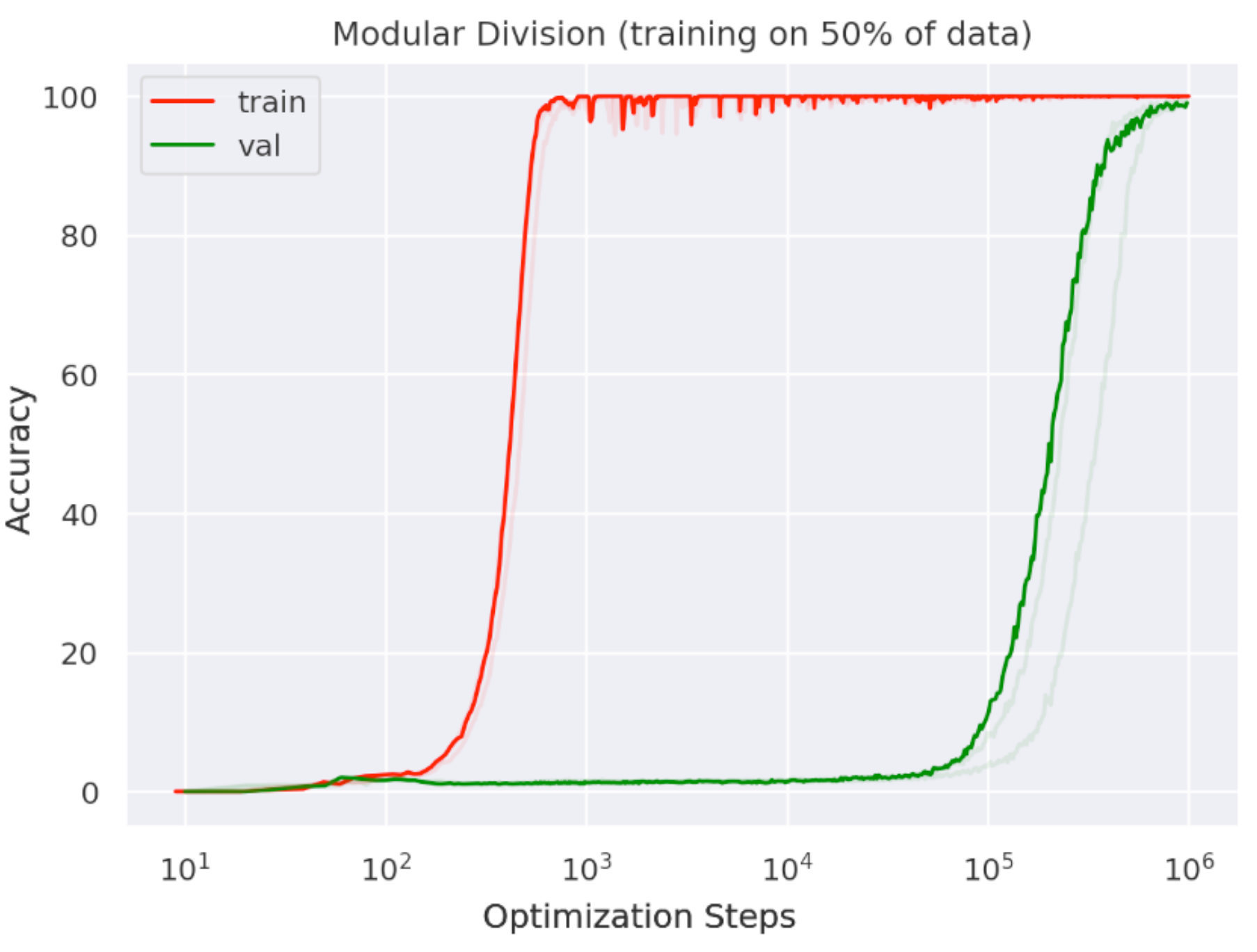
- Grokking
- Double descente
- Phase transitions, singularity…
Scaling laws: birth of Chinchilla

LLM: models that scale
- The more data is added,
- the more the LLM store information
- the better it generalizes
- scaling law = power law = \(y(x) = ax^{-\gamma} +b\)
- \(y(x) =\) test loss (erreur)
- \(\gamma\) = slope
Baidu paper 2017
