Organisation
If you didn’t received any personal correction, or missed any MCQ, send me an email now saying “I didn’t received any correction” or “I didn’t pass MCQ because…”
cerisara@loria.fr
| Q001 | Q002 | Q003 | Q004 | Q005 | Q006 | Q007 | Q008 | Q009 |
| 36% | 29% | 61% | 50% | 11% | 89% | 43% | 57% | 93% |
| Q010 | Q011 | Q012 | Q013 | Q014 | Q015 | Q016 | Q017 | Q018 |
| 32% | 86% | 46% | 82% | 57% | 25% | 21% | 79% | 32% |
1 * Which sentence is wrong? + The LLOD has proposed the RDF specifications - The LLOD is the largest subsection of the LOD - The LLOD promotes a cloud
2 * Which sentence is wrong? + URI make resources accessible - URI was previously known as UDI - An ISBN is an URI
3 *[horiz] Which standardization body has standardized RDF? + W3C - ISO - LOD
4 * If there is no license on a web page, it does imply: - that the text is free to use - by default, the CC0 (Creative Commons Zero) license + that you can not copy it on your website
5 *[horiz] Which organism standardized TEI? - W3C - CLARIN + ISO
6 *[horiz] Which format is better suited to represent phone-to-text alignment? - CoNLL + TextGrid - RDF
7 * The main role of a concept registry is to provide: - definitions of grammatical concepts + an URI for concepts - accessibility to TEI concept
8 * Which sentence is true: - LMF extends TEI to morphology, MWE, syntax... + TEI is more general than LMF - TEI requires references to a concept registry
9 *[horiz] Which repository mainly delivers free lexical resources: + ORTOLANG - ELRA - LDC
10 * Which sentence is true: - Some LLMs already capture all textual knowledge available on the internet + LLMs capture more and more internet texts, at a speed that is faster than the increase of textual content on the internet over time - LLMs capture more and more internet texts, but the amount of texts on the internet grows faster
11 * Which view in TEI best encodes syntactic relations? + lexical - typographic - editorial
12 * In the CLARIN network, the VLO enables to: + search in the available resources - compute statistics about the usage of each resource - observe and report on the evolution of lexical resources worldwide
13 * The CoNLL format is commonly used to encode: - abstract meaning representations + syntactic trees - common sense knowledge
14 *[horiz] Simple text files do not require intense preprocessing to extract a lexicon. - True! + False!
15 * Which one corresponds to a correct lexicon creation pipeline? - text format > tokenization > frequencies > ngram - text format > cleaning > lexicon extraction > ngram + text format > cleaning > ngram > frequencies
16 * Why XML to JSON conversion yields some challenges? - Due to the data hierarchy being different! + Because JSON files possess less information - Because XML can be parsed as YAML
17 * A lexicon cannot incorporate morphological rules. - True! + False!
18 * A lexeme is defined by its... - canonical form! - flexional form! + meaning!Semantic representations
Plan
- Intro on semantics representations
- WordNet
- FrameNet
The slides often give examples of code: start python right now on your laptop and try to run each command on your computer as they are given.
