LLM4All
Kickoff meeting
![]()
| 10h00 | WP0 + intro (LORIA) |
| 10h30 | WP1: finetuning (LORIA) |
| 11h00 | WP2: low-cost LLM (LIX) |
| 14h00 | WP3: LLMs for spoken dialogues (Linagora) |
| 14h30 | WP4: LLM+other data (APHP) |
| 15h00 | WP5: communication (Lionagora) |
| 15h30 | Session data: (Linagora + APHP) |
| 16h15 | Setup agenda and next meetings |
| 16h45 | Misc and wrapup |
WP0
Participants: all
Website
PMT
Advisory board
Data Management Plan
Website
- https://ia.loria.fr/llm4all
- Intranet: (see password in email from Sep 8th 2023 11:41 )
- documents
- gitlab: https://gitlab.inria.fr/synalp/llm4all
- minutes, sources, website…
- mailing list: llm4all@inria.fr
- Suggestions? (mastodon?…)
Project Management Team
- PMT
- 1 person/partner + WP leader
- shall meet every month: date / time?
- Advisory board
- PMT + invited external experts + ANR
- shall meet every year
First Deliverables
T0+6: D0.2: Data Management Plan
List all data produced/consumed:
- datasets, code, publications, internal & external reports, deliverables, website, blogs…
- public/private, licence, diffusion, where stored, security, when deleted, how long-term support
Website OPIDOR? (painful!); Latex template!
WP1 “Finetuning”
- How to finetune
- Continual learning
Overview: LLMs
What is a Large Language Model?
- An LLM is a transformer that transforms texts into a representation (embedding), and predicts the next word
- Transformer invented by Google in 2017:
- No bottleneck of information (compared to previous models)
- It scales!
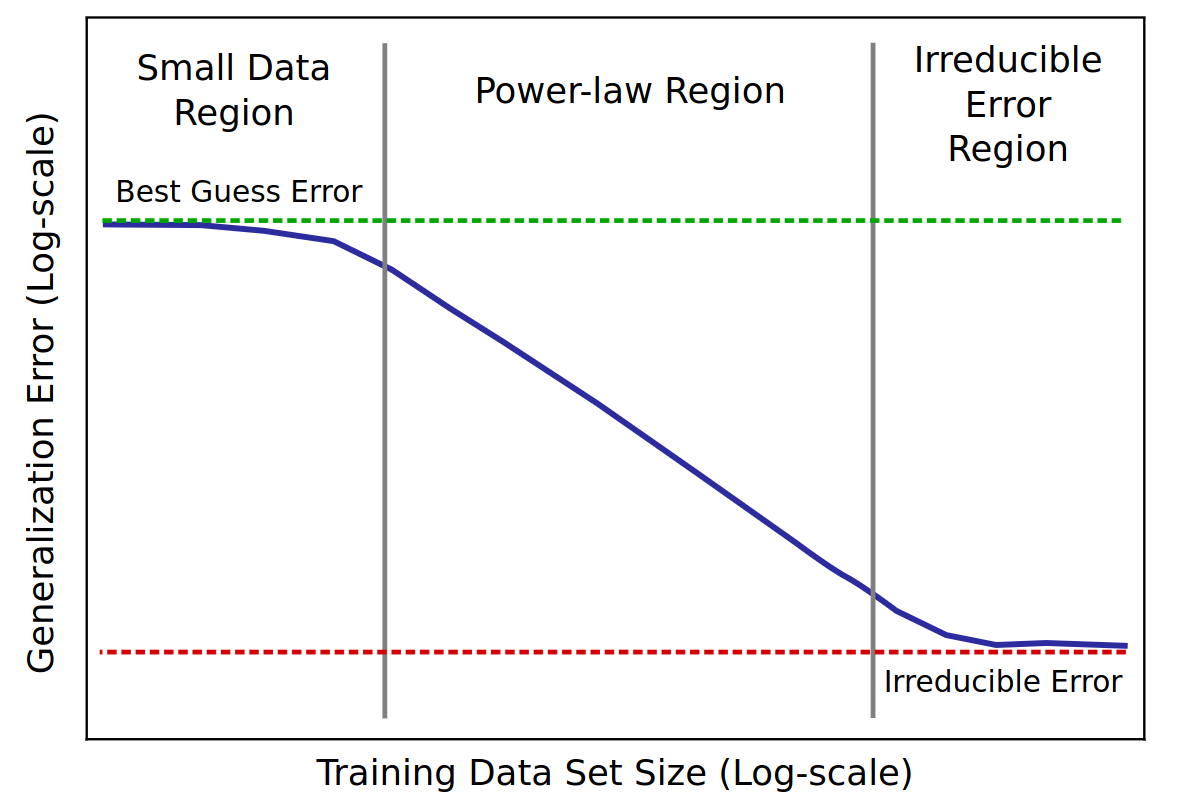
Scaling property of LLMs
- scaling = if you add parameters, it can store more information
- controlled by measuring its performances on tasks
- scaling law = power law = \(y(x) = ax^{-\gamma} +b\)
- metric = test loss
- \(\gamma\) = slope
Baidu paper 2017
GPT3-175b paper 2020
- emergence of In-Context Learning !
