Working with LLM
Challenges and solutions
Christophe Cerisara
CNRS, LORIA, Synalp team
LLM: post-Machine Learning
area?
- Limitations of ML approaches:
- Only understand vector inputs
- Unable to learn from 2 examples
- LLMs solve these limitations:
- Understand English
- Thanks to “reasoning”, can learn from 2 examples
Ex: last letter concatenation
(from Denny Zhou, Google)
| Elon Musk |
nk |
| Bill Gates |
ls |
- Obvious for humans with 2 examples
- ML approach:
- enc-dec trained on tons of labeled data
Perform last letter concatenation, as shown in these two
examples. Words: Elon Musk Answer: nk Words: Bill Gates Answer: ls
Words: Barack Obama Answer:
[…] So, the concatenation would be ka
- Requires more advanced prompting strategies with older models: CoT,
analogical prompting…
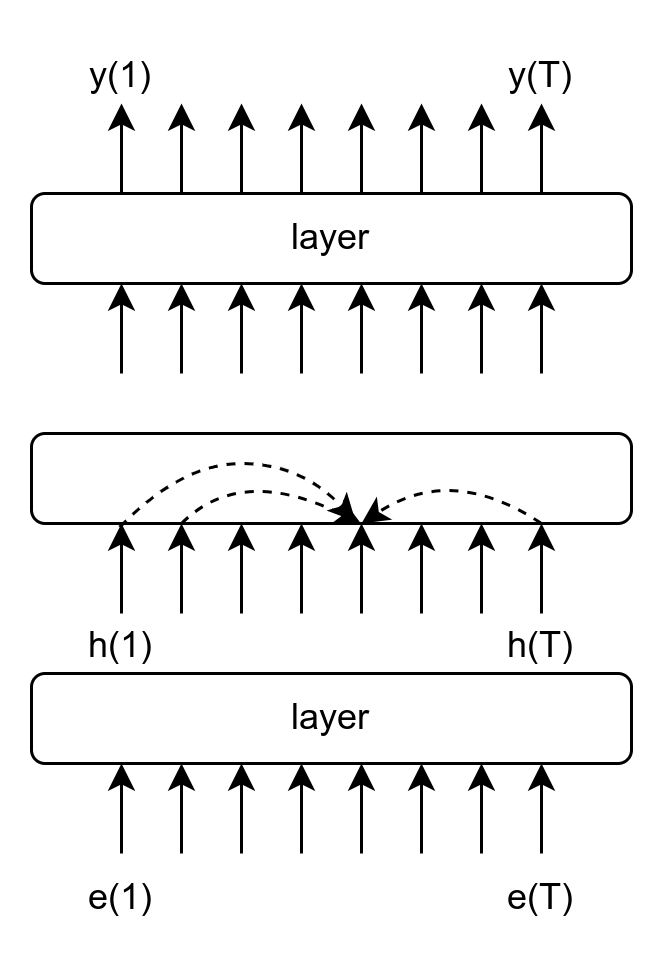
Part 1: inside the LLM…
- GPU
- Data
- Transformer
- No bottleneck of information