Semantics representations
- Semantic parsing = converting sentence into its meaning representation (Kate, ACL 2010 tutorial)
- what is Meaning = philosophical question…
- … we want it to do something useful for an application = procedural semantics
- There exists several Semantic Representation
Schemes
- See (Abend; Rappoport 2017)
- Several categories/views of SRS:
- Logical Semantic Representations
- formal representation language (lambda calculus)
- or grammars
- or rule-based transformations over syntactic structures
- Logical Semantic Representations
- Shallow Semantic Representations
- identifies entities in a sentence and assign them a role
- = slot-filling or frame-semantic parsing
- FrameNet, PropBank, UCCA, AMR…
- Formal MR:
- focus on logical relations
- mostly assume representations of words, entities… given
- Network-based representations
- network of semantic relations
- e.g. wordnet, conceptnet
- feature-based representations
- attribute-value pairs for objects or concepts
- latent feature-based representations
- vector representations
- LSA, W2V, BERT…
Ex: AMR
- Abstract Meaning Representation extends PropBank to DAG
- 1 DAG per sentence that represents named entities, coreference, semantic relations, temporal entities…
Ex: UCCA
- = cross-lingual semantic representation scheme
- English, French, German (Czech, Russian, Hebrew)
- Sentence semantics = DAG
- Leafs = tokens
- Non-leaf nodes = semantic units
- Edges = semantic roles
WordNet
WordNet
- Lexical database (nouns, adj, adverbs…)
- Each word is expressing its distinct concept
- Exist in more than 200 languages
- Used for semantic parsing, information retrieval…
- Focus on English wordnet:
- Synset = group of words share same concept
- gloss = definition of a synset
- Relations between synsets (hyponym…)
- Navigate the graph: http://wordnetweb.princeton.edu/perl/webwn
- More info, downloads: https://wordnet.princeton.edu/
Get a feeling of WordNet
“zoo” has only one sense, so one lemma, which belongs to the synset {menagerie, zoo, zoological garden}
Find the gloss of “zoo”
How many synsets are there for “WordNet” ?
What synonyms does the noun “table” have ?
WordNet in python
from nltk.corpus import wordnet as wn
zoo_synsets = wn.synsets("zoo")
len(zoo_synsets)WordNet objects in python
- Tips to identify/manipulate objects:
- When you get a synset, what is its type ? (set, list, … ?)
- Hint: 2 useful functions: type(), help()
Filtering by Part-Of-Speech
wn.synsets("try",pos=wn.NOUN)
wn.synsets("try",pos=wn.VERB)
wn.synsets("dry",pos=wn.NOUN)
wn.synsets("dry",pos=wn.VERB)
wn.synsets("dry",pos=wn.ADJ)Some synset functions
d1 = wn.synsets("dry",pos=wn.ADJ)[0]
d1.name()
d1.lemmas()
d1.definition()
d1.examples()Exercice:
- Using python, print definitions for all synsets of “dry”
- What python types do functions lemmas, definition and examples produce ?
Synset names
- Synsets are identified by a string in the format lemma.pos.num
wn.synset("zoo.n.01")
wn.synset("menagerie.n.02")- Find both definitions for menagerie
Lemma functions
wn.lemma("dry.a.01.dry").antonyms()
wn.lemma("dry.a.01.dry").name()
wn.lemma("dry.a.01.dry").count()
wn.lemma("dry.a.01.dry").derivationally_related_forms()Exercice
- From python, get frequencies for the first lemmas of adjectives
- dry and its antonym
- good and its antonym
- warm and its antonym
- Define function ant_freq(x) that returns the frequency of the antonym of a lemma
- Print the count of all the lemmas of wet along with their definitions
- Define a function frequent_synsets that outputs a list of synsets for a word that have positive frequencies
Basic Synset relations
Hypernyms and hyponyms (80% of wordnet relations)
- Hypernym: Color
- Hyponym: purple
- crimson
- violet
- Lavender
- red
- blue
- Hyponym: purple
red, blue = co-hyponyms
cat = wn.synset('cat.n.01')
man = wn.synset('man.n.01')
cat.hypernyms()
cat.root_hypernyms()
man.hyponyms()Basic Lemma relations
Compare:
wn.lemma('dry.a.01.dry').antonyms()
wn.synset('cat.n.01').hypernyms()Lexicographer files
- synsets are grouped into files: https://wordnet.princeton.edu/documentation/lexnames5wn
00 adj.all all adjective clusters
01 adj.pert relational adjectives (pertainyms)
02 adv.all all adverbs
03 noun.Tops unique beginner for nouns
04 noun.act nouns denoting acts or actions
05 noun.animal nouns denoting animals
06 noun.artifact nouns denoting man-made objects
…- Query which file a synset is in:
man.lexname()
cat.lexname()- Exercice: define function same_file(x,y) that checks whether synsets x,y belong to the same lexi. file
Wordnet (contd)
- To access all synsets:
wn.all_synsets()Beyond direct neighbours
Going from a synset to the hypernym root:
cat.hypernym_paths()Intersection between two hierarchies:
cat.lowest_common_hypernyms(bird)
cat.common_hypernyms(bird)- For any relation, you can follow the tree formed by starting from a node and following the relation:
hypo = lambda x: x.hyponyms()
cat.tree(hypo)- Notes: some trees are intractable, because too much connected, you then have to limit depth with:
wn.synset('concrete.a.01').tree(lambda s:s.also_sees(),depth=2)- Transitive closure (get them all):
hypo = lambda x: x.hyponyms()
for x in cat.closure(hypo): print(x)- The “depth” is the length of the hyponymy path from the root to a node
cat.min_depth()
cat.max_depth()= The length of the shortest (longest) hypernym path from this synset to the root.
