Vision LLM4ALL
https://ia.loria.fr/orange
Christophe Cerisara, chercheur CNRS: cerisara@loria.fr
![]()
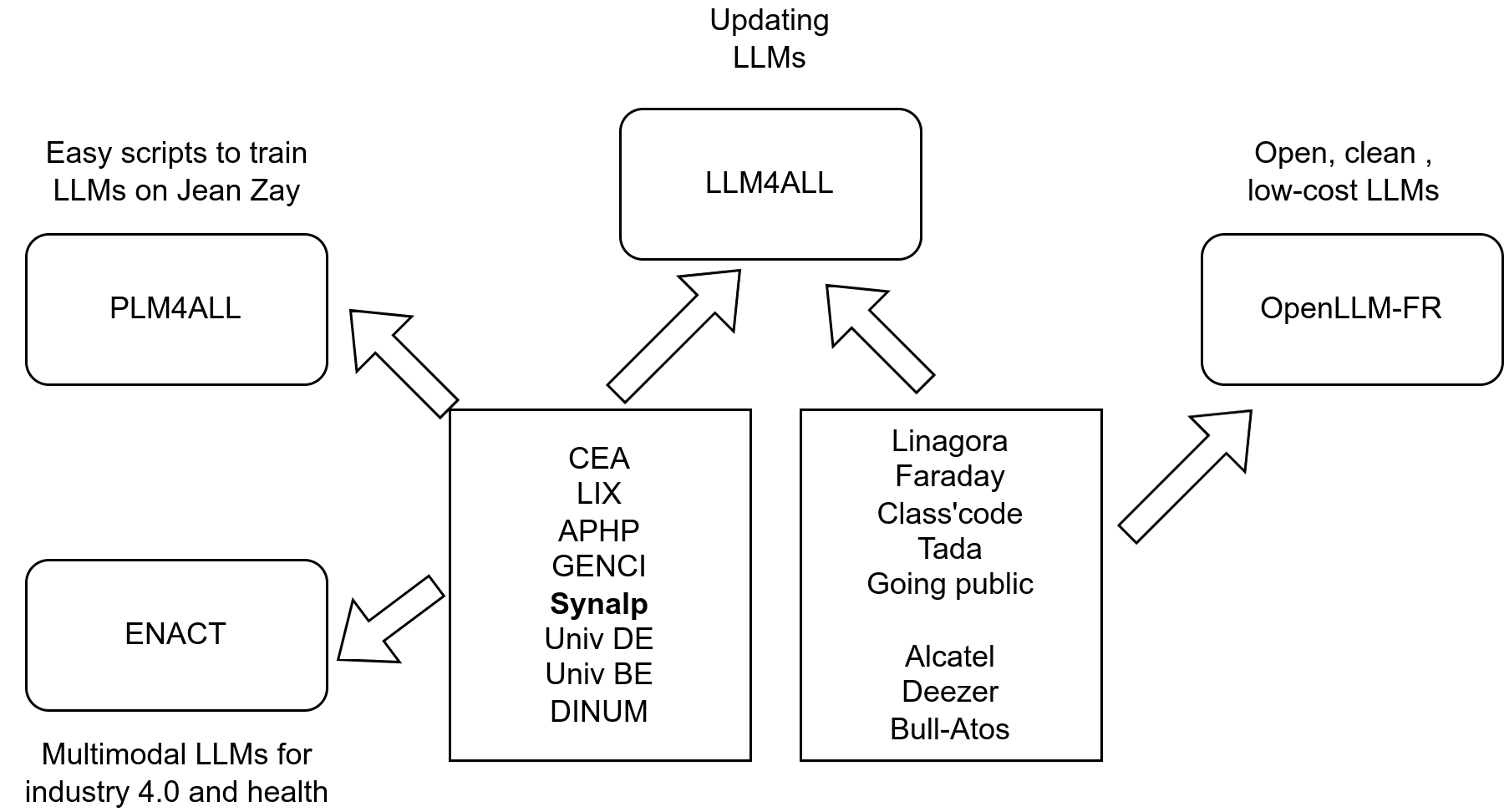
LLM4ALL
- FR Project (42 months, 1.4M€)
- partners: LORIA, LIX, APHP, Linagora, support from Huggingface
- Goals:
- Train a foundation LLM continuously up-to-date, at reasonable costs
- Applications:
- understanding meetings
- Healthcare: ER calls
Ecosystem around LLM4ALL
![]()
Focus: LLM open-source
- Reproductibility
- Dynamism, engagement (cf. “We have no moat”)
- Performances improving fast:
La communauté LLM Open-Source en France
En voie de spécialisation:
- Fondateurs: Meta, Eleuther, LightOn, Mistral…
- Prompteurs: CoT, PoT, AoT…
- Finetuners: 80k models on Hugginface-hub
- Intégrateurs: LangChain, Coala…
- Académiques: Pourquoi les LLMs sont aussi performants ?
