Loss landscape geometry
- We are interested in the “loss landscape”, which can be viewed as a
surface:
- Z = scalar value of the loss
- X1,X2,… = parameters of the DNN
- Training == finding a good minimum
- Which is more or less difficult, depending on the geometry of this surface
- Easy cases: convex space
- Main focus of ML in the past
- Obvious properties for DL:
- highly non-convex
- high-dimensional
classical ML view
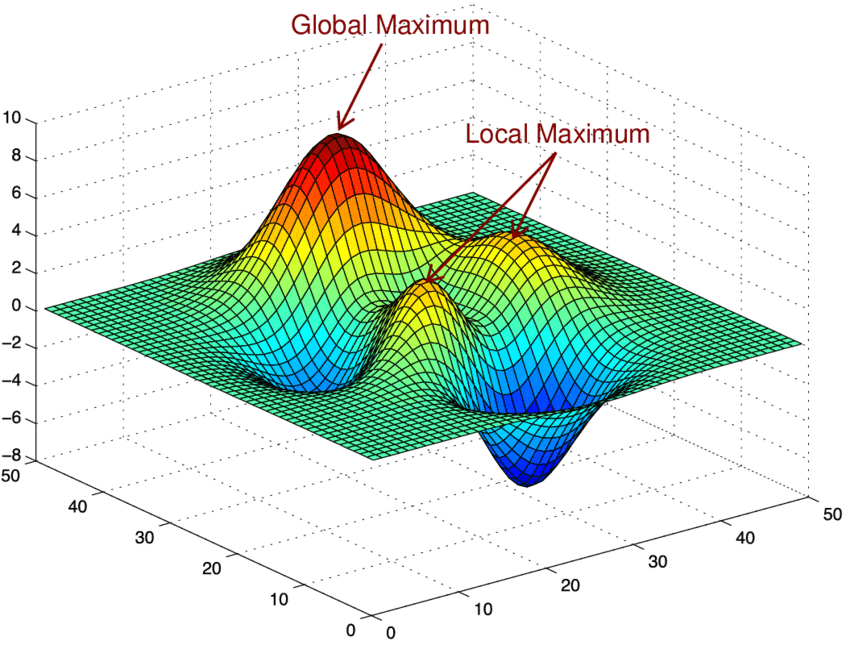
- loss landscape
- 100s parameters, 1000s samples
DL view
- millions of parameters and samples
- is the ML view still correct ? … Thought XP:
- a DNN has been trained to an optimum
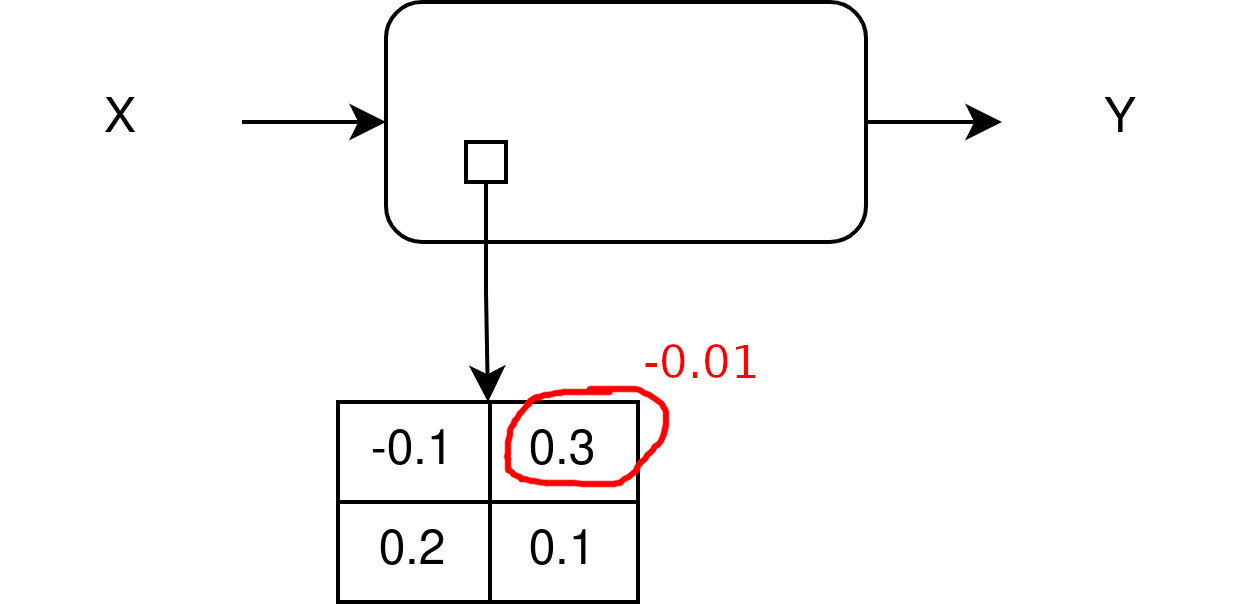
- we modify a bit one dim and freeze it
- we retrain the millions other parameters: what happens?