- In addition to getting the paths from a node to the root, you may also compute the distances between the original synset and all synsets in the path:
cat.hypernym_distances()Sort these distances:
sec = lambda x: x[1]
sorted(cat.hypernym_distances(),key=sec)Synset Comparisons
- you may also compute distances between nodes that are not on the same path to the root:
cat.path_similarity(man)- gives 1/(1+L) with L=length of the path btw cat and man
- Other measures:
cat.wup_similarity(man)
cat.lch_similarity(man)
cat.shortest_path_distance(man)- Exercice: From which animal is the cat the most different? Candidates: dog, turtle, mammoth, fish, eagle, fly
- Same question but with all possible animal candidates?
FrameNet
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 71% | 71% | 89% | 43% | 57% | 50% | 57% | 61% | 75% | 86% |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | |
| 46% | 64% | 79% | 64% | 82% | 32% | 61% | 18% | 39% |
1 [horiz] A vocabulary contains 400 words; a representation of these words in the form of a 400-dimensional vector is proposed. It is likely to be: + a one-hot vector embedding - a BERT embedding - a Word-to-vec embedding
2 [horiz] You have a vocabulary of $N$ words; you want to encode them into vectors so that the distances between every pair of words is the same. Which method do you choose? + one-hot encoding - Glove - BERT
3 Glove is an embeddings method that: + is trained on co-occurrence matrices - is based on neural networks - combines LDA probabilistic embeddings with W2V
4 [horiz] Which library does not natively support transformers? + scikit-learn - JAX - pytorch
5 [horiz] Which method is the best to encode sentence semantics? - Doc2Vec - Skip-thought + Sentence-BERT
6 Random Indexing: - randomly indexes the U matrix that has been computed from the SVD decomposition as in LSA + can take into account new documents even after all the training corpus has been deleted - give better results with low-dim than with high-dim vectors