les LLM, une nouvelle recherche empirique
![]()
Des observations aux prémisses de théories
- Observations:
- Mémorisation, compression, structuration et généralisation
- Capacités émergentes
- Embryons de théories: Passage à l’échelle
- Lois de Chinchilla
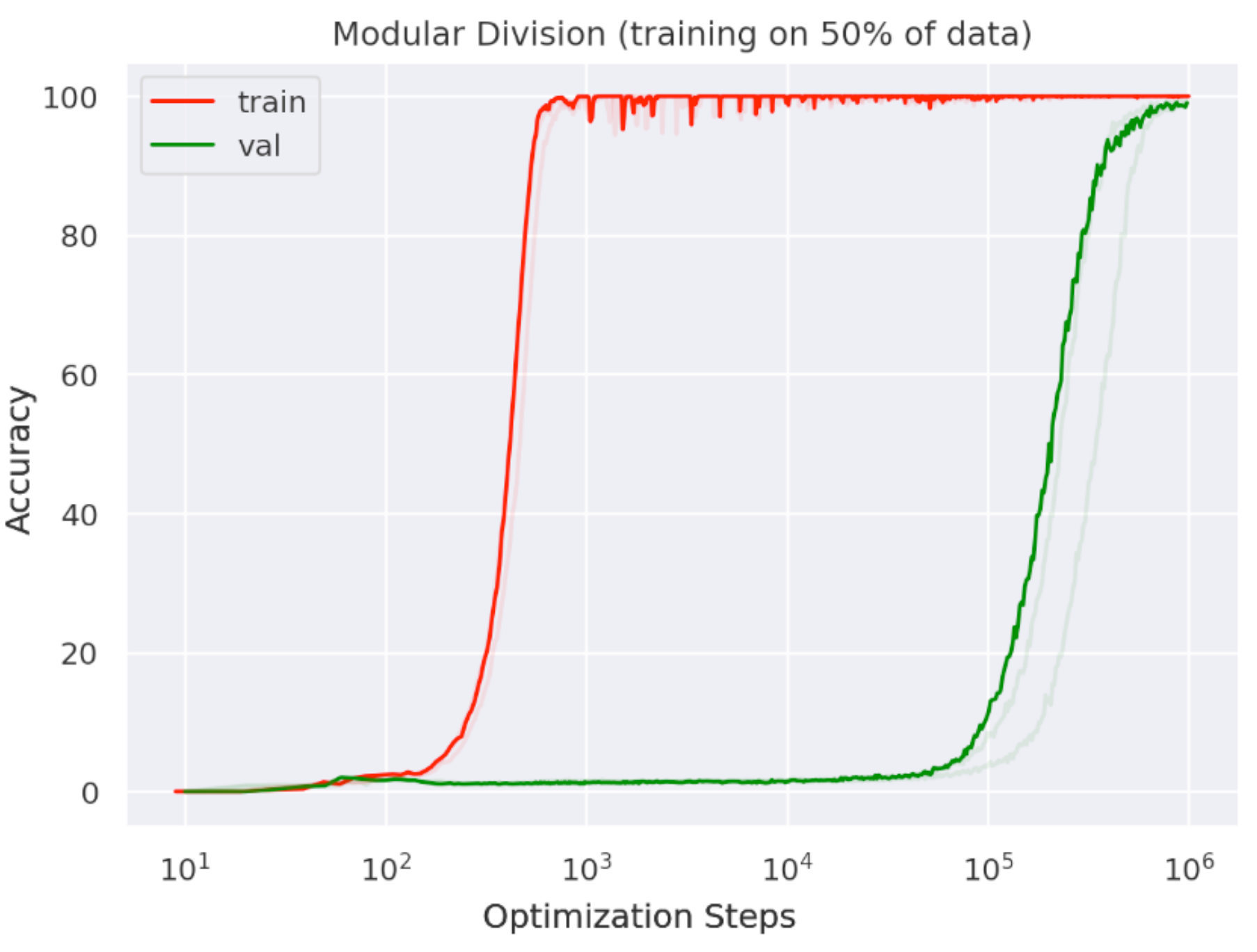
- Grokking
- Double descente
- Transitions de phases, singularité…
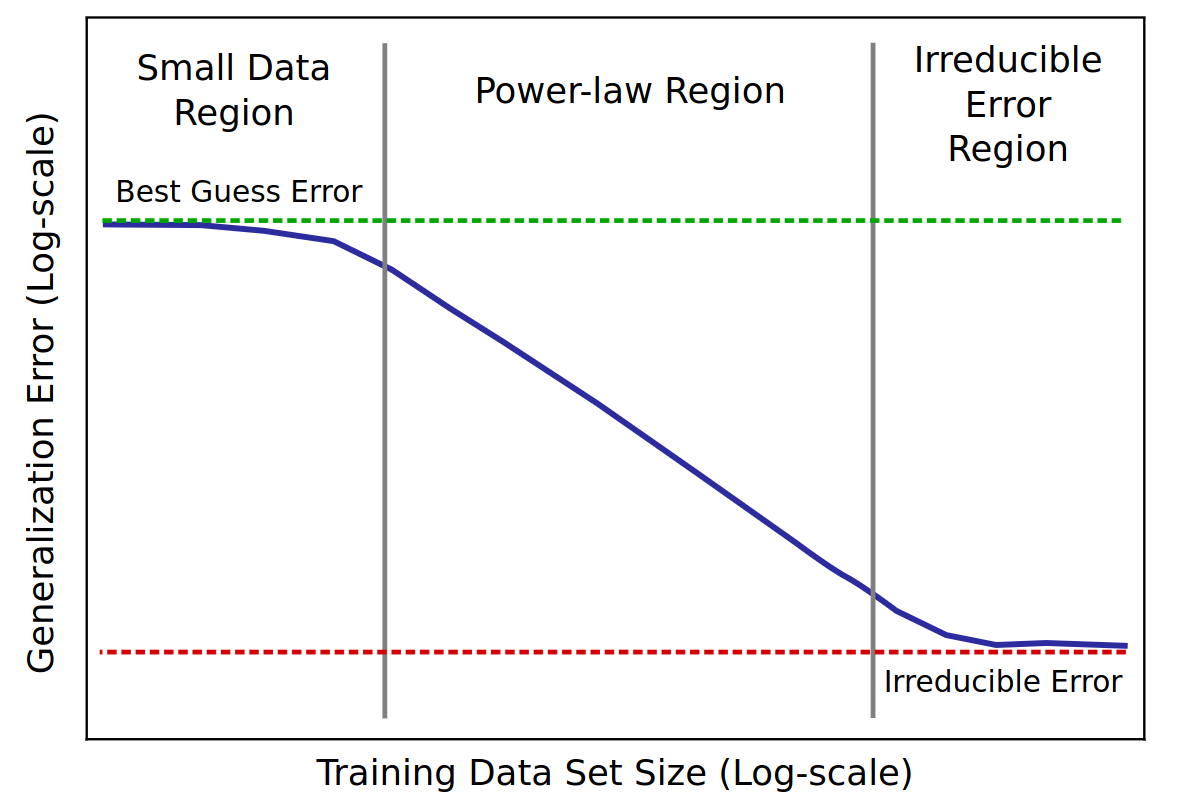
Passer à l’échelle: la genèse de Chinchilla
![]()
LLM: modèles qui passent à l’échelle
- Plus on ajoute des données
- plus le LLM stocke d’information
- mieux le LLM généralise