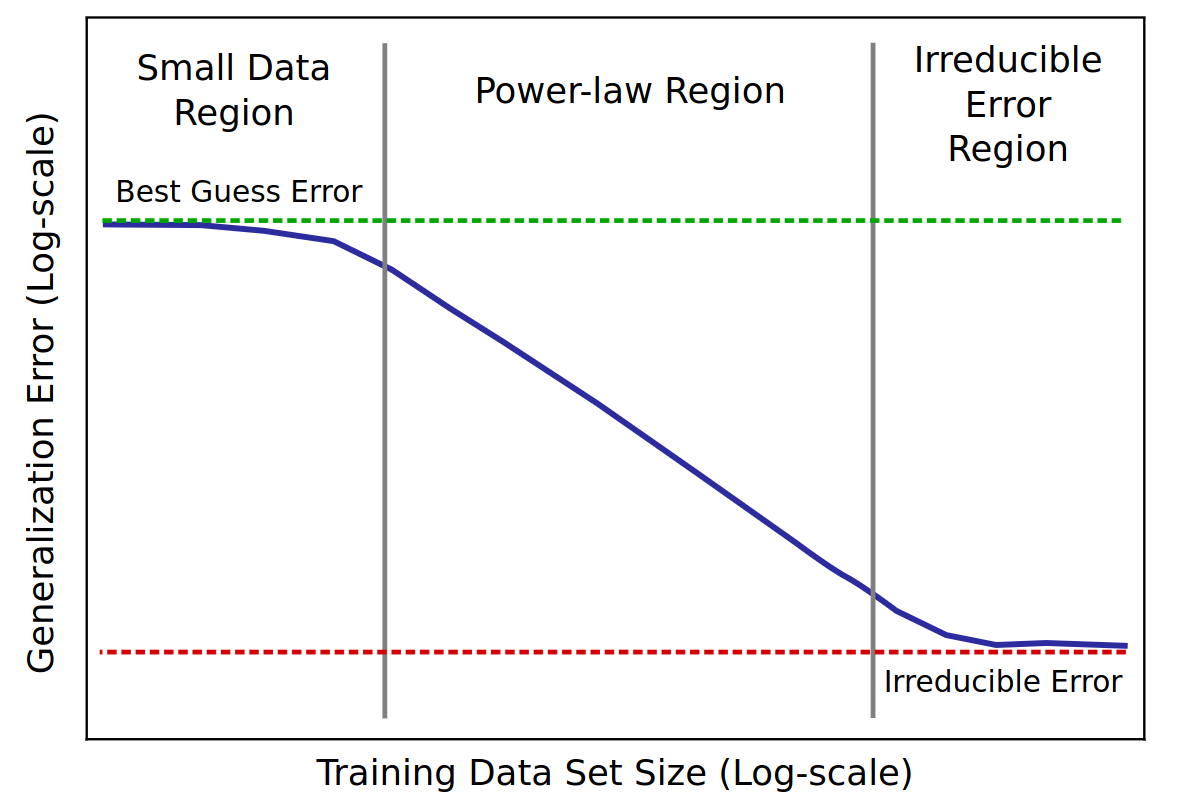
Scaling laws for Neural LM 2020
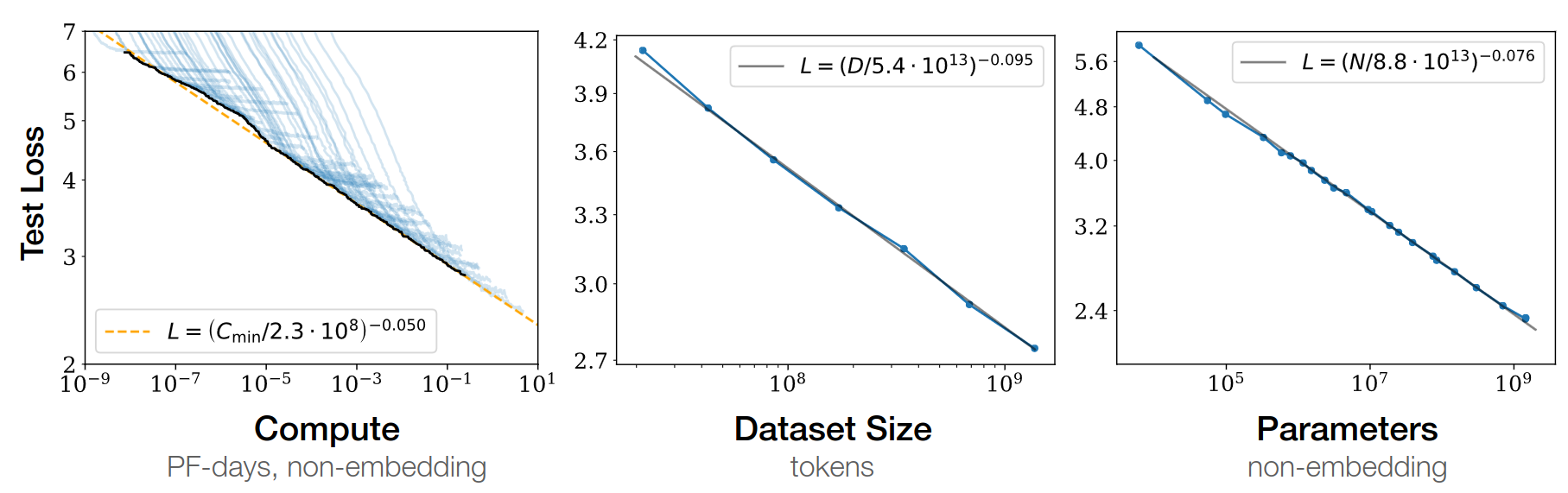
Open-AI 2020
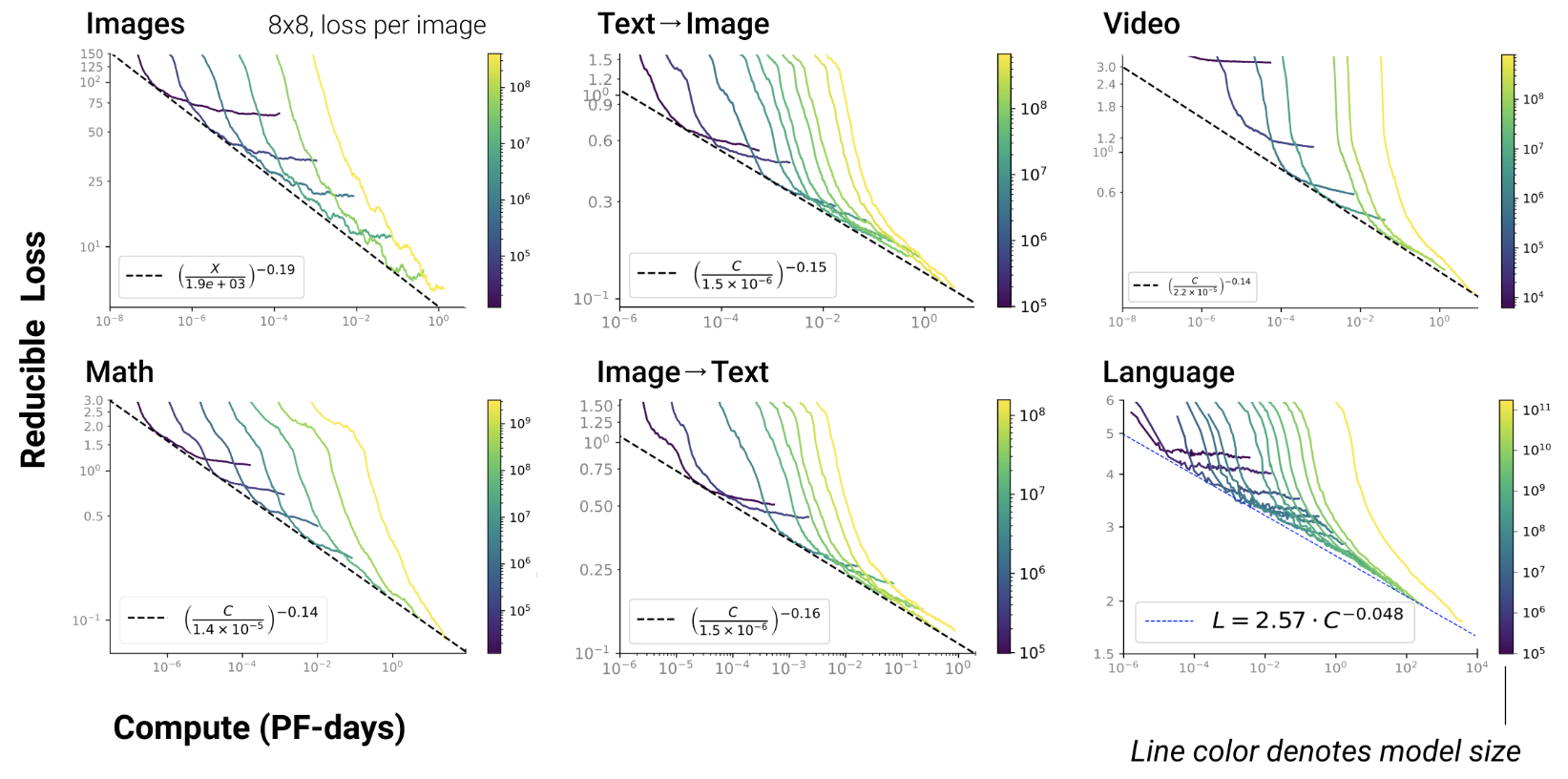
- RL, protein, chemistry…
Chinchilla paper 2022
- GPT3 2020: inc. model capacity
- Chinchilla 2022: inc. data

\(L=\) pretraining loss


Google 2022: paper1, paper2 Flops, Upstream (pretraining), Downstream (acc on 17 tasks), Params