7 Collobert embeddings are trained with the objective: - generate context words + multiple standard NLP tasks (NER, POStags...) - optimize Natural Language Inference task
8 About Word-to-vec embeddings, which statement is true: - they rely on sub-word units - their training objective is: predict the following word + they are fast to train
9 Which model is not commonly used for language modeling ? - transformers - Multi-Layer Perceptron - recurrent neural network + logistic regression
10 [horiz] Which model does not rely on transformers ? + ELMo - BERT - GPT1
11 What is the best approach to compute sentence embeddings? + use BERT plus contrastive learning with sentence pairs - average every word embedding in the sentence - use xl-net
12 [horiz] Which LM requires more parameters as the length of the sentence/context increases? + feed-forward network - RNN - transformers
13 [horiz] Who invented the term "word embedding"? - Mikolov + Bengio - Collobert
14 Let's consider 2 sentences $A=$"the work is sound" and $B=$"the sound is loud"; you compute the BERT embedding of the word *sound* in $A$ and $B$ respectively as $A_s$ and $B_s$; and the embedding of the work *good* in $C=$"it's a good job" as $C_g$. What are the most likely pair of cosine similarities? + $d(A_s,C_g)=0.8$ and $d(B_s,C_g)=0.7$ - $d(A_s,C_g)=0.6$ and $d(B_s,C_g)=0.8$ - $d(A_s,C_g)=0.1$ and $d(B_s,C_g)=0.1$
15 [horiz] What is not an implementation of Distributional Semantics? - Word2Vec - LSA + one-hot vectors
16 [horiz] Which method is the fastest to train? - LSA + Random Indexing - Word2Vec
17 [horiz] (TD) Byte Pair Encoding can be trained using a Negative Likelihood Loss - True + False