- Reason over layer steps
- Semi-Turing machine
- Learns to learn (2nd order-GD, TD)
- Reason over time steps
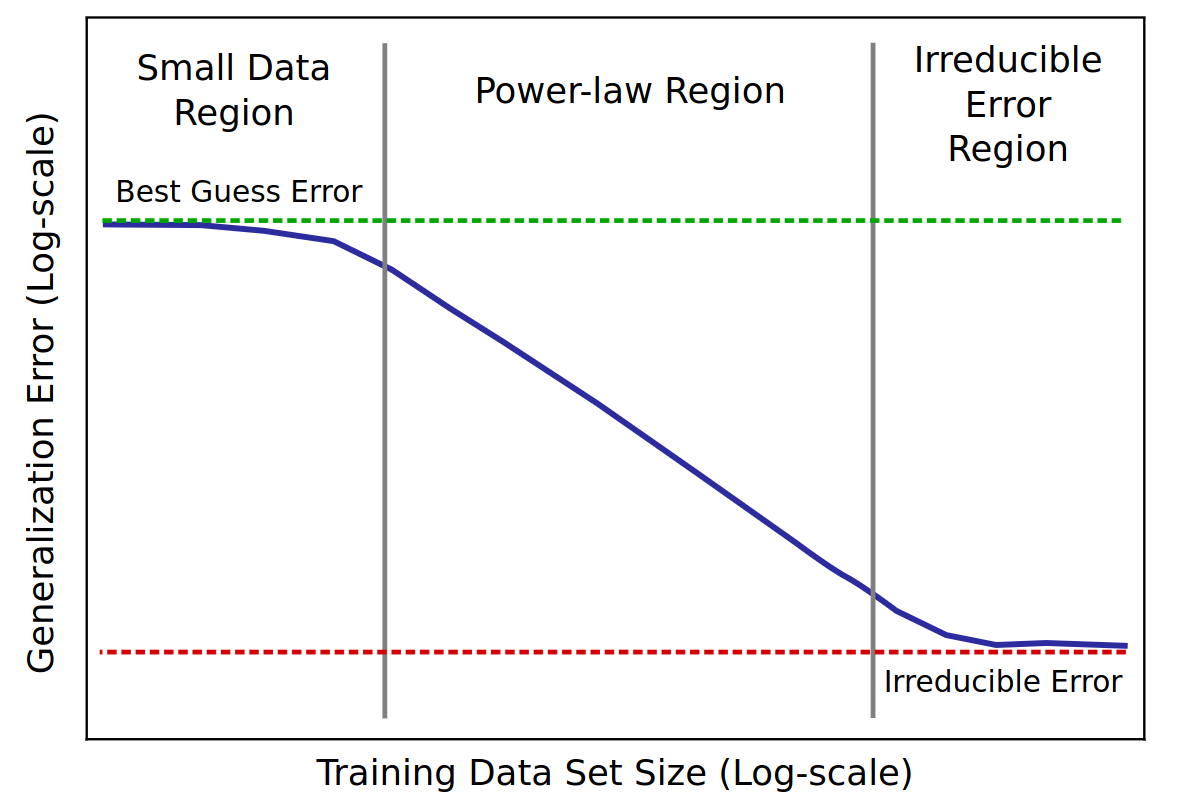
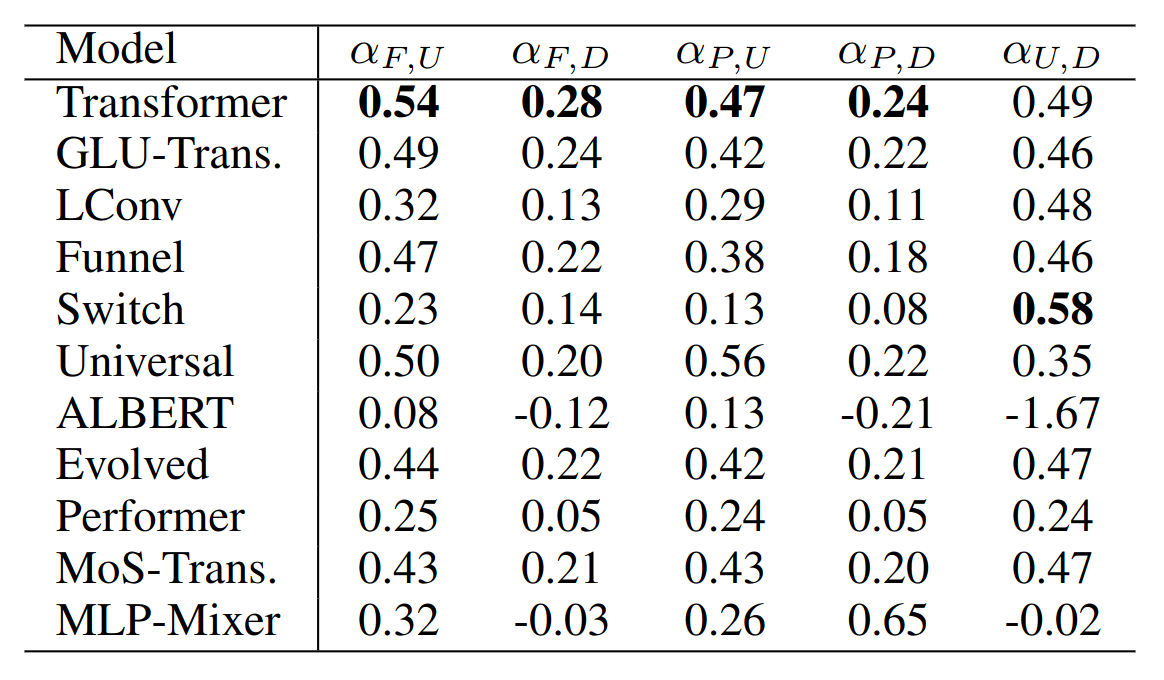
Scaling laws
- The more data you train on
- the more the LLM knows about
- the better the LLM generalizes
- scaling law = power law = \(y(x) =
ax^{-\gamma} +b\)
- \(y(x) =\) test loss
- \(\gamma\) = slope
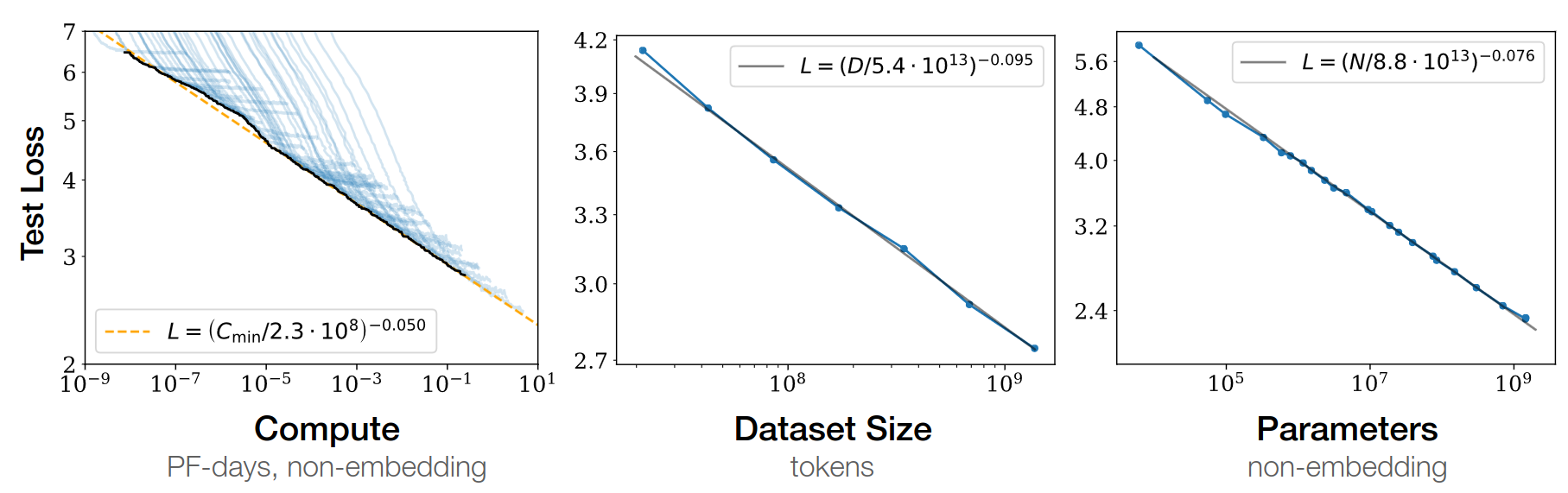
Google 2022: paper1,
