Embeddings hands on
Objectives:
- manipulate embeddings
- what is inside embeddings ?
4 exercices next:
- Python-easy
- proximity in the embedding space (transformers)
- FastText
- Python-hard
- probing embeddings
- byte-pair encoding
Embeddings
- install transformers library + pytorch with conda or pip:
pip install transformers[torch]from transformers import AutoTokenizer, AutoModel, pipeline
model = AutoModel.from_pretrained('distilbert-base-uncased')
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
nlp = pipeline('feature-extraction', model=model, tokenizer=tokenizer)
s = 'Do you like cakes ?'
features = nlp(s)
print([features[0][i][:2] for i in range(len(features[0]))])
inputs = tokenizer.encode_plus(s, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
text_tokens = tokenizer.convert_ids_to_tokens(input_ids)
print(text_tokens)cosine distance
pip install sklearnfrom sklearn.metrics.pairwise import cosine_similarity
print(cosine_similarity(v1,v2))- compare the cosine-distance between (table, chair) and (table,
array) in
- ``the excel table is too big’’
- ``the chair is solid’’
- ``the wood table is too big’’
- ``the array is filled with numbers’’
- However, see https://github.com/huggingface/transformers/issues/2298
- Solution: contrastive training (see, e.g., S-BERT)
- libraries for contrastive trained embeddings: sentence-transformers
FastText (easy)
- Easy self-explained hands-on on fast-text, with very very low requirements of programming: Exercice: fastText
Byte-pair encodings
- We want to decompose words into frequent subword sequences
- Byte-Pair Encoding is a method used in many deep learning models:
- Build unigram: “low”: 5, “lowest”: 2…
- Decompose into char: “l o w @”: 5, “l o w e s t @”: 2…
- Find most frequent unit pair: “ow”: 7
- Merge into new unit: “l ow @”: 5, “l ow e s t @”: 2…
- Iterate until a target nb of units is reached
Exercise: BPE
- Print the first 100 BPE pairs merged on nh.txt
- file: https://olki.loria.fr/cerisara/lexres/nh.txt
Probing embeddings
Is there linguistic information in the embedding ?
- TOEFL synonimy test
- LSA performs as good as English learners
- Analogies
- W2V: “king - man + woman = queen”
- not true any more with BERT
Probing
- If there is linguistic information encoded in an embedding, it’s not obvious to see it
- But this information should be exploited by a small model to “tag” sentences with this linguistic property
- the model must be too small to be able to extract itself the linguistic property from the raw sentence
- it must not be able to do complex processing of the vector
- it should only relate embeddings to linguistic tag with a direct, simple function
Probing POS
Answer the question: do BERT embeddings embed POS information ?
Methodology:
- Find a corpus annotated with POS
- Compute word embeddings on this corpus
- Train a logistic regression to map Embeddings to POS tags
- Compute the accuracy of the LR classifier from target vs. random embeddings
import nltk
nltk.download('brown')
nltk.download('universal_tagset')
nltk.corpus.brown.sents()
nltk.corpus.brown.tagged_words(tagset='universal')Universal tagset:
VERB - verbs (all tenses and modes)