- scaling law = power law = \(y(x) = ax^{-\gamma} +b\)
- \(y(x) =\) test loss (erreur)
- \(\gamma\) = pente
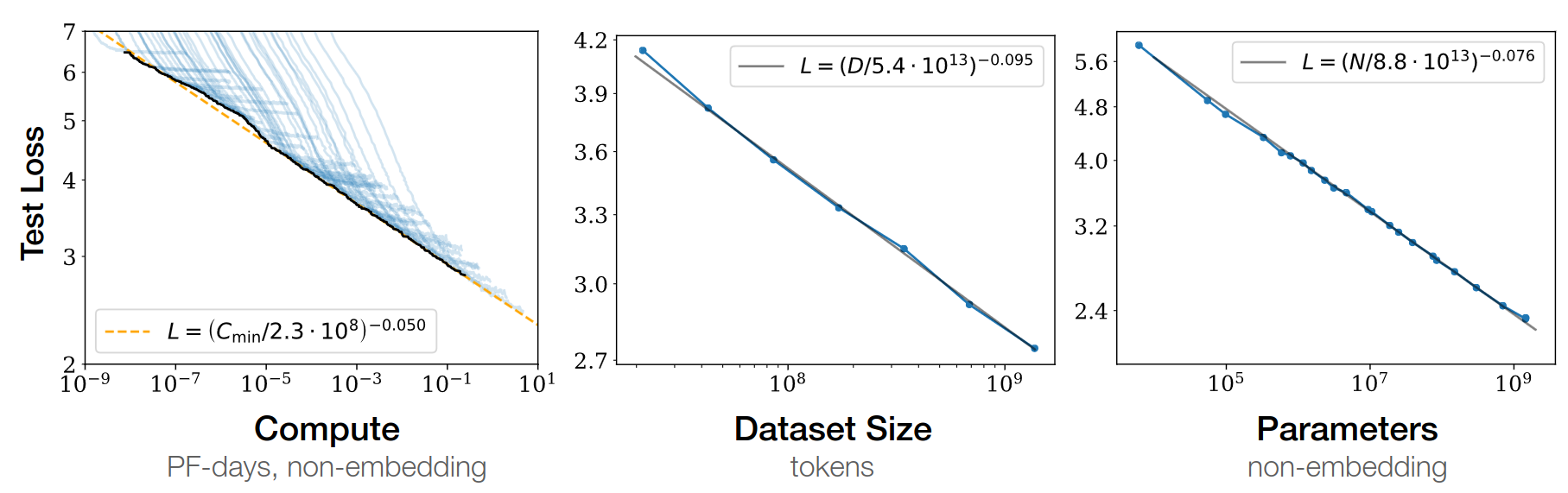
\(L=\) pretraining loss
![]()
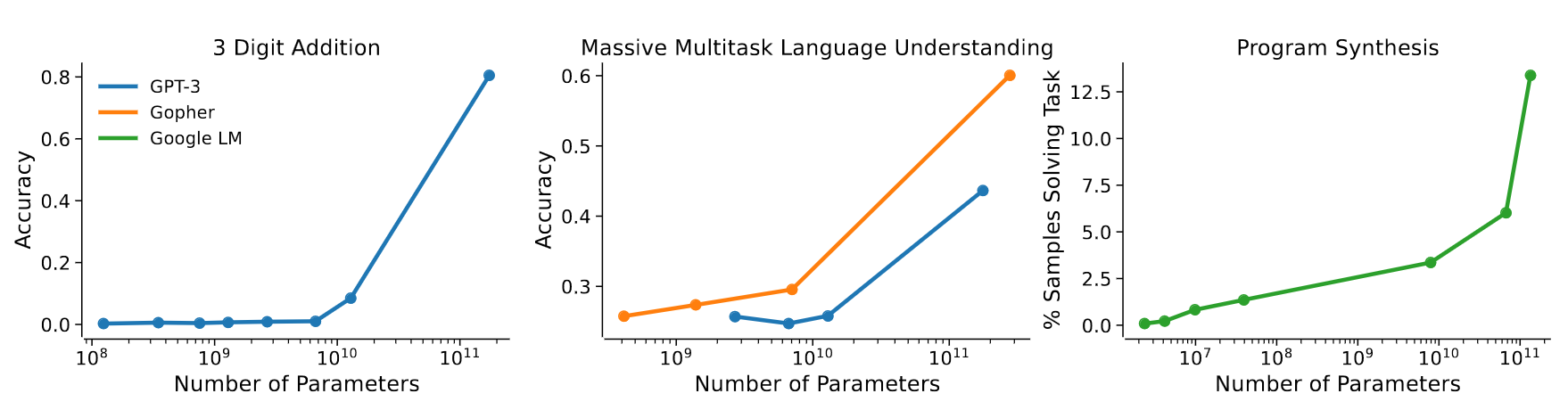
Google 2022: paper1, paper2 Flops, Upstream (pretraining), Downstream (acc on 17 tasks), Params
![]()
L’emergence de nouvelles capacités
- Les scaling laws sont théorisées en Machine Learning depuis longtemps (cf. Paper on learning curves)
- Mais c’est la 1ère fois qu’on observe qu’une scaling law est la résultante d’une succession de nouvelles capacités émergentes !