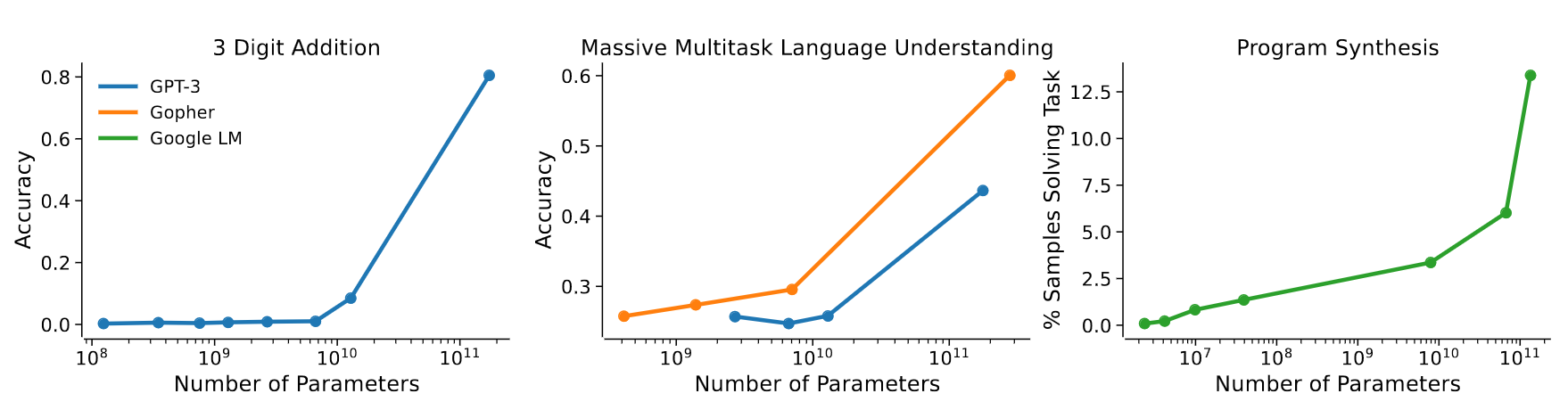
Emergence of new capabilities
- Scaling laws exist in ML since a long time (cf. Paper on learning curves)
- But it’s the first time a scaling law is observed as a consequence of emerging capabilities!
GPT3 paper 2020
- emergence of “In-Context Learning”
- = enable to generalize from provided examples
- example:
"manger" devient "mangera"
"parler" devient "parlera"
"voter" devientAnthropic paper 2022
- show that scaling laws result from the combination of emerging capabilities
Jason discovered 137 emerging capabilities:

- In-Context Learning, Chain-of-thought prompting
- PoT, AoT, Analogical prompting
- procedural instructions, anagrams
- modular arithmetic, simple maths problems
- logical deduction, analytical deduction
- physical intuition, theory of mind?