18 (TD) To correctly apply cosine distance on two BERT embeddings I need to: - apply a dot product on the embeddings beforehand + finetune the BERT model on related task - normalize the two embeddings beforehand
19 (TD) Supervised similarity measures for embeddings can be obtained + by training an auto-encoder - by applying a PCA to find the most relevant components - by using the Jaccard similarityFrameNet
- Original theory:
- C. J. Fillmore, 1976
- Frame Semantics theory (Baker, Fillmore, Lowe, 1998)
- FrameNet project:
- C. J. Fillmore, 2006
- Dev by ICSI Berkeley
- Online Demo:
- Detailed documentation:
- Latest developments
- tutorial @ COLING 2018
- multilingual framenet
- 1224 Frames with
- list of (lemma,POS) = lexical units
- 13640 LU with their frames
- LU = mostly verb and action nouns + a few adj, prep and adv
- list of frame elements, core or non-core
- Average of 10 FE per frame
- 1878 Frame-Frame relations = similar semantic situations
- 10725 FE-FE relations
- 220k manually annotated examples
- The original framenet DB structure (Baker, 2003) and annotation practives (Ruppenhofer, 2016) have inspired a dozen more langages (Brazilian Portuguese, Chinese, Hebrew, Korean, Swedish…)
- goal = align them at the frames + LU levels
- Rationale of framenet: understanding the meanings of words requires knowledge of semantic frames
- Frame def:
- a schematic representation of a situation, object, event, or relation providing the background structure against which words are understood
- Script-like conceptual structure that describes a particular type of situation, object, or event along with the participants and props that are needed for that Frame

- Another example: frame Avoiding
- an Agent avoids an undesirable_situation under certain Circumstances, where that situation may be an event or an activity
- We must avoid jumping to conclusions
- Victoria avoids weekend work
- They could not avoid criticism
