Efficient LLMs
Introduction
Slides: www.cerisara.fr
Christophe Cerisara: cerisara@loria.fr
Course topics
- Definition, motivation
- Which LLM to finetune?
- Costs
- PEFT methods
- sequential adapter, prefix tuning, ladder-side-networks
- Lottery-ticket sparse finetuning
- qLoRA
- finetuning and knowledge
- Prunning, compression, distillation
- Practice: language transfer
What is PEFT?
- PEFT = Parameter-Efficient Fine-Tuning
- It’s just finetuning, but cost-effective:
- only few parameters are finetuned
- cheaper to train
- cheaper to distribute
When do we need finetuning?
- Improve accuracy, adapt LLM behaviour
- Finetuning use cases:
- Follow instructions, chat…
- Align with user preferences
- Adapt to domain: healthcare, finance…
- Improve on a target task
- So finetuning is just training on more data?
- Yes:
- Same training algorithm (SGD)
- No:
- different hyperparms (larger learning rate…)
- different type of data
- higher quality, focused on task
- far less training data, so much cheaper
- not the same objective:
- adaptation to domain/style/task/language…
Pretrained LLM compromise
- Training an LLM is fundamentally a compromise:
- training data mix: % code/FR/EN…
- text styles: twitter/books/PhD…
- Pretraining data mix defines where the LLM excels
- Finetuning modifies this equilibrum to our need
- The art of pretraining:
- finding the balance that fits most target users’ expectation
- finding the balance that maximizes the LLM’s capacities +
adaptability
- e.g., pretraining only on medical data gives lower performance even in healthcare, because of limited data size and lack of variety.
- But for many specialized tasks, pretrained LLM does not give the
best performance:
- Finetuning adapts this compromise
- So finetuning is required for many specialized domains:
- enterprise documentations
- medical, finance…
- But it is costly to do for large LLMs:
- collecting, curating, cleaning, formatting data
- tracking training, preventing overfitting, limiting forgetting
- large LLMs require costly hardware to train
- For instance, finetuning LLama3.1-70b requires GPUs with approx. 1TB
of VRAM
- = 12x A100-80GB
- Can’t we avoid finetuning at all, but still adapt the LLM to our task?
If the LLM good enough, no need to finetune?
- Alternative: prompting
- “Be direct and answer with short responses”
- “Play like the World’s chess champion”
- Alternative: memory/long context/RAG
- “Adapt your answers to all my previous interactions with you”
- Alternative: function calling
- “Tell me about the events in July 2024”
Is it possible to get a good enough LLM?
- more data is always best (even for SmolLM!)
- So why not training the largest LLM ever on all data and use it
everywhere?
- Usage cost
- Obsolescence
- Data bottleneck
- So far, not good enough for most cases!
- Better approach (in 2024):
- For each task (domain, language):
- gather “few” data
- adapt an LLM to the task
- For each task (domain, language):
- Because it is done multiple times, training costs become a
concern
- Parameter-efficient training (PEFT)
Which pretrained LLM to finetune?
- Option 1: large LLM
- benefit from best capacities
- fine for not-so-much specialized tasks
- high cost
- Option 2: “small” LLM
- fine for very specialized task
- low cost
- hype: small agent LLMs, smolLM
- larger LLM \(\rightarrow\) less forgetting
Challenges
- Which LLM to finetune?
- Depends on the task and expected performance, robustness…
- Collect quality data
- Finetuning data must be high quality!