- hint: cf. double descent
- start again from the new position; what happens?
- does the loss landscape looks like in the classical ML view?
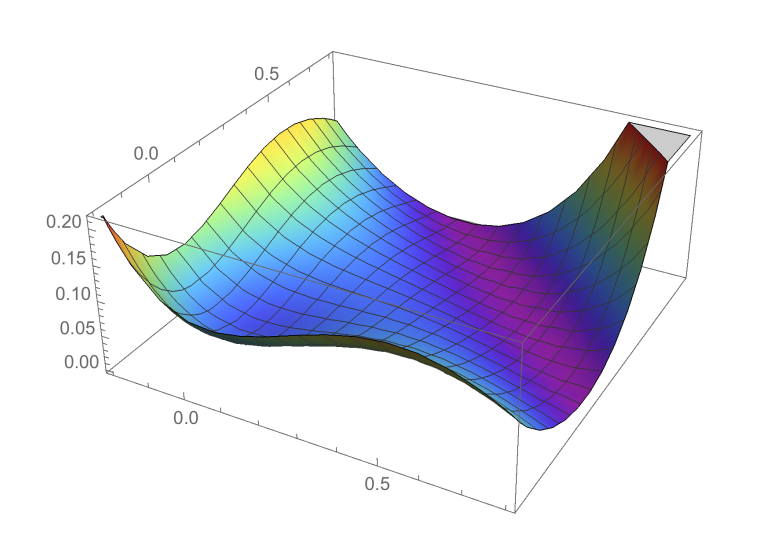
- optima define manifolds that run through the whole space
- Consequences:
- Many optima that are connected together, like “valleys”
- Most of these optima are similarly good
- It may not be so hard to find them
- These valleys are flat, at least along a few dimensions
- More info:
- “Mode connectivity”: https://arxiv.org/abs/1802.10026
- linear mode connectivity
- Permutation symmetries: https://arxiv.org/abs/1802.10026
All local optima are good
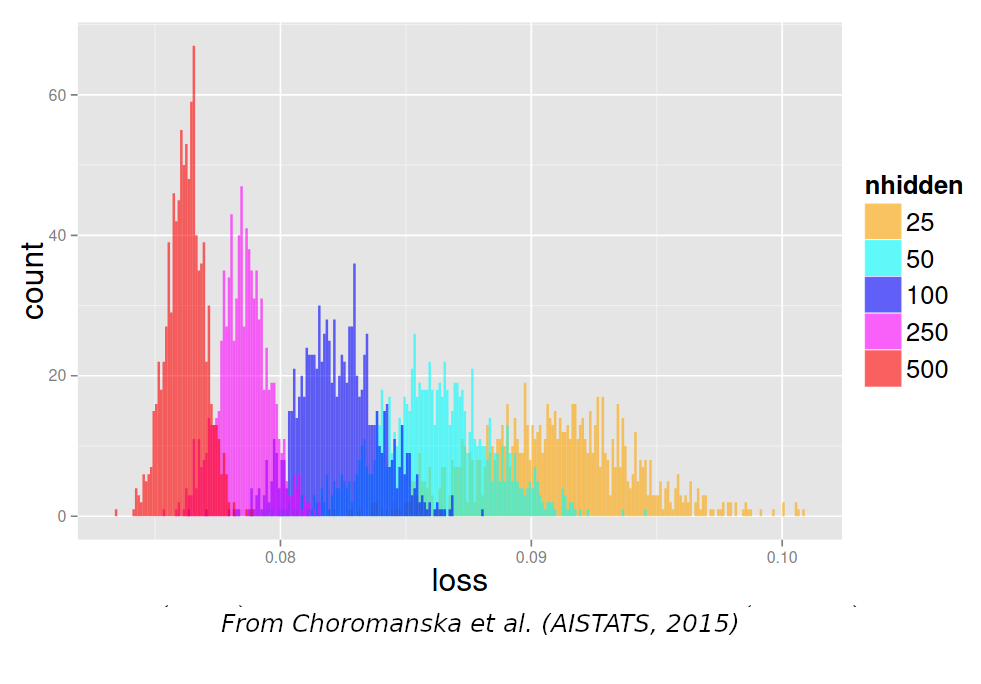
- all minima are good
- proof: Kawaguchi et al., “Neural Computation”, MIT Press, 2019
On saddle points
- saddle point = critical point that is not an optimum
- reaching any minimum is hard, because there are many saddle points:
- in high dimension, the probability that all derivatives go up is low
- A lot of efforts to escape saddle points:
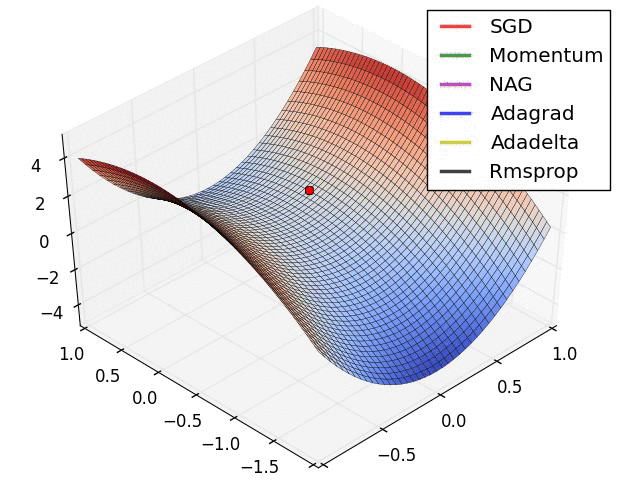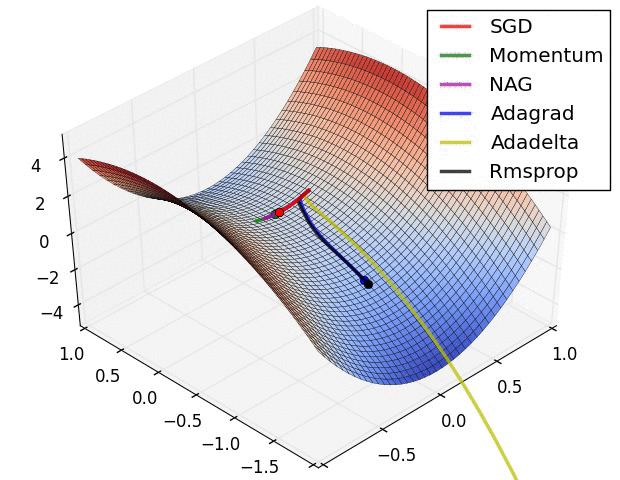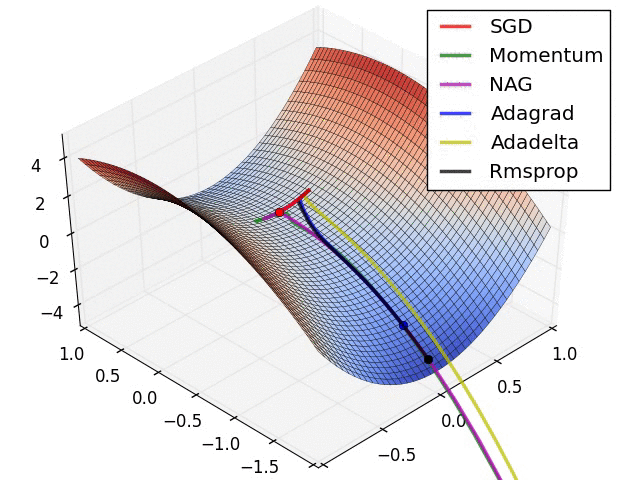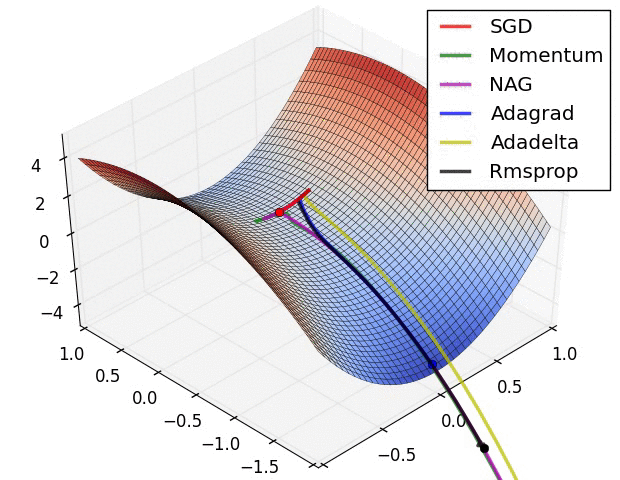
- (From Alec Radford)
On flatness
- Also, several works suggest that optima might be “flat” with “peaky
borders”
- cf. “asymmetric valleys”, “shallow basins”…