GPT3 paper 2020
- émergence de “In-Context Learning”
- = capacité à généraliser les exemples passés en entrée
- exemple:
"manger" devient "mangera"
"parler" devient "parlera"
"voter" devient
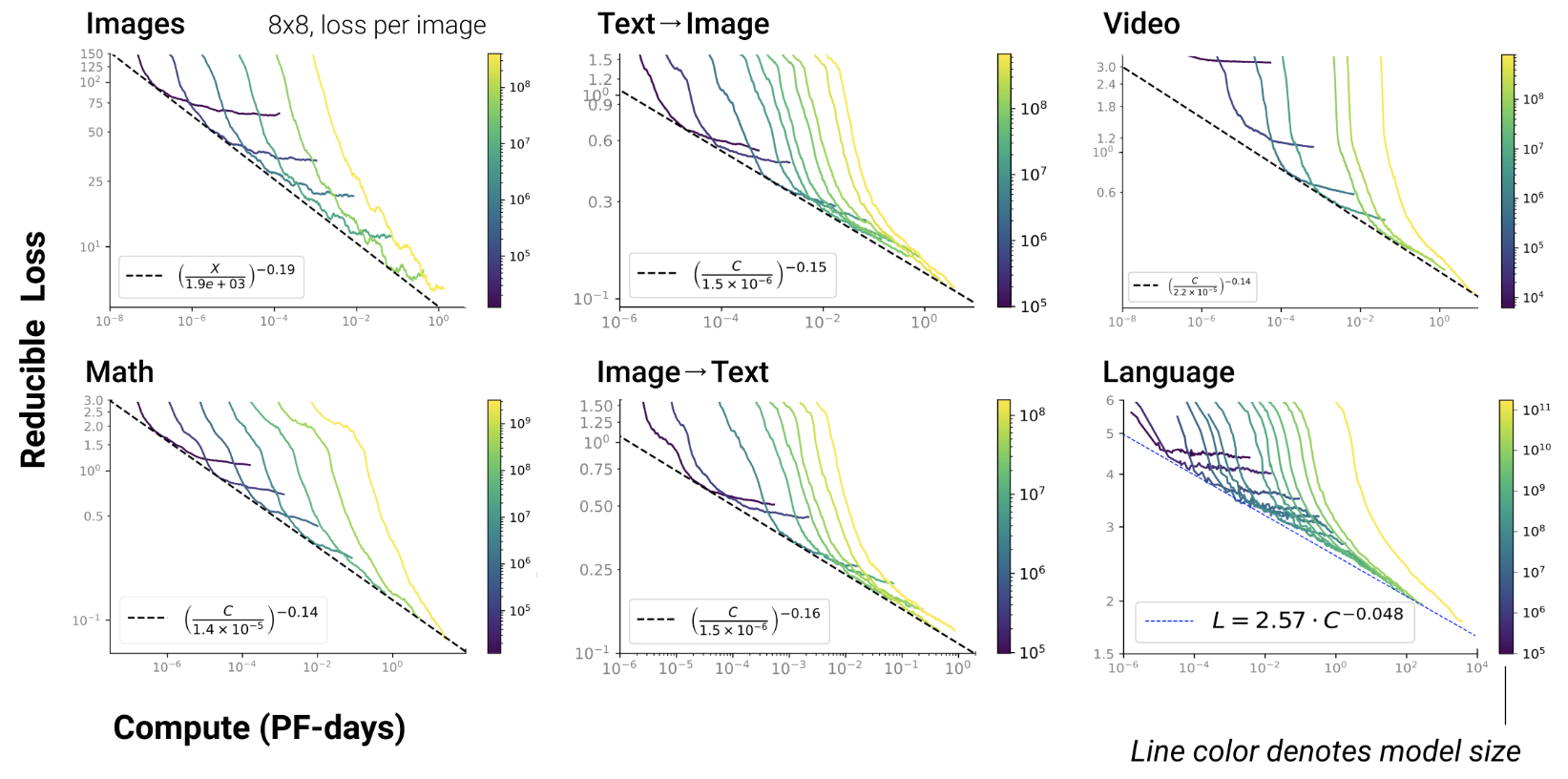
Anthropic paper 2022
- montre que la scaling law résulte de la combinaison d’émergences
![]()
Jason Wei a dénombré 137 capacités émergentes:
![]()
- In-Context Learning, Chain-of-thought prompting
- PoT, AoT, Analogical prompting
- instructions procédurales, anagrammes
- arithmétique modulaire, pbs simples de maths
- déduction logique, déduction analytique
- Intuition physique, théorie de l’esprit ?