- Format data
- Format similar to final task
- FT on raw text may impact instruction following
- Track & prevent overfitting, limit forgetting
- Cost of finetuning may be high
Cost
- Cost of inference << cost of finetuning
- quantization: we don’t know (yet) how to finetune well quantized LLMs; so finetuning requires 16 or 32 bits
- inference: no need to store all activations: compute each layer output from it’s input only
- inference: no need to store gradients, momentum
- Inference can be done with RAM = nb of parameters / 2
- Full finetuning requires RAM = \(11\times\) nb of parameters (according to
Eleuther-AI), \(12-20\times\) according
to UMass
- 1 parameter byte = +1B (gradient) + 2B (Adam optimizer state: 1st and 2nd gradient moments) (see next slide)
- Can be reduced to \(\simeq
5\times\):
- gradient checkpointing
- special optimizers (1bitAdam, Birder…)
- offloading…
- Adam equations:
- \(m^{(t)} = \beta_1 m^{(t-1)} + (1-\beta_1) \nabla L(\theta^{(t-1)})\)
- \(v^{(t)} = \beta_2 v^{(t-1)} + (1-\beta_2) \left(\nabla L(\theta^{(t-1)})\right)^2\)
- Bias correction:
- \(\hat m^{(t)} = \frac {m^{(t)}}{1-\beta_1}\)
- \(\hat v^{(t)} = \frac
{v^{(t)}}{1-\beta_2}\)
- \(\theta^{(t)} = \theta^{(t-1)} - \lambda\frac{\hat m^{(t)}} {\sqrt{\hat v^{(t)}} + \epsilon}\)
- PEFT greatly reduce RAM requirements:
- can keep LLM parameters frozen and quantized (qLoRA)
- store gradients + momentum only in 1% of parameters
- But:
- still need to backpropagate gradients through the whole LLM and save all activations