- Better generalization may be obtained by looking for the center of
the valley
- Stochastic Weight Averaging is good for that
Conclusion on the loss landscape
- Main take-away:
- We don’t care anymore about local minima !
- We care about saddle points
- We care about flatness of minima
Conclusion on the loss landscape
- if optima live on a manifold, then we don’t need all parameters
- cf. all papers on pruning, distillation that can reduce down to 1% of all parameters
- but how to find them ?
Recent progress in the study of the loss landscape
ICLR’22:
TP2: CNN
- Liste des “erreurs”
- test loss systematiquement < train loss
- tuner les hyper-parametres
- “predire a 7 jours”
- mismatch train/test
- comparer modèles comparables
- underfitting rarement détecté
- non-usage de la majorité des données
- gestion des séquences de longueur variable
- Q: est-ce que test/dev/validation loss peut être < au train loss ?
- “predire a 7 jours”
- attention au “receptive field” du CNN: predire vraiment a 7 jours
- attention a ne pas mettre les output dans les input !
- mismatch train/test
- predire la meme chose au train et au test
- comparer RNN et CNN comparables
- memes infos en entree
- underfitting rarement detecte
- predire uniquement la derniere valeur: perte d’information importante pour le training
- choix pour le CNN (mais aussi pour le RNN !): fenetre glissante, ou
toute la sequence mais avec pooling ?
- une ‘erreur’ = fixer la taille de la sequence
Varying length sequences
- Use cases:
- text: sentences have vayring length
- sound/speech
- video
- genomics
- industrial data…
- Why varying length is a problem?
- 2 reasons:
- some models require fixed size inputs
- GPU require fixed size tensors
- Layers that require fixed size inputs:
- feed-forward
- Layers that input and output varying lengths:
- CNN, RNN, attention, pooling
- Layers that input varying lengths and output fixed length:
- RNN, global pooling
Strategy with MLP
- The MLP requires fixed-size (Batch, D) input
- How can we input a (Batch, T, D) tensor?
- Sol part 1: sliding window
- Sol part 2: flatten the sequence before the MLP, unflatten after the MLP
- Sol part 3: add a pooling
Strategy with RNN
- an RNN can be used in 2 ways:
- in: seq -> out: summary vector
- in: seq -> out: seq
- typical use case: you want to predict a class at every step from the history
- solution 1:
- input the history, output the single summary vector
- complete the history, iterate
- sol. 1 is perfect at test time
- can be “autoregressive” when you don’t observe several following steps ==> seq2seq
- when you observe the steps progressively, it’s better to use the evidence
- But sol. 1 is very costly at training time!