- …
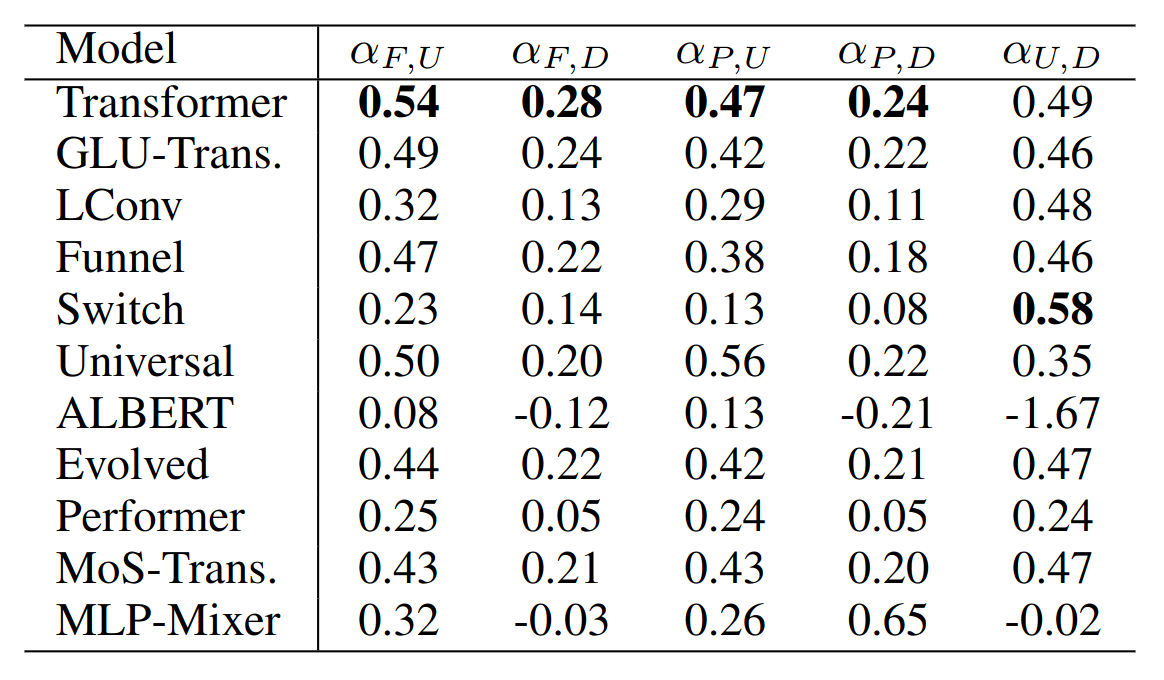
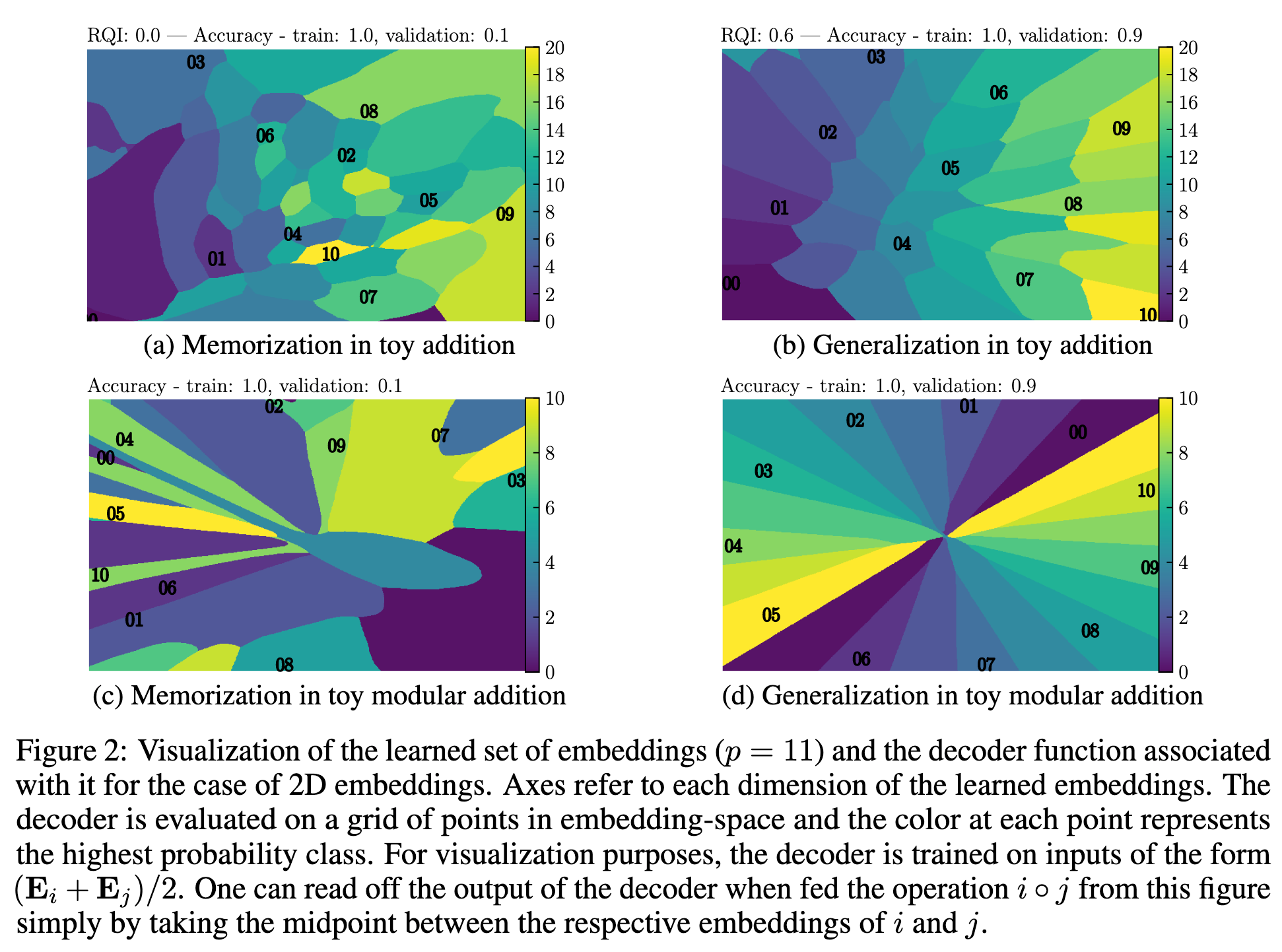
Pendant l’apprentissage, ils peuvent “brusquement” réordonner leur espace de représentation
![]()
Challenges
- Pre-training costs: Llama2-70b = $5M
- How to reduce these costs?
- Break the scaling laws!
- Hard to beat the transformer
- Cleaning data?
- Continual learning?
Continual Learning