- with large data, PEFT underperforms full finetuning
VRAM usage
| Method | Bits | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full | 32 | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| Full | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| LoRA/GaLore/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | 48GB | 18GB | 48GB |
Training methods
| Method | data | notes |
|---|---|---|
| Pretraining | >10T | Full training |
| Cont. pretr. | \(\simeq 100\)b | update: PEFT? |
| Finetuning | 1k … 1b | Adapt to task: PEFT |
| Few-Shot learning | < 1k | Guide, help the LLM |
Wrap-up
- With enough compute, prefer full-finetuning
- HF transformer, deepspeed, llama-factory, axolotl…
- With 1 “small” GPU, go for PEFT
- qLoRA…
- Without any GPU: look for alternatives
- Prompting, RAG…
PEFT methods
PEFT: Principle
- do not finetune all of the LLM parameters
- finetune/train a small number of (additional) parameters
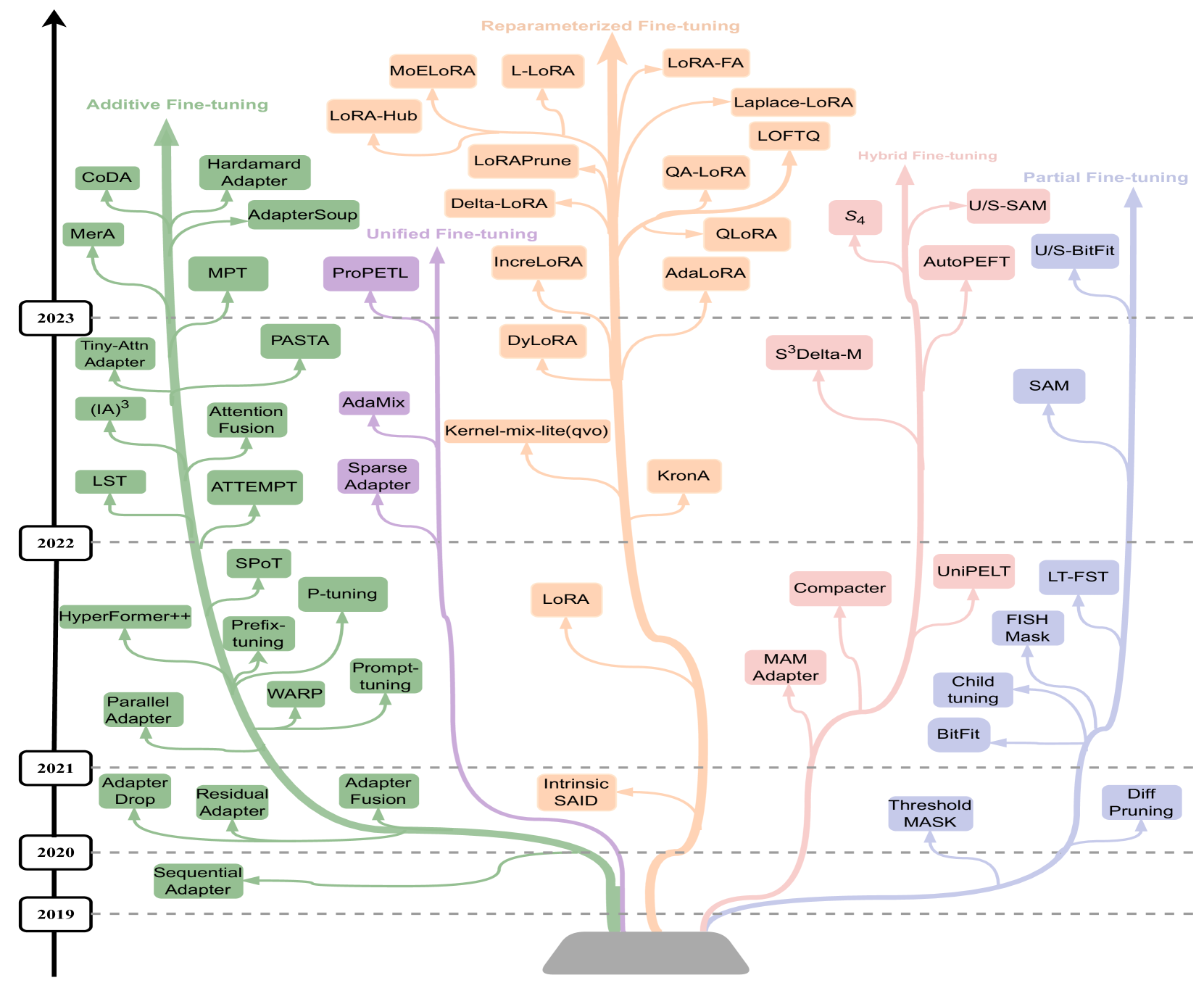
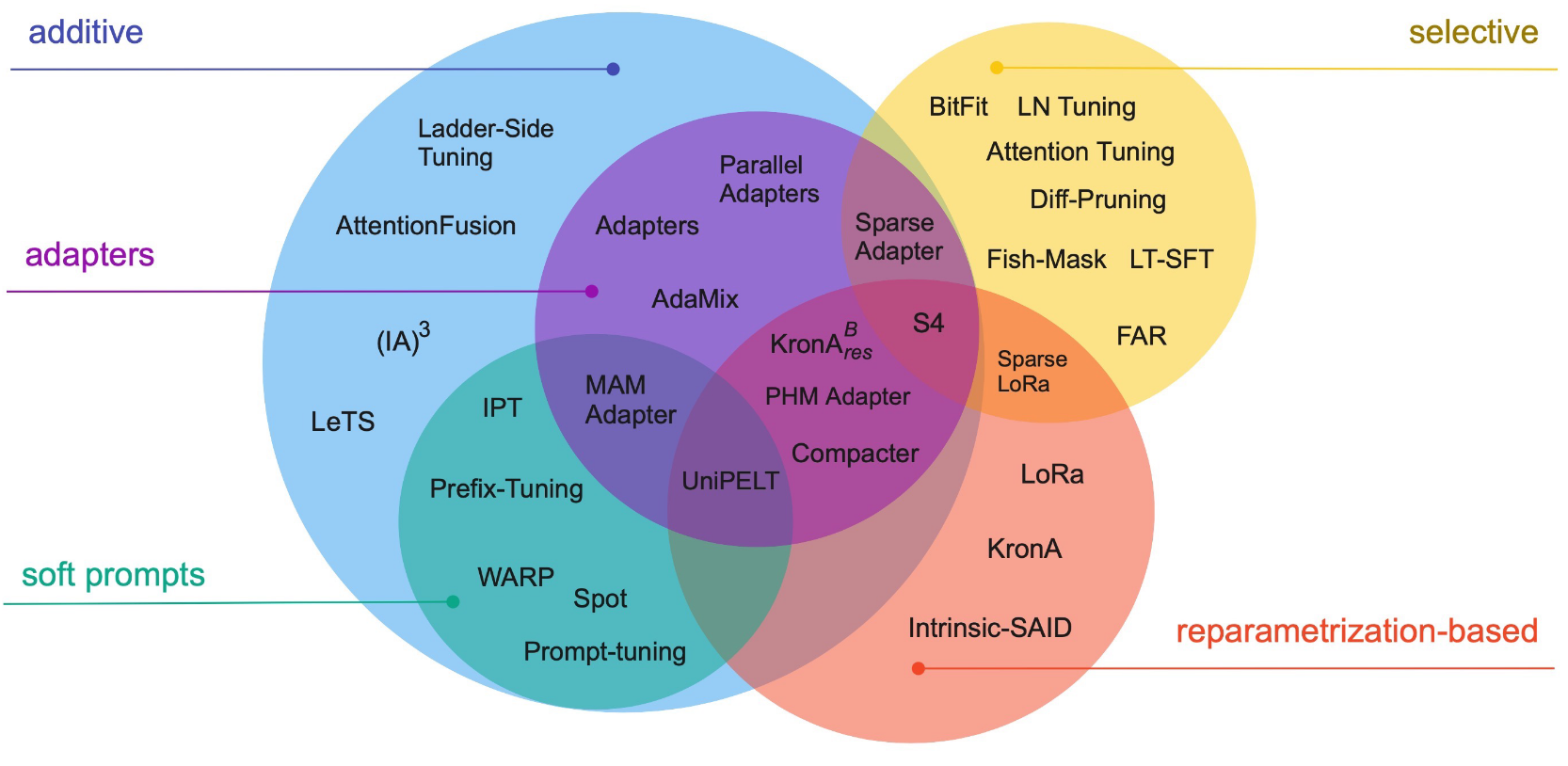
References
We’ll focus on a few
- Additive finetuning: add new parameters
- Adapter-based: sequential adapter
- soft-prompt: prefix tuning
- others: ladder-side-networks
- Partial finetuning: modify existing parameters
- Lottery-ticket sparse finetuning
- Reparameterization finetuning: “reparameterize” weight matrices
- qLoRA
- Hybrid finetuning: combine multiple PEFT
- manually: MAM, compacter, UniPELT
- auto: AutoPEFT, S3Delta-M
- Unified finetuning: unified framework
- AdaMix: MoE of LoRA or adapters
- SparseAdapter: prune adapters
- ProPETL: share masked sub-nets
