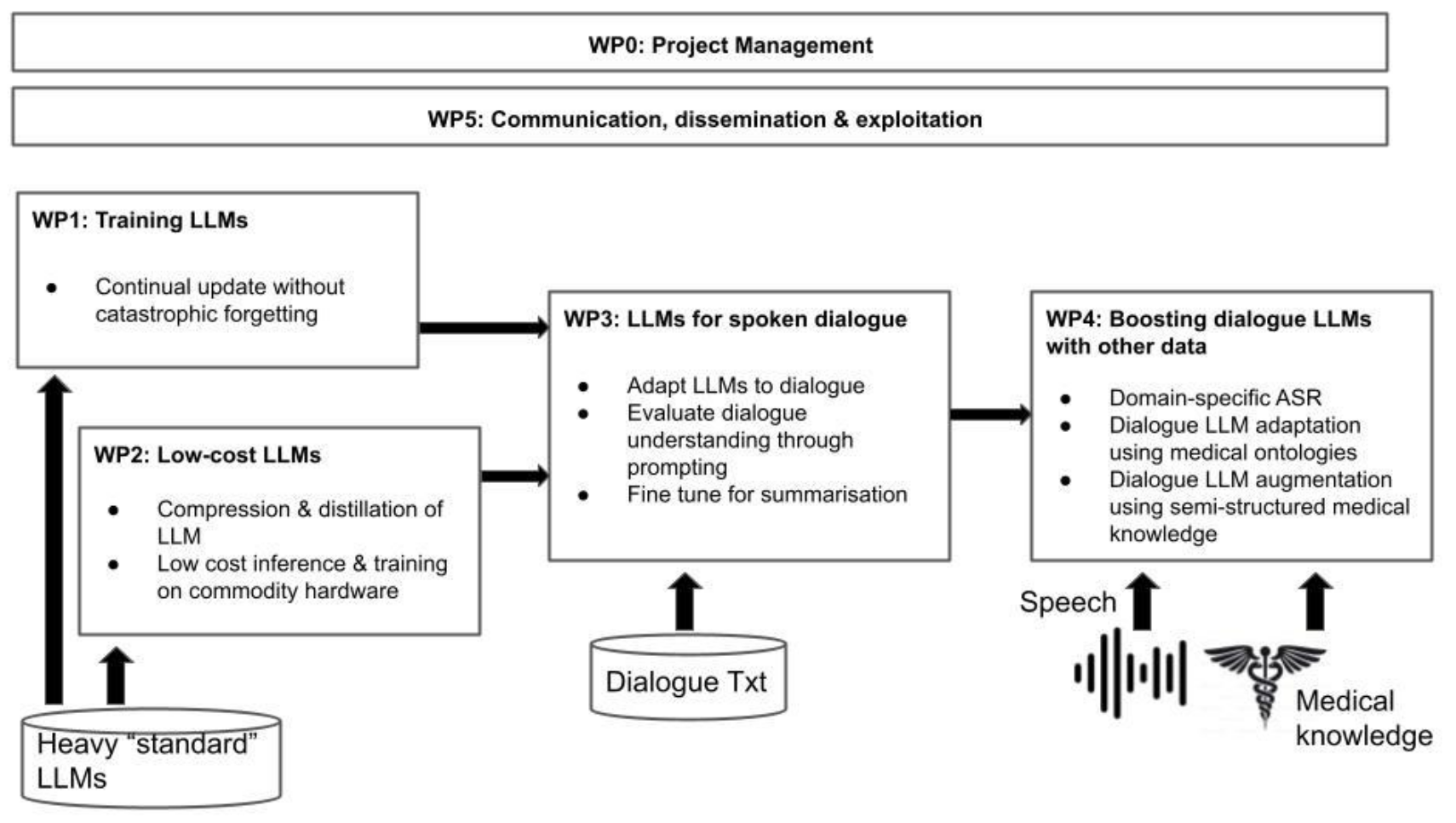
LLM4ALL Year 1 meeting
- News:
- consortium agreement
- Carbon-ANR 19 nov
- journee TAL Rennes 13 dec
- Deliverables: deadline 31 oct
- D3.1 (augmented dialogue dataset)
- D3.2 (summarization)
- D4.1 (SimSAMU)
- D4.2 (ASR)
- D4.4 (ER calls)
- D5.3 (exploitation plan)