- Challenges:
- Catastrophic forgetting
- Evaluation: cf. realtime-QA
- Data drift towards LLM-generated texts (LIX)
- How to restart training?
Catastrophic forgetting
![]()
There’s some hope though…
Continual training
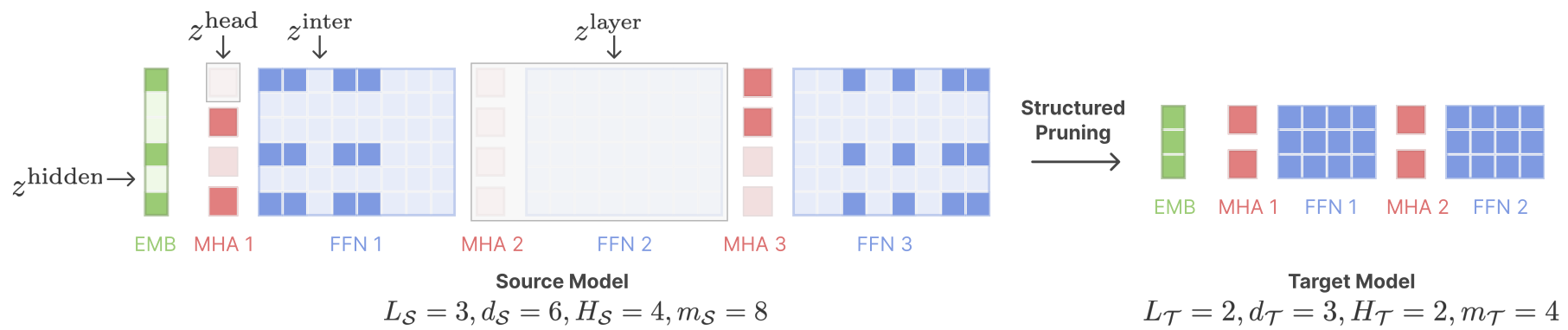
- Sheared Llama (Princeton, 2023)
- structured pruning + cont. training w/ batch weighting
![]()
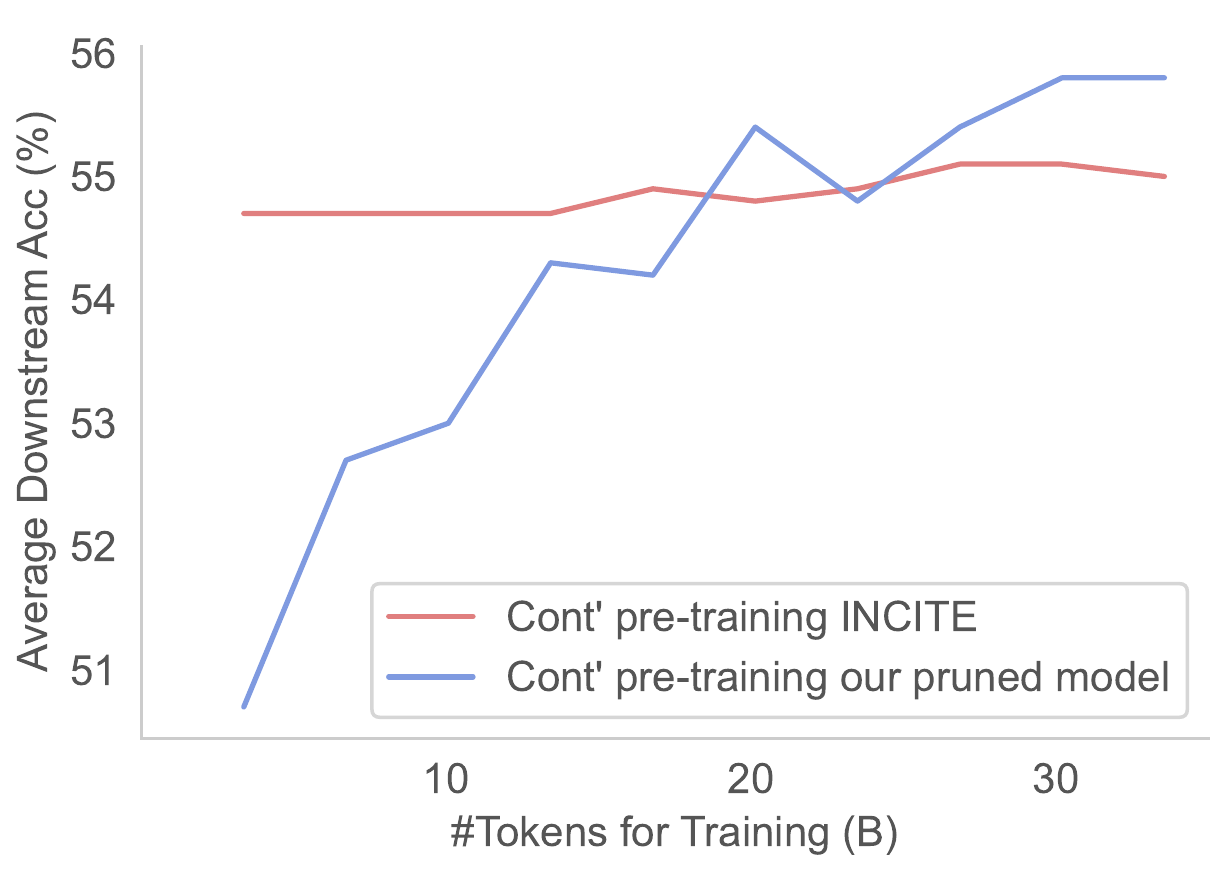