- Young people can avoid getting into trouble
- Frame Element
- specific to a given frame
- related to a semantic role
- Core FE for ‘Avoiding’
- Agent: the person who avoids
- Undesirable_situation: the situation that the agent avoids
- Non-core FE:
- circumstances: under which the situation is avoided
- manner: in which the agent avoids the situation
- means: by which the agent avoids the situation
- [He] avoided [giving her a direct answer] [when she asked] (circumstances)
- [By subtle means] [you] avoid [appearing naïve]
- Lexical Unit = pairing (lemma, frame)
- it’s hot outside today
- (hot, ambient temperature)
- The curry is really hot
- (hot, spiceness)
- it’s hot outside today
- LU evoke frames, e.g. Commerce_buy evoked by:
- buy.v
- buyer.n
- client.n
- purchase [act].n
- purchase.v
- purchaser.n
- Frame-to-Frame relations
- inheritance = parent-child
- using = parent-child
- subframes = complex-component
- precedes = earlier-later
- perspective_on = neutral-perspectivized
- see also = main entry-referring entry
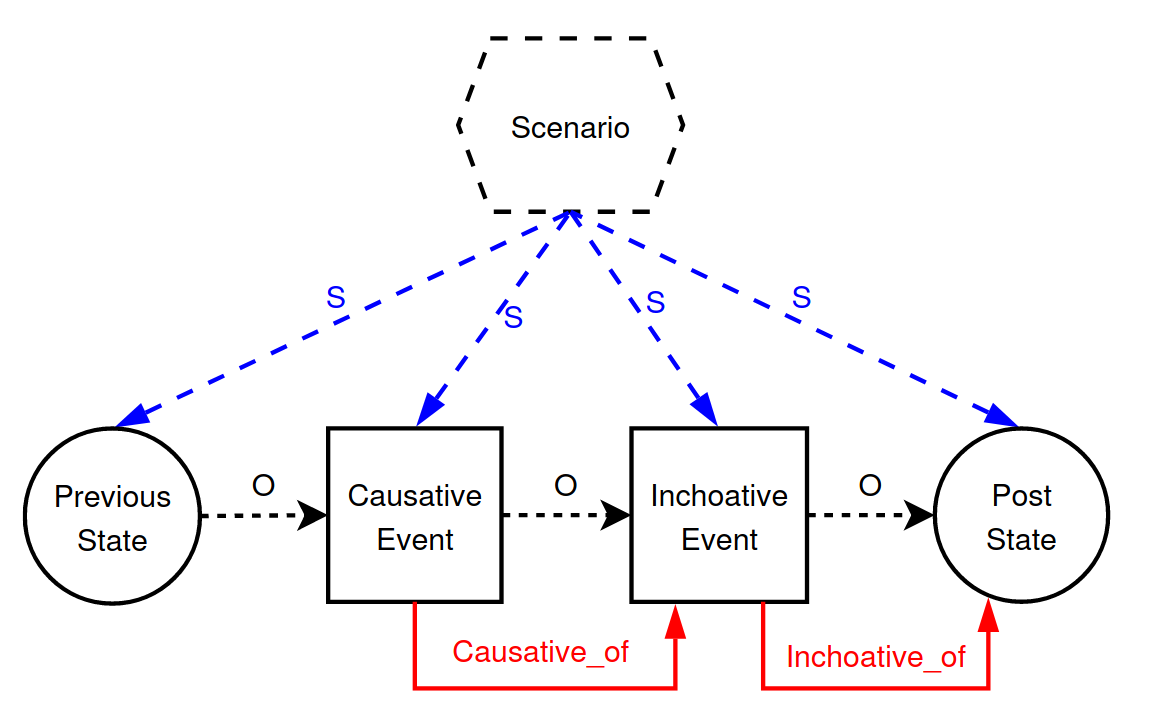
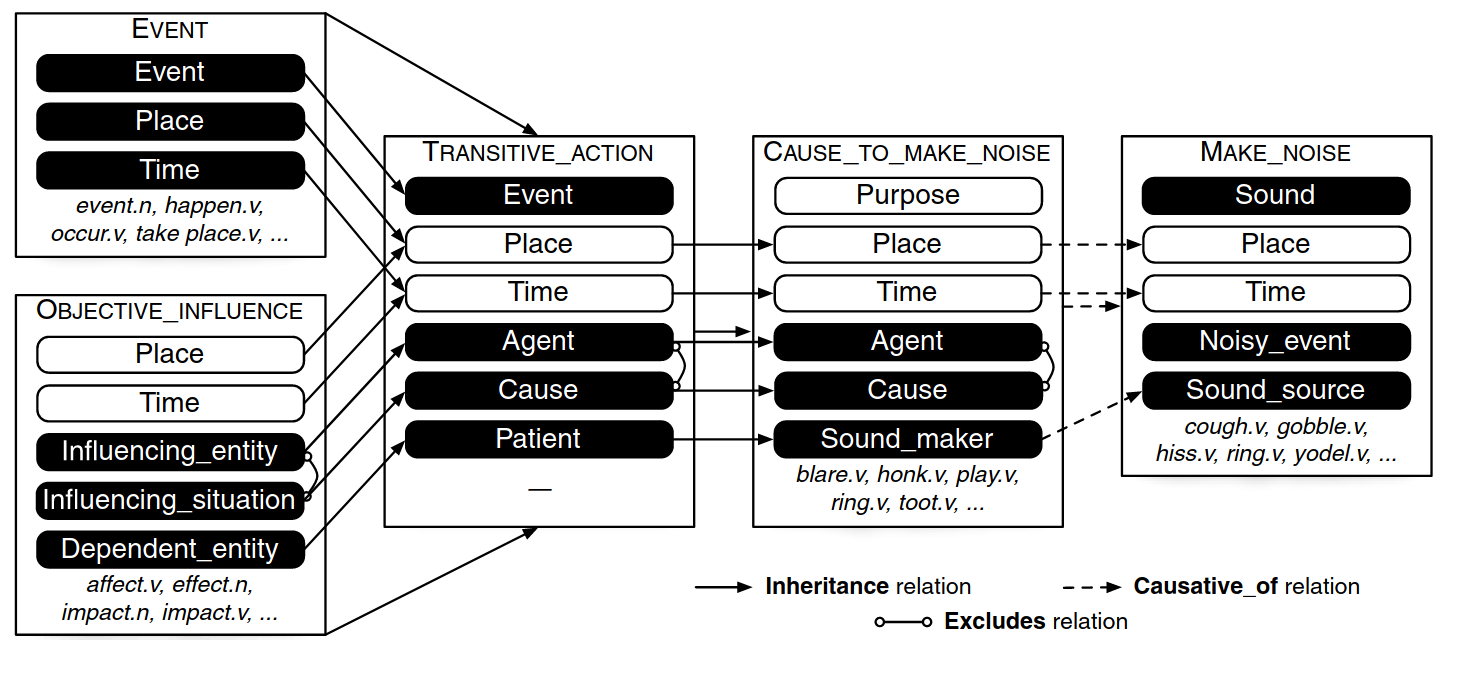
- inchoactive_of (lex rel)= beginning action-state
- causative_of (lex rel)= causing action-state
- Inheritance
- child frame = a “kind of” parent frame
- Arriving is a kind-of Motion
- Commerce_buy inherits from Getting
- precedes:
- Hiring precedes Employing
- perspective_on:
- Hiring is a perspective on Employment_start
- subframes:
- The child frame is a subevent of a complex event represented by the parent, e.g. the “Criminal_process” frame has subframes of “Arrest”, “Arraignment”, “Trial”, and “Sentencing”.
- Hiring, Employing are subframes of Employer’s_scenario
- Using:
- The child frame presupposes the parent frame as background, e.g the “Speed” frame “uses” (or presupposes) the “Motion” frame
- Motion uses Body_movement
- see also:
- Motion refers to Ride_vehicule