- provide examples of a task in the context, the output mimics the examples
Scaling laws for Neural LM 2020
Open-AI 2020
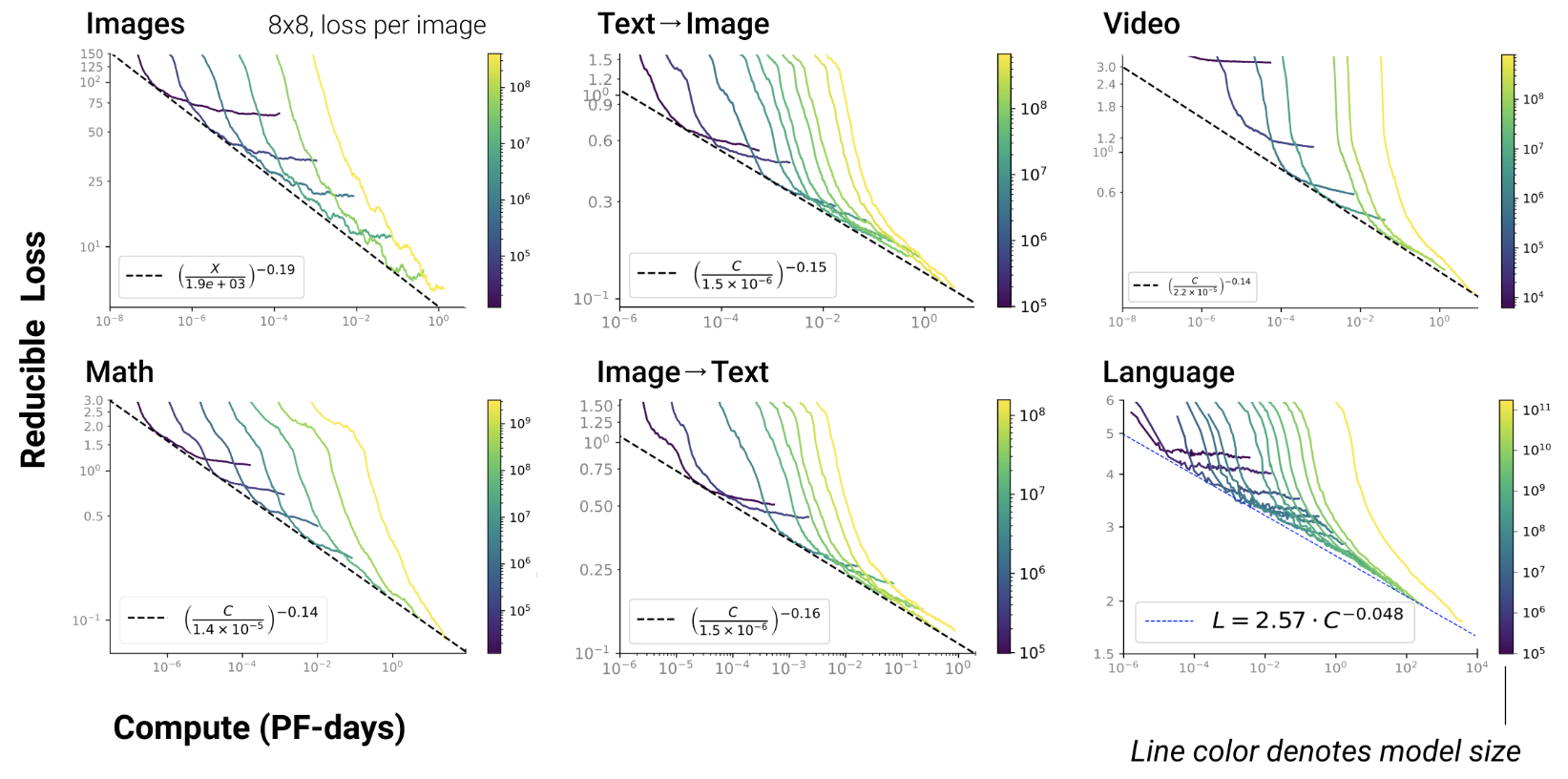
- RL, protein, chemistry…
- Scaling exist since long in ML Paper on learning curves
- But reducing test loss is linked to emergent abilities in
transformers
- Such emergence never been observed in ML before
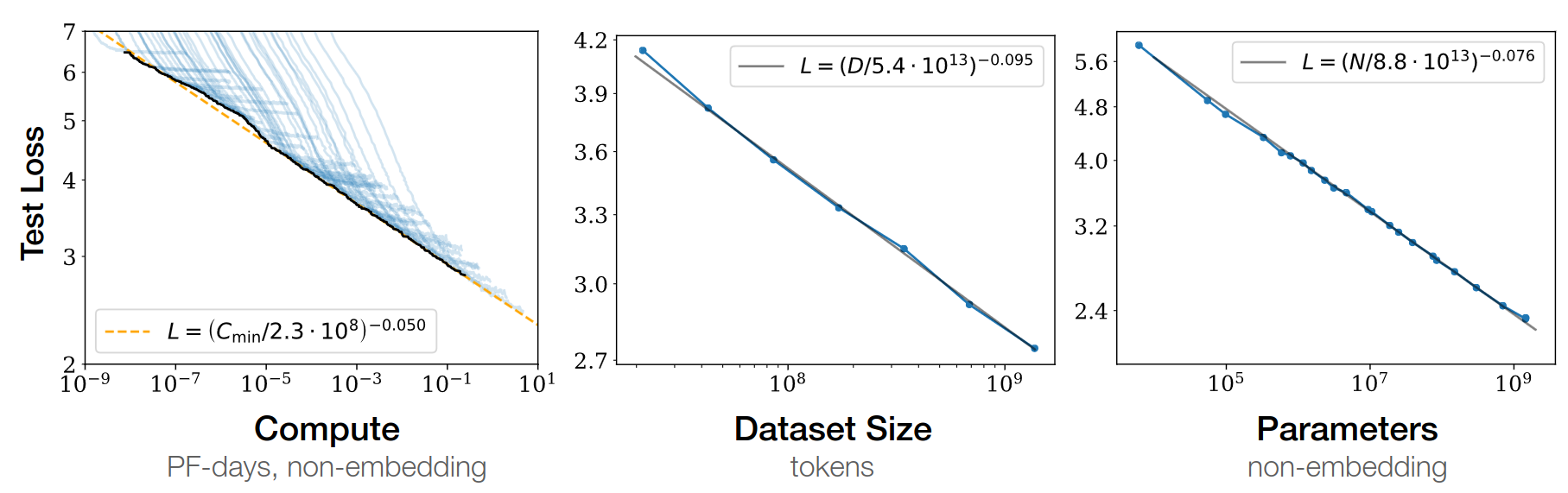
Chinchilla paper 2022
- GPT3: train on 300b tokens, and scale parameters up
- given fixed FLOPS, optimal balance btw dataset / parameters
- Lesson: need more data!
\(L(N)=\frac A {N^\alpha}\)
- \(N\) = dataset size
- \(\alpha \simeq 0.5\) (was 0.05 in GPT3 paper)
- Any really useful enhancement of transformers since 2017?
- FlashAttention