- Sheared llama: resurgence of a scaling law w/ cont. training
![]()
Initial pretrained model and AI-Act
![]()
Is Bloom a bad model?
- Bloom training led by T. Le Scao & A. Fan (PhDs in Synalp)
- Our participation to FR-MedQA (DEFT, June 2023):
- (ZSL) qBloomZ 27.9%
- (ZSL) Llama-65b 21.8%
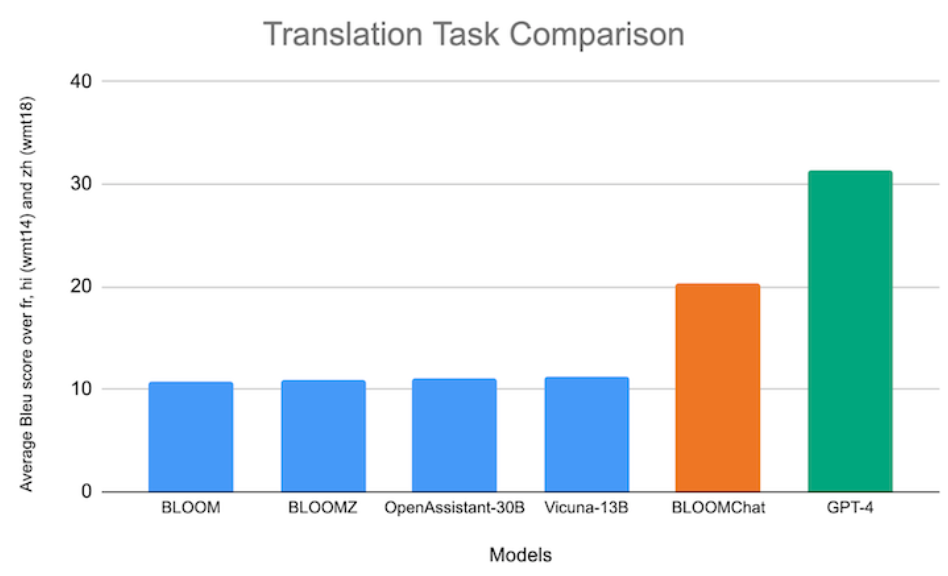
BloomChat (Together.AI 2023)
![]()