- Interm. report: 1 avr 2025
LLM4ALL WP1
- 2023 objectives:
- updating LLM in French with continual learning
- proposed approach in 2023
- Sheared-Llama: prune + retrain
- Work done (Yaya talk at next PMT):
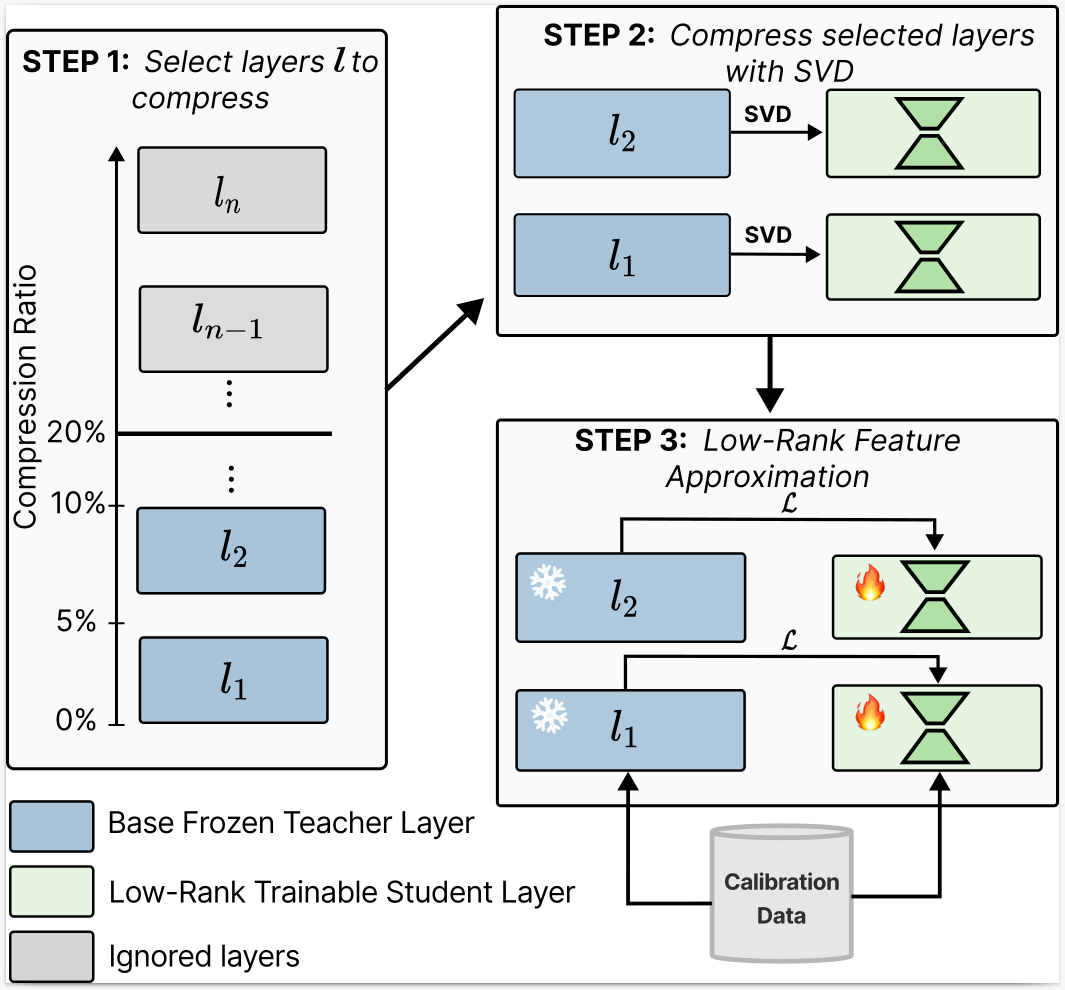
- 1 year later, need to rethink objectives?