- …
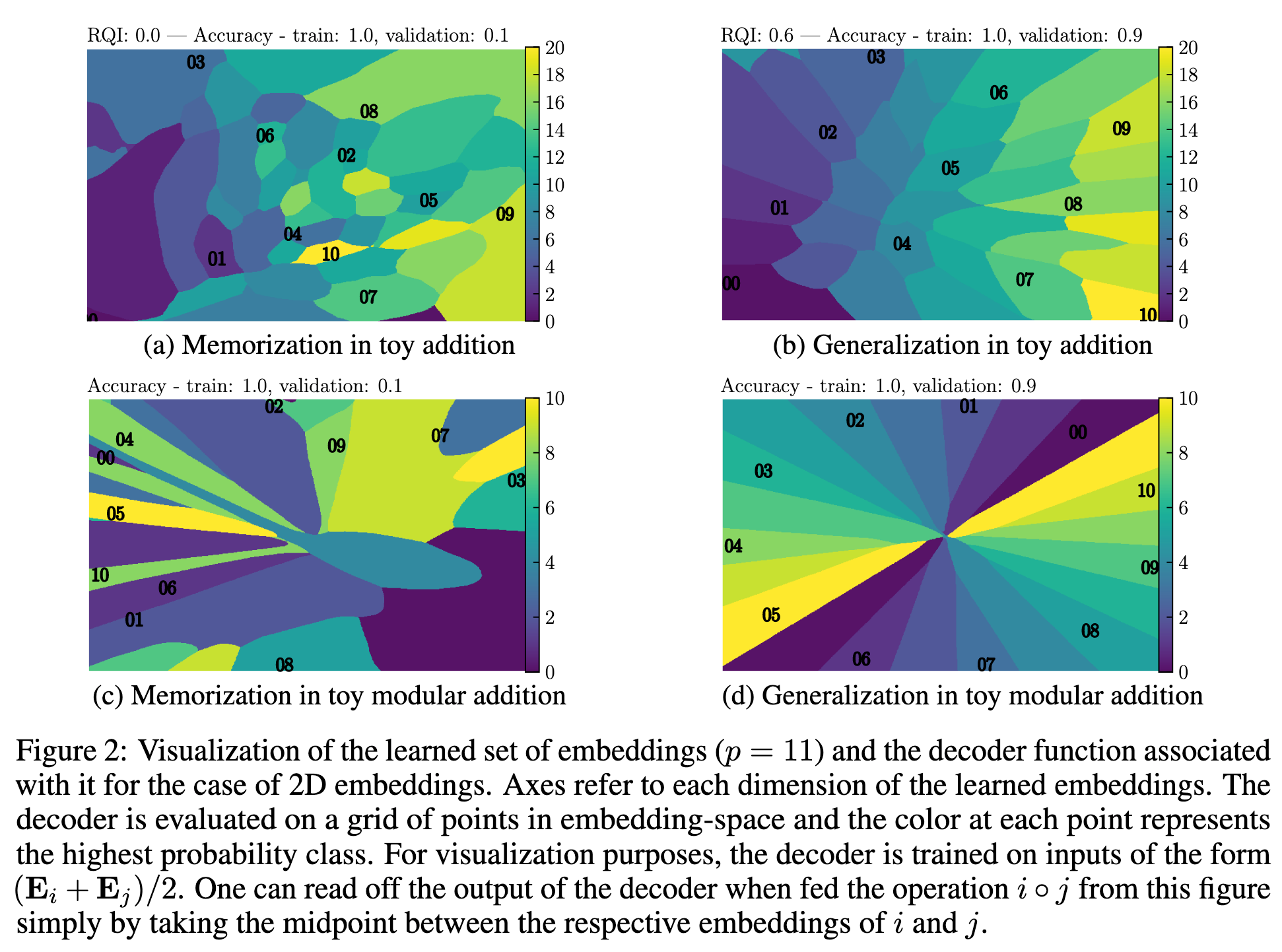
LLM organize information
During training, they may “abruptly” re-structure the latent representation space

Challenges
- Pre-training costs: Llama2-70b = $5M
- How to reduce these costs?