- causative/inchoactive:
FE-FE relations
Frame Grapher
- Other languages:
- French
- Portuguese
- German
- Spanish
- Japanese
- Multilingual ? (Torrent, Borin, Baker, 2018)
- multilingual framenet
- Aligning frames across languages: difficult
- Attempts based on cross-linguistic words embeddings (Conneau, 2017)
- Measuring overlap of LUs across languages
- frame X is aligned with frame Y when there are enough LUs associated with each that are good translations of each other
- First trial: align English-Spanish
- chose 200k word forms from both LUs
- FastText embeddings for all of them
- Train linear mapping btw them
- Removed src and tgt LUs without translations
- Use these joint embeddings to translate LUs
- map frames with enough “common” LUs
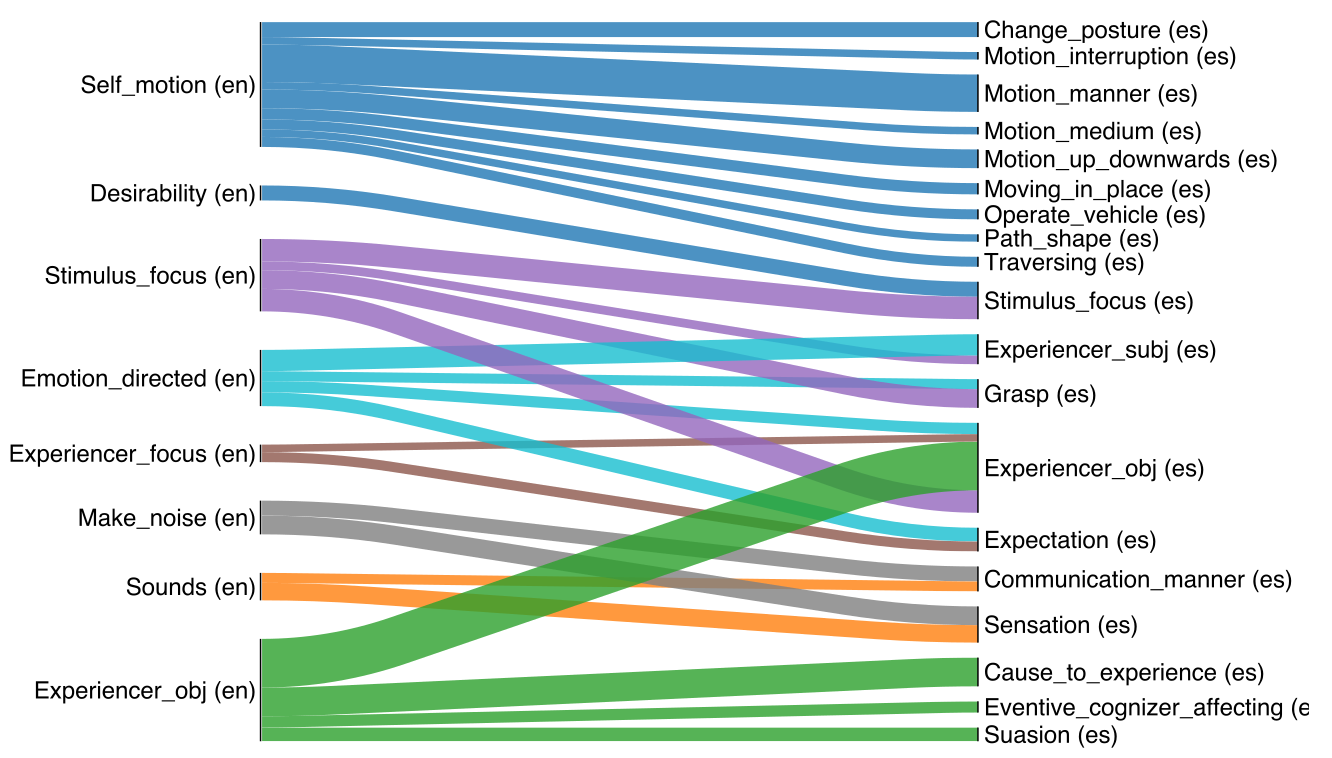
- Alignment: work in progress, still many issues
- Another WIP:
- Annotating TED talk: “Do Schools Kill Creativity”
- widely translated
- ENG + Portuguese: 10% differences
Parsing with FrameNet
“After encouraging them, he told them goodbye and left for Macedonia”
After encouraging them, he told them goodbye and left for Macedonia
- Target identification:
- after.PREP
- encourage.V
- tell.V
- leave.V
After encouraging them, he told them goodbye and left for Macedonia
- Frame identification
- time_vector
- stimulate_emotion
- telling
- departing
- Frame-element identification
- for TELLING
- “after encouraging them” = time
- he = speaker
- them = addressee
- goodbye = message
- for TELLING
- Frame-element identification
- for TIME_VECTOR
- “encouraging them” = landmark event
- “he told them…” = event
- for TIME_VECTOR
- Frame-element identification
- for STIMULATE_EMOTION
- “them” = experiencer
- for STIMULATE_EMOTION
- Frame-element identification
- for DEPARTING
- “for Macedonia” = goal
- for DEPARTING
Training a parser from FrameNet
- supervised learning
- why ?