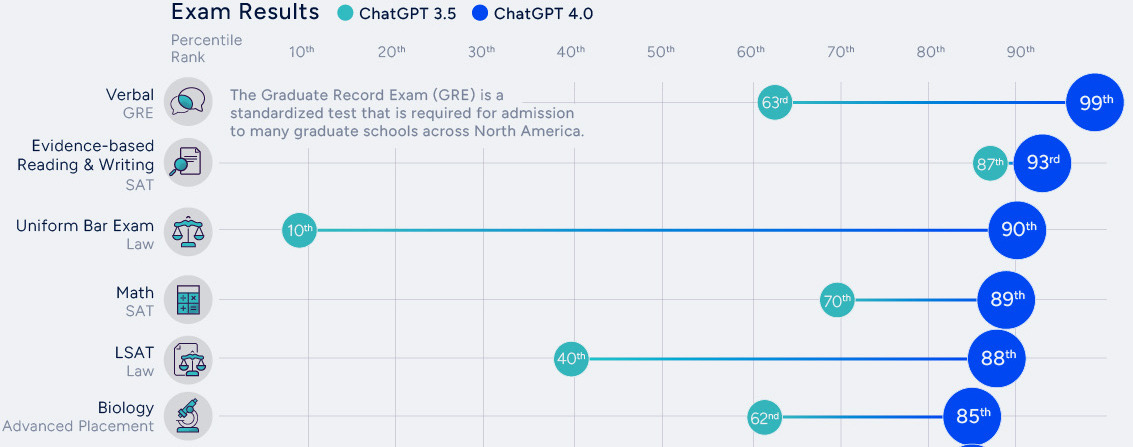
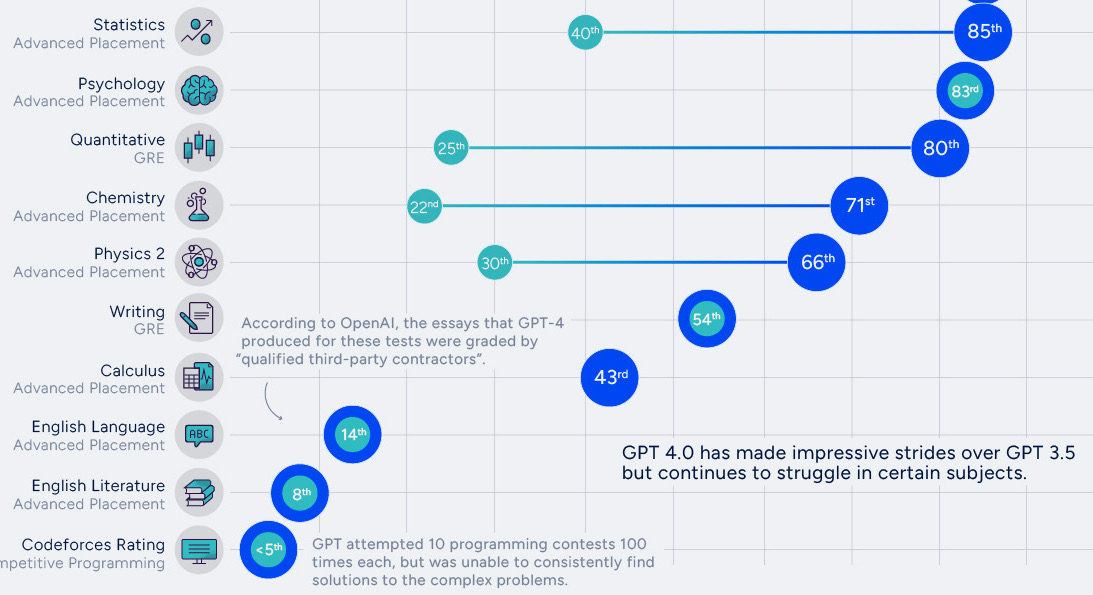
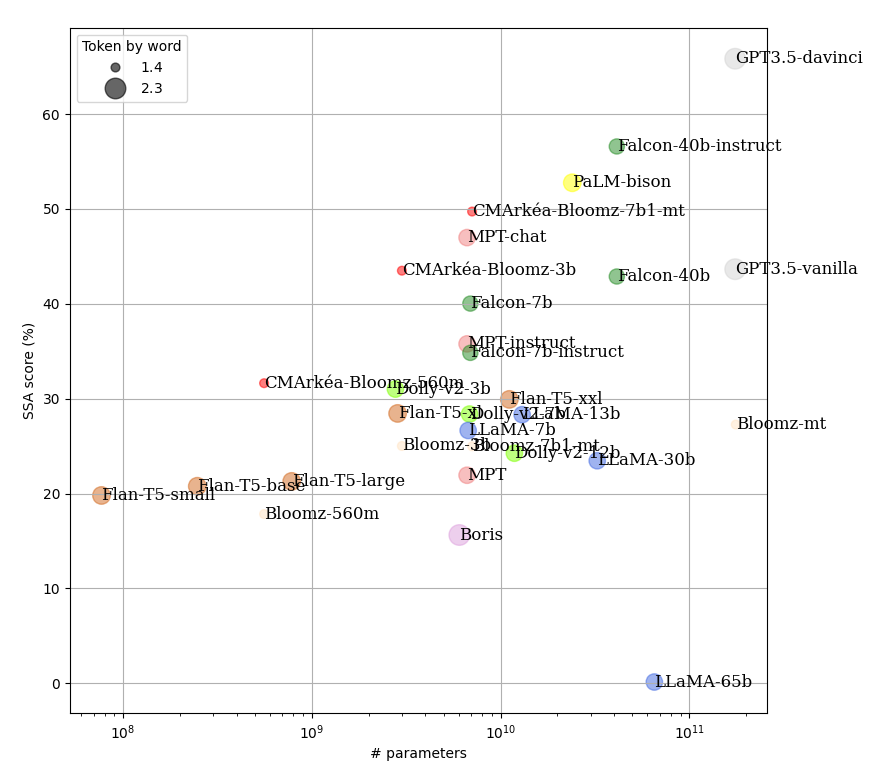
Microsoft study (Nov. 2023)
![]()
Thank you!
LLM4ALL
- Rethinking scaling laws for cont. training
- To greatly reduce training costs
- Focus on open & AI-Act compliant models
- Applications: meetings, healthcare
cerisara@loria.fr
https://ia.loria.fr/orange