Sequential adapters
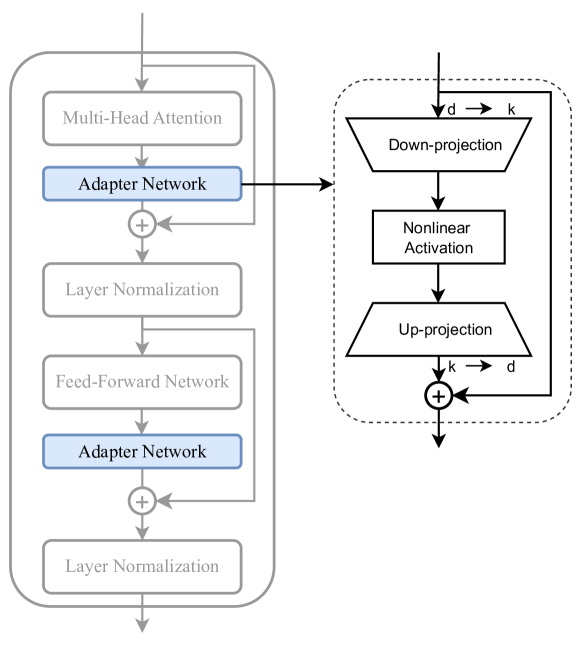
\[X=(RELU(X\cdot W_{down})) \cdot W_{up} + X\]
with
\[W_{down} \in R^{d\times k}~~~~W_{up} \in R^{k\times d}\]
- Advantages:
- Collection of available adapters: AdapterHub
- Drawbacks:
- Full backprop required
- Interesting extensions
- Parallel Adapter (parallel peft > sequential peft)
- CoDA: skip tokens in the main branch, not in the parallel adapter
- Tiny-Attention adapter: uses small attn as adapter
- Adapter Fusion: (see next slide)
- Train multiple adapters, then train fusion
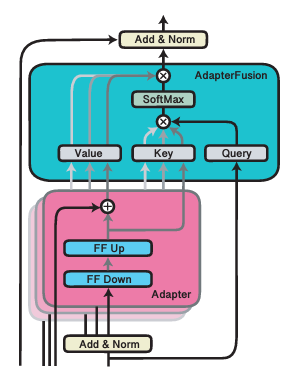
- Related to Adapter merging and LLM merging/LoRA extraction
Prefix tuning
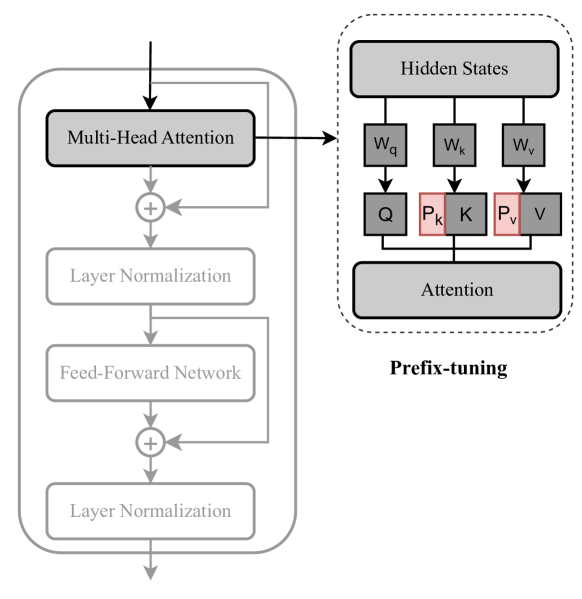
- Concat \(P_k,P_v \in R^{l\times d}\) before \(K,V\) \[head_i = Attn(xW_q^{(i)}, concat(P_k^{(i)},CW_k^{(i)}), concat(P_v^{(i)},CW_v^{(i)})\]
- with \(C=\)context, \(l=\)prefix length
- ICLR22 shows some form of equivalence:

- Advantages:
- More expressive than adapters, as it modifies every attention head
- One of the best PEFT method at very small parameters budget
- Drawbacks:
- Does not benefit from increasing nb of parameters
- Limited to attention head, while adapters may adapt FFN…
- … and adapting FFN is always better
Performance comparison

qLoRA = LoRA + quantized LLM
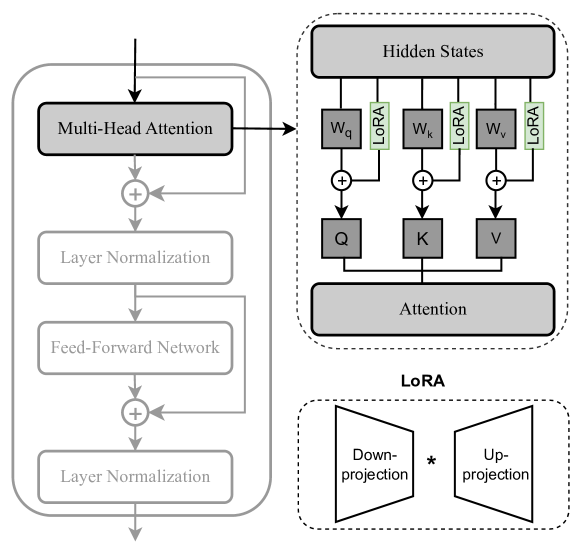
- Advantages:
- de facto standard: supported in nearly all LLM frameworks
- Many extensions, heavily developped, so good performances
- can be easily merged back into the LLM
- Drawbacks:
- Full backprop required