paper2 Flops,
Upstream (pretraining), Downstream (acc on 17 tasks), Params
![]()
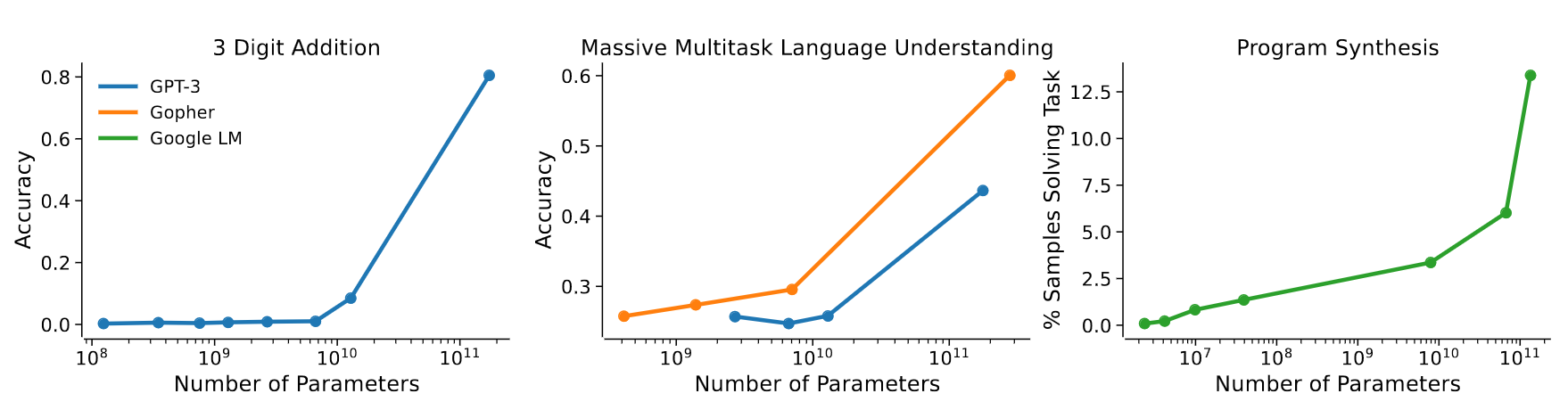
Emerging capabilities
- Scaling laws exist in Machine Learning for a long time (cf. Paper on learning
curves)
- But it’s the first time they result from emerging capabilities!
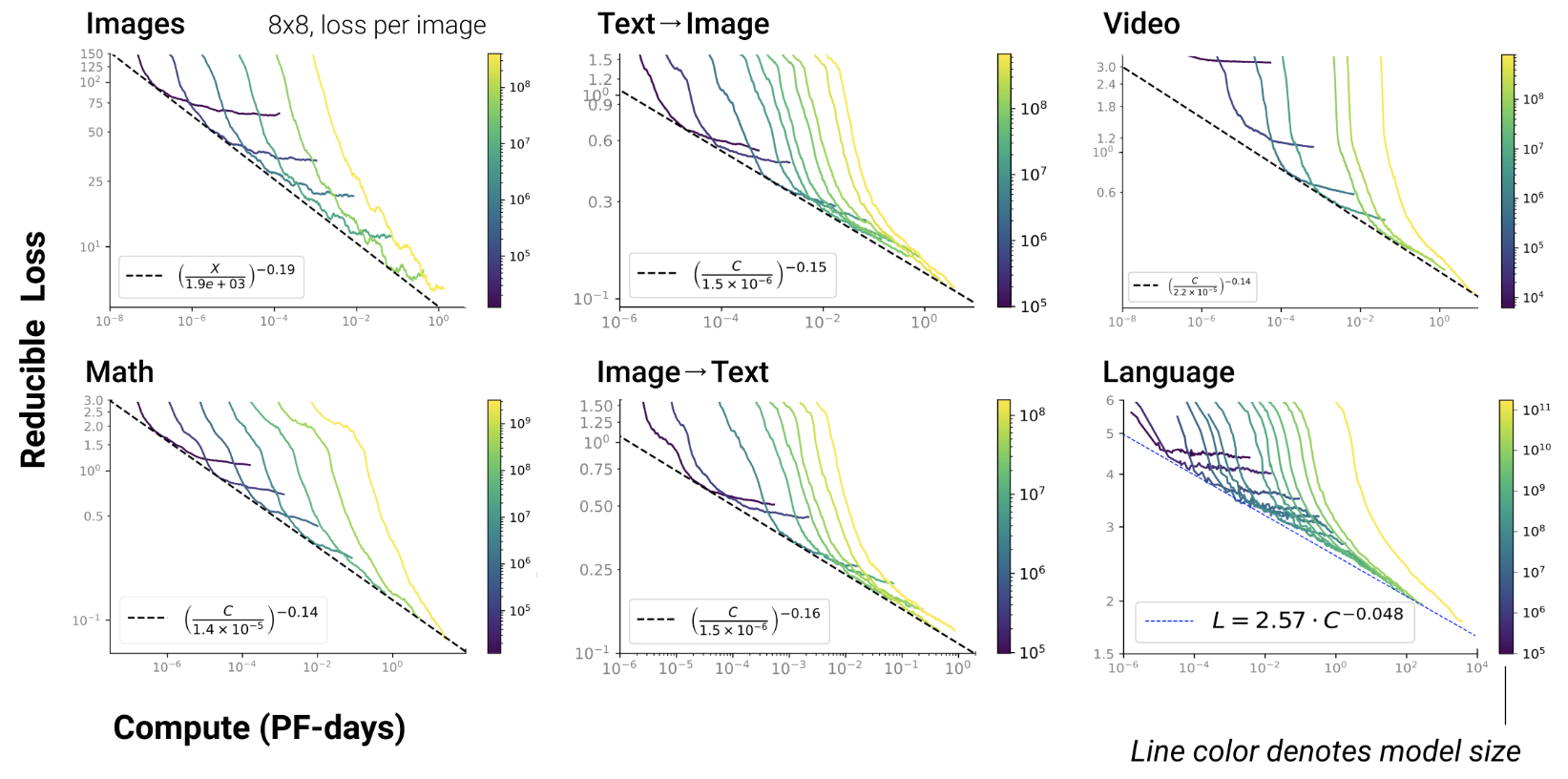
Anthropic paper
2022
- shows that the scaling law results from combination of emerging
capabilities
![]()