- Break the scaling laws!
- Hard to beat the transformer
- Cleaning data?
- Continual learning?
- Break the scaling laws!
Continual Learning
- Challenges:
- Catastrophic forgetting
- Evaluation: cf. realtime-QA
- Data drift towards LLM-generated texts (LIX)
- How to restart training?
Catastrophic forgetting

There’s some hope though…
- May be it’s just misaligned output embeds
- Growing networks are promising to mitigate forgetting GradMax, ICLR’22
- Growing models have good geometrical properties in the parameter space
Continual training
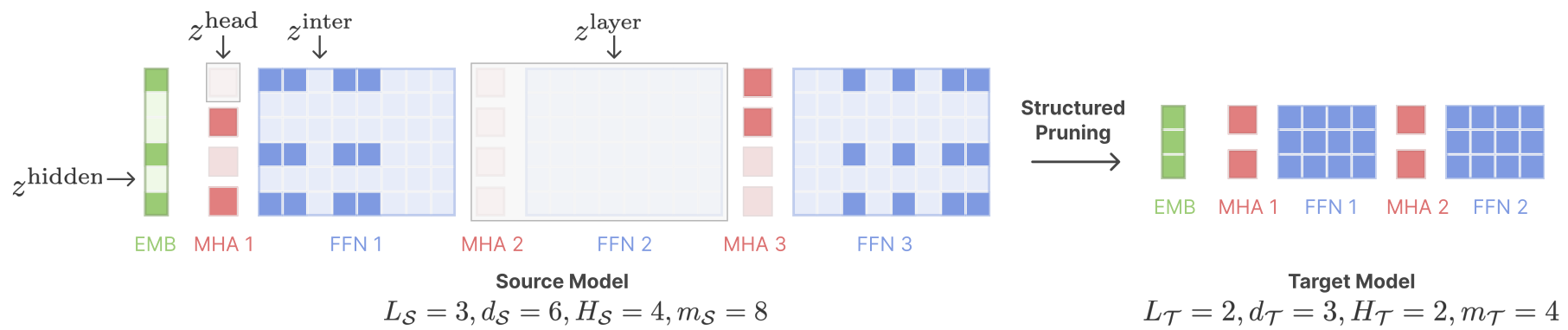
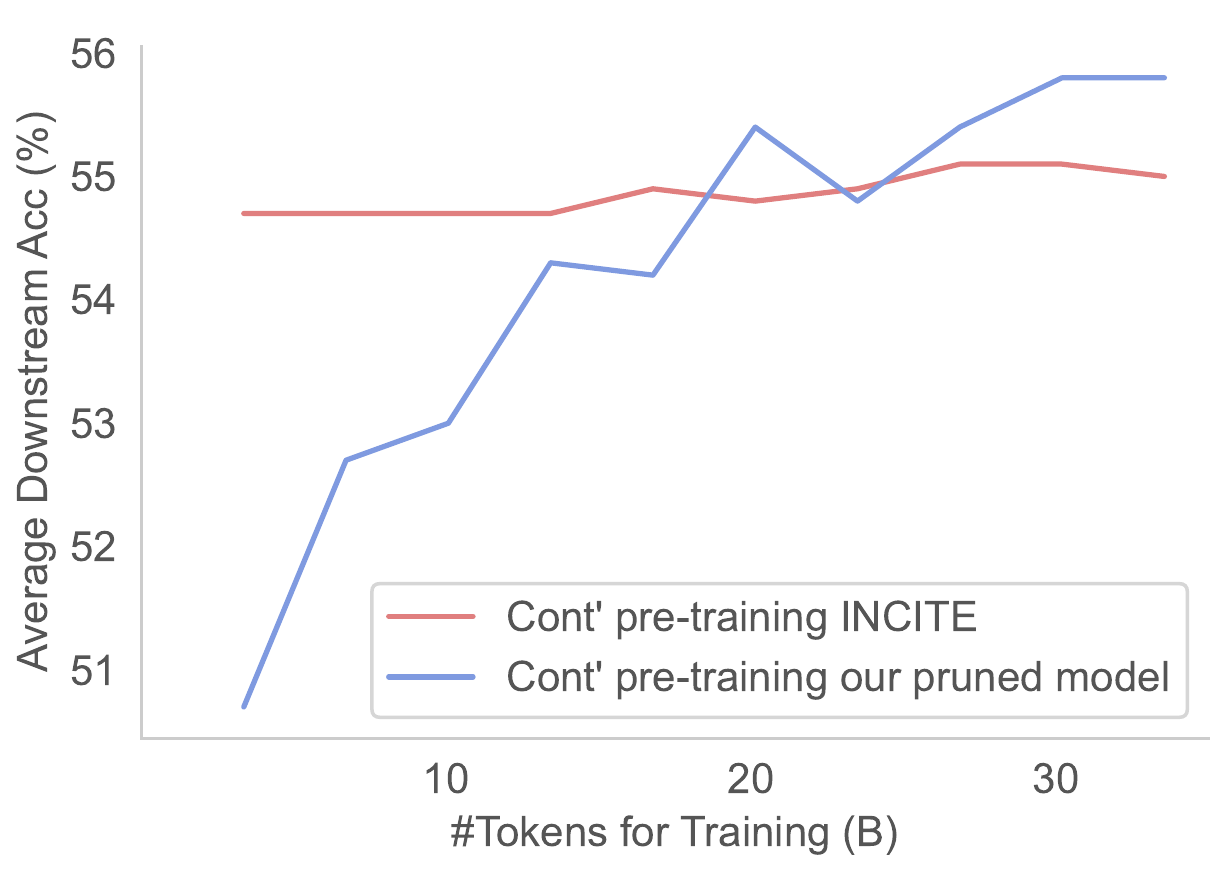
- Sheared Llama (Princeton, 2023)
- structured pruning + cont. training w/ batch weighting
- Sheared llama: resurgence of a scaling law w/ cont. training
Future challenges & carbon footprint
- Carbon footprint:
- many researches on reducing costs
- also on tackling climate change with AI
- Privacy:
- models remember facts (cf. Carlini)
- user modeling
- Capture & remember long-term context
- Limits of “pure text”: multimodal, grounded
Carbon footprint
- Costs of LLMs:
- training on GPU clusters
- usage requires powerful machines
- Many ways to reduce cost:
- algorithms improvement
- developing “heritage” (soft + hard)
- hardware improvement
- using LLM to reduce impact of other activies
- e.g., less bugs, shorten dev cycles, reduce waste…
- …
Algorithms improvement
- Fast progress:
- Training GPT3 costed 3M\$ in 2020, now “only” 150k\$
- Quantization
- reducing nb of bits per parameter