- Pre-layer norm
- Parallel feed-forward and attention
- Rotary + Alibi positional encodings
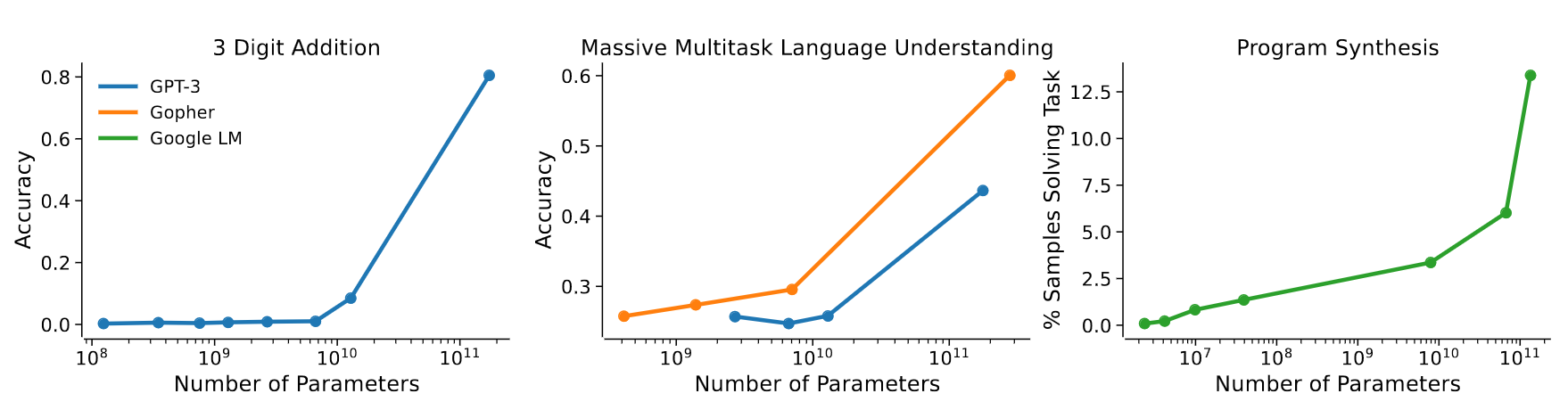
Anthropic paper 2022
- smooth scaling results from combination of abrupt emergences
Open-source LLM community
- Prompters
- Finetuners
- Trainers (Eleuther, Meta, Anthropic, Mistral…)
- Integrators (LangChain, Coala…)
- Theoreticians (academics)
Finetuning
- Catastrophic forgetting is linear! paper

- LR scheduler
- pretraining: start with large LR (big jumps), then decrease
- finetuning starts from a “deep” optimum
- redo big jumps? Will forget the previous optimum
- continue small LR? Will not learn new optimum
Limiting forgetting
- rehearsal
- regularization from initial model
- growing networks