NOUN - nouns (common and proper)
PRON - pronouns
ADJ - adjectives
ADV - adverbs
ADP - adpositions (prepositions and postpositions)
CONJ - conjunctions
DET - determiners
NUM - cardinal numbers
PRT - particles or other function words
X - other: foreign words, typos, abbreviations
. - punctuationLogistic regression
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(random_state=0).fit(X, y)
clf.predict(X[:2, :])
clf.predict_proba(X[:2, :])
clf.score(X, y)Another reference on this subject: https://pageperso.lis-lab.fr/benoit.favre/pstaln/09_embedding_evaluation.html
Triplet loss
(see github blog)
- Train ConvNet on MNIST with 10-class cross-entropy loss
- Extract 2-dim embeddings from penultimate layer:
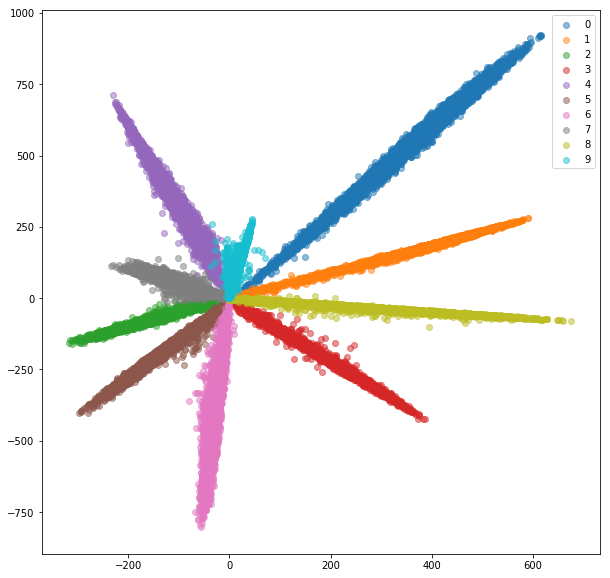
- Distance btw classes not good
- Train a siamese net
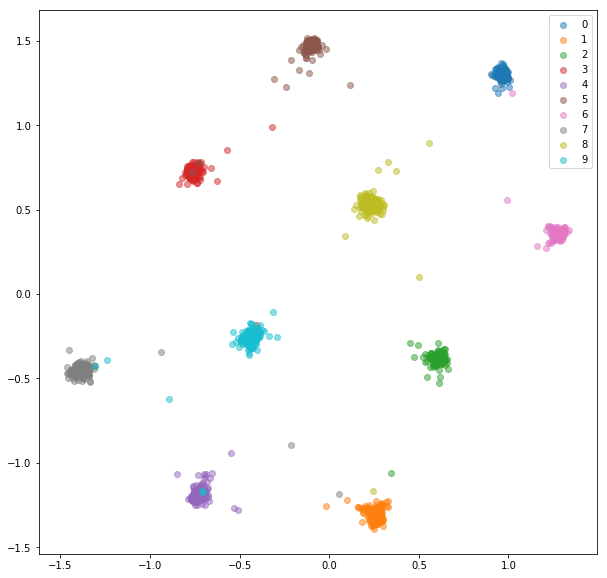
- Distance btw classes are good
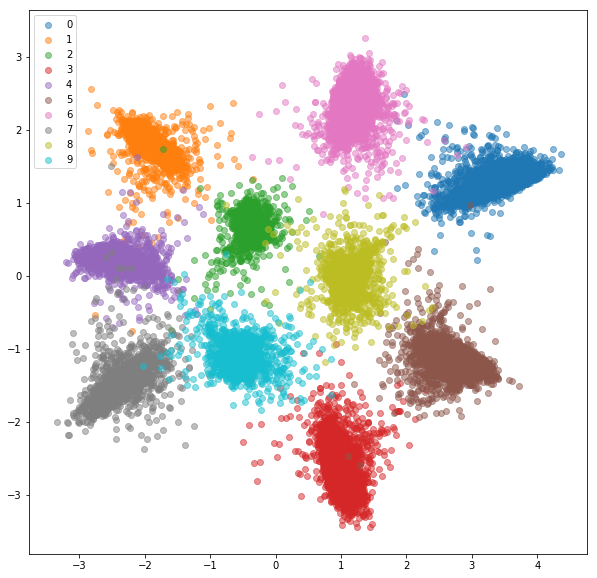
- Train a triplet net
In pytorch
- CosineEmbeddingLoss = pairwise loss with cosine dist
- MarginRankingLoss = pairwise loss with euclidian dist
- TripletMarginLoss = triplet loss with euclidian dist
Triplet loss: exercices
- Goal: train a linear embedding space with triplet loss
- Synthetic data:
- scalar input, 2 classes \(c\in \{0,1\}\)
- \(x|c \sim N(\mu_c,\sigma_c=0.1)\)
- Embedding dim = 5
- lightning = pytorch library that
- automates cpu/gpu runtime
- simplifies training loop
- generates tensorboard logs
- pytorch lightning in practice:
- replace and extend nn.Module:
import pytorch_lightning as pl
class Mod(pl.LightningModule):
def __init__(self):
super().__init__()
self.W = torch.nn.Linear(1,5)
def configure_optimizers(self):
opt = torch.optim.AdamW(self.parameters(), lr = 1e-3)
return opt
def training_step(self, batch, batch_idx):
anc, pos, neg = batch
ea = self.W(anc)
ep = self.W(pos)
en = self.W(neg)
dp = torch.nn.functional.triplet_margin_loss(ea,ep,en)
self.log("train_loss", dp, on_step=False, on_epoch=True)
return dp- you need a dataset that generates anchors/pos/neg:
class TripDS(torch.utils.data.Dataset):
def __init__(self):
super().__init__()
def __len__(self):
return 1000
def __getitem__(self,i):
if i%2==0:
# pair: on sample une ancre from class 1
xa = torch.randn(1)/10.-0.5
xp = torch.randn(1)/10.-0.5
xn = torch.randn(1)/10.+0.5
return xa,xp,xn
else:
# impair: on sample une ancre from class 2
xa = torch.randn(1)/10.+0.5
xp = torch.randn(1)/10.+0.5
xn = torch.randn(1)/10.-0.5
return xa,xp,xn- Train:
traindata = TripDS()
trainloader = torch.utils.data.DataLoader(traindata, batch_size=1, shuffle=False)
mod = Mod()
logger = pl.loggers.TensorBoardLogger(save_dir="logs/", flush_secs=1)
trainer = pl.Trainer(limit_train_batches=1.0, max_epochs=1000, log_every_n_steps=1,logger=logger)
trainer.fit(model=mod, train_dataloaders=trainloader)tensorboard --logdir=lightning_logs/- TODO:
- Adapt this code to train a linear embedding that takes as inputs 1-hot encoding of digits 0 to 9, and outputs a 2D-embedding. Then train this embedding with a triplet loss in order to shape the embedding space so that the digits appear ordered in the embedding space. Plot the embedding space with matplotlib.