- standard: 32 (cpu), 16 & bf16 (gpu)
- quantized: 8, prospect: 4, 2, 1
- cf. bitsandbytes, ZeroQuant, SmoothQuant, LLM.int()…
- GLM-130B requires VRAM: 550GB (32b), 300GB(16b), 150GB (8b)
- Pruning
- Principle: remove some neurons and/or connections
- Example:
- remove all connections which weight is close to 0
- then finetune on target task, and iterate
- Hard to do on large LM
- Many pruning methods:
- data-free criteria:
- magnitude pruning
- data-driven criteria:
- movement pruning
- post-training pruning
- pruning with retraining
- structured pruning
- unstructured pruning (sparsity)
- …
- data-free criteria:
- distillation
- Principle: train a small student model to reproduce the outputs of a large teacher model
- Problems:
- Limited by the (usually) small corpus used: does it generalize well?
- Otherwise, very costly: why not training from scratch?
- Parameter-efficient finetuning:
- Principle: fine-tune only a small number of parameters
- Adapters
- Prompt tuning
- Train faster, in less epochs, with less FLOPs
- Exploit best practices:
- Layer Normalization stabilizes training
- Exploit scaling law:
- use accurate sizes, stop before convergence
- Train larger models then compress
- Progressive training
- Loss: UL2
Heritage & low-end computers
- offloading
- see deepspeed Zero
- see accelerate
- Collaborative training:
- TogetherComputer: GPT-JT
- PETALS & Hivemind
- Mixture of experts
- Challenge: privacy
- Models remember facts (cf. Carlini)
- Hard to solve ?