- Issue 1: data
- Issue 2: state of the art
- data:
- On which data shall we update our model?
- Lessons from SOTA: (cf. “Physics of LM…”)
- Need 1000x occurrences of 1 new information
- Standard finetuning is worth only 1 bit
- Long finetuning on new data induces large forgetting
- Pretrained LLMs have low capacity to acquire new knowledge
- 1 year recent French data: 1M words
- Data scrapped during 1 year from headline news from France-Info, Le Monde…
- Could scale (with lots of work!) with Wiki, scrapping… to 100M or 1b words
- This is no continued pretraining, just finetuning
- The only “finetuning” option?
- Mixing new (repeated) + old data to get more than 100b words
- Continue training on this
- Issues:
- Large cost for each update
- Finding the good mix is difficult (requires lots of costly experiments)
- Isn’t it better to pretrain from scratch? (PLM not good at acquiring new knowledge!)
- state-of-the-art:
- Best updating method with “small” data: RAG, LLM agents
- Tested QA on French News
- RAG gets nearly perfect results… so up-to-date LLMs are solved ?!
- Pb: cannot release data because of copyright
- Best updating method with “small” data: RAG, LLM agents
13 septembre 2024: Quel grand magasin parisien est menacé en raison de problèmes financiers et de retards de paiement depuis son rachat par la SGM il y a un an ?
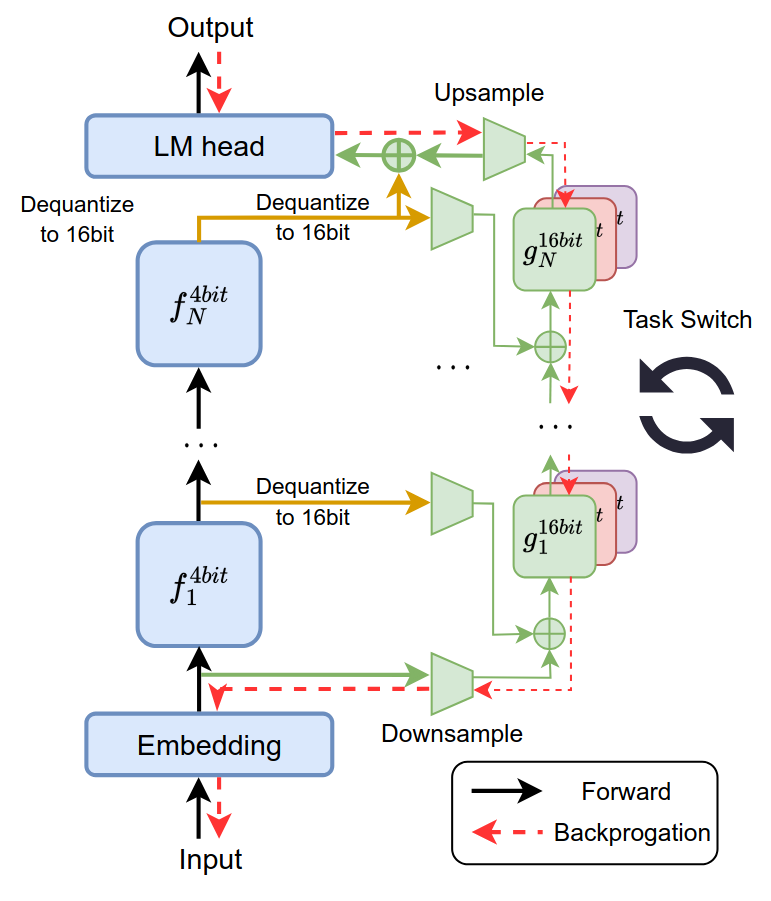
- Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized LLM
- Best paper award at ACL’24
Knowledge Entropy decay during Language Model Pretraining hinders new Knowledge Acquisition
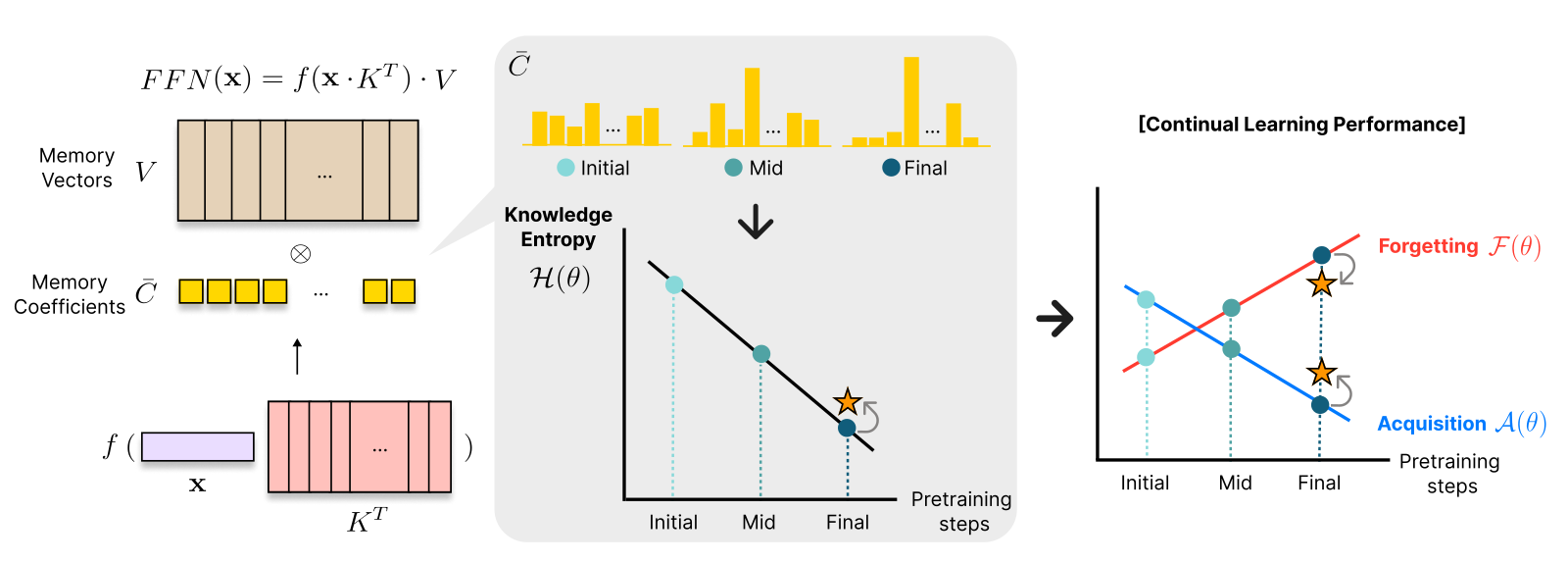
- Proposal: focus on more fundamental training aspects: speed, cost, generalization
- Growing nets:
- Good theoretical properties: their minima generalize well
- Do they limit the knowledge entropy issue?
- Growing nets:
Discussion
- Issues:
- FR News: not enough data for CL
- RAG solves LLM updating
- What is the most impactful for WP1?
- Stick to CL with LSN, but need to get many data
- More theoretical study on growing nets
Future
Deliverables! deadline 31 oct
- Topics of discussion:
- Collaboration among us: which topic? how?
- Extend our external impact: how?
- Work on/improve Lucie?
- Evaluation?
- What is the impact of SOTA? Shall we focus more on RAG? multimodality? Synthetic data?