Jason Wei has exhibited 137 emerging capabilities:
![]()
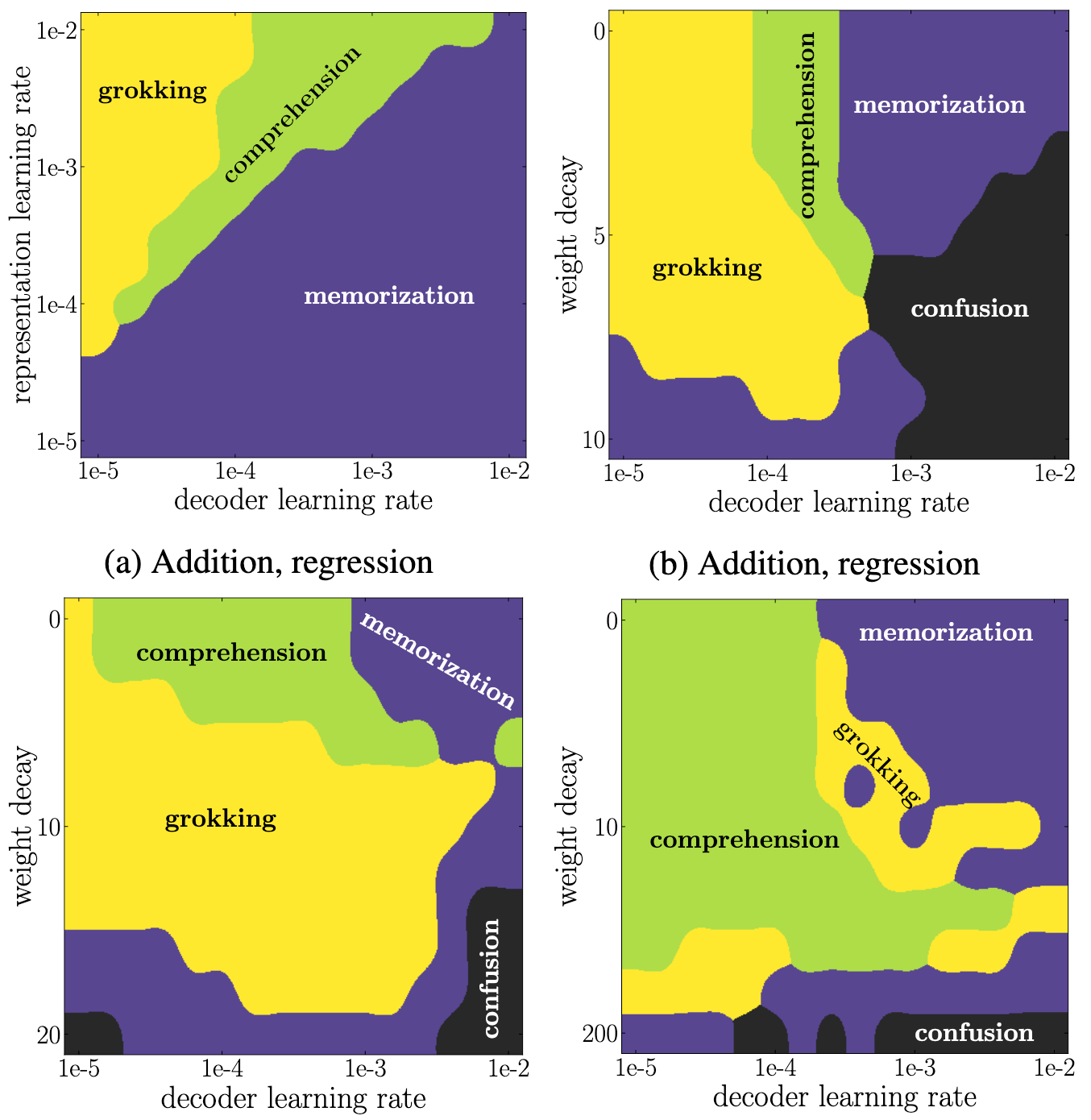
Emergence of structures
- Training \(\rightarrow\) multiple
phase transitions
- When representations becomes structured, then generalization
occurs:
![]()
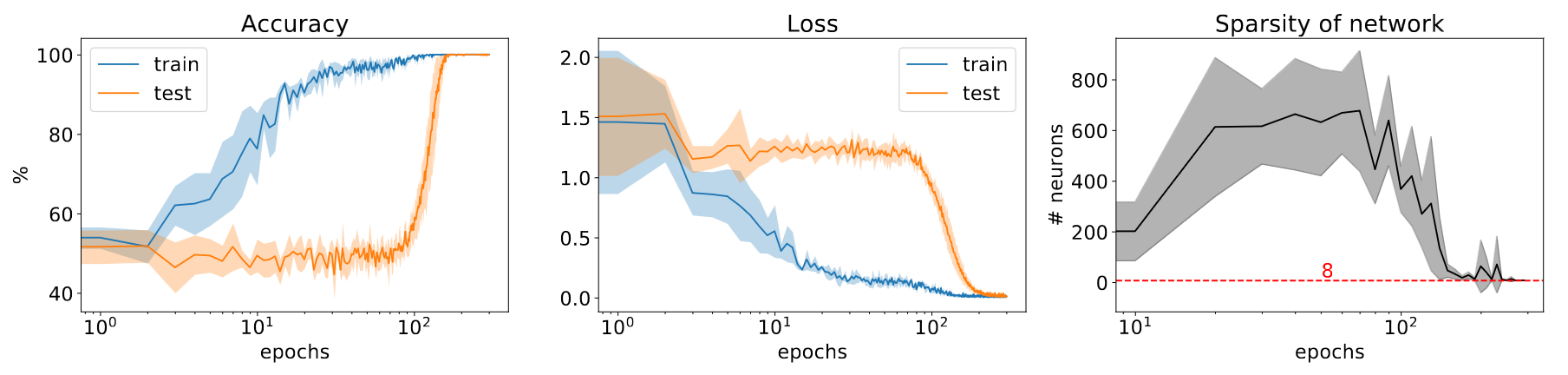
- Why do we observe phases during training?
- NYU paper
2023
- Because of competing sub-networks: dense for memorization and
another sparse for generalization
![]()
Part 2: outside the LLM
Life cycle of LLM
![]()
- Extremely important for LLMs:
- Main contributors in: pretraining, finetuning, model merging,
dissemination, efficiency, evaluation
- “We have no moat” (Google, 2023)
Remaining challenges
- LLM energy cost
- Training vs. using locally vs. LLMaaS
- LLM pruning, compression, distillation…
- Integrating LLMs into systems
- RAG, LLM agents, tools using, function calling…
Join the discussion: cerisara@loria.fr, @cerisara@mastodon.online