- Differential Privacy: impact usefulness
- Post-edit model
- find private info + delete it from model
- Pre-clean data
- Challenge: frugal AI
- Vision, Signal processing with small models
- Pruning, distillation, SAM, firefly NN…
- Impossible? in NLP
- Needs to store huge amount of information
- Federated model ?
- Continual learning ?
- Sub-model editing ? (“FROTE”)
- Capturing longer contexts
- model structured state spaces (Annotated S4 on github)
- Limit of text accessibility ?
- Grounding language: vision, haptic, games…
- Annotate other tasks with language:
- industrial data, maths proof…
References
Great pedagogical point of view about LLM by Sasha Rush: video
- Images from
- https://e2eml.school/transformers.html
- paper “Attention is all you need”
- Best blog ever about transformers
- Great talk on maths theory about transformers
- Great talk about ZSL
| Q001 | Q002 | Q003 | Q004 | Q005 | Q006 | Q007 | Q008 | Q009 | Q010 |
| 89% | 50% | 86% | 50% | 36% | 7% | 54% | 36% | 86% | 54% |
| Q011 | Q012 | Q013 | Q014 | Q015 | Q016 | Q017 | Q018 | Q019 | |
| 57% | 79% | 71% | 29% | 61% | 96% | 68% | 82% | 18% |
1 Which type of semantic representation scheme is WordNet? - shallow - logical + network-based
2 Which one is not a latent feature-based semantic representation? + one-hot embeddings - Random Indexing - LDA
3 Given a synset x, how do you find the gloss? + x.definition() - x.gloss() - x.lemmas()[0].gloss()
4 What do you need to inspect to get all synonyms of a word? + multiple lemmas in one or more synsets - multiple lemmas in one synset - multiple relations from one or more synsets
5 How does NLTK give access to relations from a synset? + through methods of a dedicated class - through global methods of the wordnet package with the synset passed as string argument
6 Which structure does the hypernym relation create? - a tree + a graph - a set
7 How can you know all relations accessible from synset x? + help(x) - type(x) - x.relations()
8 You want only nouns; which command is wrong? - wn.synsets("dry",pos=wn.NOUN) + [l for l in wn.synsets("dry") if type(l)==wn.NOUNS] - [l for l in wn.synsets("dry") if l.pos()=='n']
9 Which sentence is correct? - Every lemma in WordNet occurs in at least one example sentence - Every synset has at least one antonym + Every synset has at least one lemma
10 Which method gives you the hypernyms up to the most abstract synset in wordnet? - hypernyms() - root\_hypernyms() + hypernym\_paths()
11 Which relation is the most important one for adjectives in WordNet? - hypernyms - hyponyms + antonyms
12 Which pseudo-code compute all antonyms of a word w? + for x in synsets(w): for y in x.lemmas(): for z in y.antonyms(): accumulate z - for x in synsets(w): for y in x.antonyms(): accumulate y - for x in synsets(w): for y in x.antonyms(): for z in y.lemmas(): accumulate z
13 Does 'for s in wn.synsets()' give you all synsets in WordNet? + no - yes
14 How can you get all synsets with animals (and only them)? + with lexicographer files - by filtering the output of wn.all\_synsets() with synset animal attribute - by computing the transitive closure of "living being" through hyponym relation
15 x is a synset. When is x.min\_depth() == x.max\_depth()? + when len(x.hypernym\_paths())==1 - when len(x.hypernyms())==1 - when x.path\_similarity(x.root\_hypernyms()[0])==1
16 What does WordNet's lemma.count() method returns? - the percentage of occurrence of the lemma in English + the number of occurrences of the lemma in WordNet's examples - the number of relations between this lemma and others
17 Which expression is wrong? - wn.lemma('nice.a.01.nice').count() - wn.lemma('nice.a.01.nice').antonyms()[0].count() + wn.lemma('nice.a.01.nice').synset().count()
18 which synset corresponds to the definition: "conscientious activity intended to do or accomplish something" ? + attempt.n.01 - try.v.01 - undertake.v.01
19 (difficult) You want to get all hypernyms of synset x, up to the root of the hierarchy. Which method returns the largest number of elements? + flatten x.hypernym\_paths() and remove duplicates - compute the transitive closure with x.closure(lambda a: a.hypernyms())) - flatten x.root\_hypernyms() and remove duplicates