- sol. 2 for training:
- input the full history, output one summary vector at every step
- training all steps is done in a single iteration (cf. TP2)
- it’s possible because RNN is strictly left-to-right (causal)
Strategy with transformers
- The transformer transforms an input T-seq into an output T-seq
- So you still get a seq, which may be annoying
- But each \(y(t)\) encompasses the
whole context
- and transformers are so pwerful, that you “may” take any \(y(t)\) as the summary of the whole seq!
- in practice: pick the last \(y(T)\), or the \(y(t)\) that corresponds to a special token (CLS)
- Another common option is to use some pooling on all \(y(t)\)
Strategy with CNN
- CNN transform an input T-seq into an output T’-seq
- can become complex when stacking layers!
- best practice: add padding so that T=T’ if possible
- best pract: always add global pooling on top when a single vector is required
Strategy with “special” attention
Common strategy for varying length in batch
- Option 1: just use batchsize=1
- not very efficient with GPU
- Option 2: padding + truncation
- PB1: which length to choose?
- PB2: how to prevent the loss & other layers to use padded elts?
- use a mask to define which elts are not padded
- many pytorch layers support a mask
- causal mask used in decoders
- In practice:
- RNN: cf. hands on
- CNN: cf. hands on
- Transformers: support attention_mask
Practice: padding/masking
- Here’s a working code for padding a mini-batch of 2 sequences as input to a RNN:
import pytorch_lightning as pl
import torch
torch.random.manual_seed(0)
class ToyModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.rnn = torch.nn.RNN(1,1,batch_first=True)
self.lossf = torch.nn.MSELoss()
def test_step(self,batch,batchidx):
print("IN",batch.shape)
y=self.rnn(batch)[0]
print("OUT",y.shape)
# create a gold value=1 for every timestep
gld = torch.full(y.size(),1.)
loss = self.lossf(y,gld)
print("LOSS",loss.item())
def configure_optimizers(self):
opt = torch.optim.SGD(self.parameters(),lr=0.01)
return opt
class ToyDataset(torch.utils.data.Dataset):
def __init__(self):
super().__init__()
self.data = []
self.data.append(torch.tensor([0.,1.,2.]).view(-1,1))
self.data.append(torch.tensor([0.,1.,2.,3.]).view(-1,1))
def __len__(self):
return len(self.data)
def __getitem__(self,i):
x = self.data[i]
return x
def custom_collate(data):
x = torch.nn.utils.rnn.pad_sequence(data,batch_first=True)
return x
mod=ToyModel()
dd=ToyDataset()
ds = torch.utils.data.DataLoader(dd, batch_size=2, collate_fn=custom_collate)
trainer = pl.Trainer(max_epochs=1)
trainer.test(mod,ds)- Check whether the padded timestep affects the final hidden state in the RNN
- prevent this by “packing” seqs+length as input (and unpacking them after the RNN):
x = torch.nn.utils.rnn.pack_padded_sequence(x, [3,4], batch_first=True, enforce_sorted=False)
y,yfin = self.rnn(x)
y,_ = torch.nn.utils.rnn.pad_packed_sequence(y, batch_first=True)- Check again whether the padded timestep affects the final hidden state in the RNN
- Now check whether the loss is affected by padded elements?
- replace the vanilla loss by one you compute yourself with a mask:
mask = torch.full(y.size(),1.)
if mask.shape[0]>1: mask[0,3,0]=0.
non_zero_elements = mask.sum()
loss = self.lossf(y,gld)
loss = (loss * mask.float()).sum() # zero masked elts
loss = loss / non_zero_elements- check manually that the final loss corresponds to what is expected
Causal convolution
- Implement a module for causal convolution (see F.pad()):
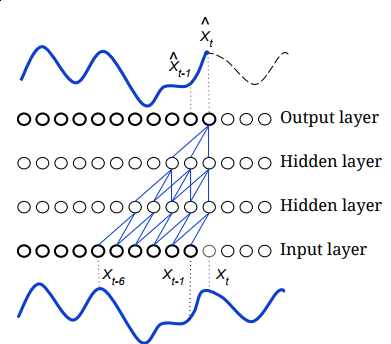
- Check that the future does not alter the present
- Extra: implement a causal convolution with dilation