- knowledge extraction from Twitter (Sogard, 2015)
- social network extraction (Agrawal, 2014)
- dialog systems (2013)
- …
Target identification
- challenges
- verbs, nouns, adj, prep can be targets
- MWE = 4% of all targets in FN 1.5
- targets can be discontinuous: “there would have been” => LU “there_be.V”
- SemEval’07: F1 = 79%
Frame identification
- given target LU, find evoked frame
- on agv, 2 frames per LU
- acc=90% from gold targets
Argument identification
- most challenging task
- relies on syntax
- F1=77% from gold targets
Recent progress
- joint prediction of predicates, senses and arguments (Labeled Span Graphs, He et al. ACL 2018)
- multitask learning
- with syntax
- propbank + framenet (Fitzgerald, EMNLP 2015)
NLTK FrameNet
- Getting started:
from nltk.corpus import framenet as fnAccessing frames
fn.frame('Motion')
f=fn.frame(7)frame(fn_fid_or_fname, ignorekeys=[]) method of nltk.corpus.reader.framenet.FramenetCorpusReader instance
Get the details for the specified Frame using the frame's name
or id number.fn.frames()
fn.frames(r'(?i)crim') # case-insensitive regexframes(name=None) method of nltk.corpus.reader.framenet.FramenetCorpusReader instance
Obtain details for a specific frame.Accessing LU
fn.lus()
fn.lu(4896)Accessing FE
f.FEAccessing frame relations
f.frameRelationsAccessing FE relations
fn.fe_relations()- Data type
- FrameNet has chosen to implement averything with a mapping “keys” -> “values”
- look at type(f.frameRelations[0])
- look at type(fn.fe_relations()[0])
- So to know which type of relation you’re manipulating:
f.frameRelations[0]._type
fn.fe_relations()[0]._type- Get all attributes of a frame:
print(f.keys())- Useful attributes of a frame:
- name, definition, FE, lexUnit, frameRelations
FrameNet corpora
- Full-text annotations = part of SemEval-07 shared task 19.
- Texts from journals: 14k diff words, 4020 sentences with LU
- Exemplary sentences with partial annotations
- Crafted texts: 132k diff words, 141k sentences
- list all documents:
fn.docs()- list all documents metadata:
fn.docs_metadata()- access a specific document:
fn.doc(id)- access a sentence in a document, and its annotations:
fn.doc(6).sentence[0]
fn.doc(6).sentence[0].annotationSet[0]- get all sentences with a frame:
fn.exemplars(frame='Motion')- get all sentences with a lexical unit:
fn.exemplars('run')Searching
- Search in frames:
fn.frames('Motion')- Is it case sensitive ?
- Does it support regular expressions ?
- Search in lexical units:
fn.lus('xpress')- Is it case sensitive ?
- Does it support regular expressions ?
- Retrieving a lexical unit by ID:
g=fn.lu(5372)
g.ID
g.definition
g.name- Get the frame evoked by a LU:
g.frame
g.frame.nameGetting help
- Google search is very good
- When offline:
help(fn)Exercices
- How many frames are there about substances?
- Which one has 11 FE? let it be x
- Which frames inherit from x? and x inherit from?
- How many frames are ‘siblings’ with x, accoridng to inheritance?
- list all relations that are connected to FE “Degree”
- list all frames annotated in all sentences from the first document
- how many examples with ‘computer’ exists in FrameNet?
- What are the other lexical units that refer to these annotated frames?
- Plot the distribution of the number of frames a word invoke (as a LU)