Adapter lib v3
- AdapterHubv3
integrates several family of adapters:
- Bottleneck = sequential
- Compacter = adapter with Kronecker prod to get up/down matrices
- Parallel
- Prefix, Mix-and-Match = combination Parallel + Prefix
- Uniformisation of PEFT functions: add_adapter(), train_adapter()
- heads after adapters: add_classification_head(), add_multiple_choice_head()
- In HF lib, you can pre-load multiple adapters and select one active:
model.add_adapter(lora_config, adapter_name="adapter_1")
model.add_adapter(lora_config, adapter_name="adapter_2")
model.set_adapter("adapter_1")Ladder-side-networks

- Advantages:
- Do not backprop in the main LLM!
- Only requires forward passes in the main LLM
- Drawbacks:
- LLM is just a “feature provider” to another model
- \(\simeq\) enhanced “classification/generation head on top”
- Forward pass can be done “layer by layer” with “pipeline
parallelism”
- load 1 layer \(L_i\) in RAM
- pass the whole corpus \(y_i=L_i(x_i)\)
- free memory and iterate with \(L_{i+1}\)
- LST: done only once for the whole training session!
- This approach received an outstanding award at ACL’2024:
Partial finetuning
- Add a linear layer on top and train it
- LLM = features provider
- You may further backprop gradients deeper in the top-N LLM layers
- … Or just FT the top-N layers without any additional parameters
- Simple, old-school, it usually works well
- Fill the continuum between full FT and classifier head FT:
- can FT top 10%, 50%, 80% params
- or FT bottom 10%, 50% params
- or FT intermediate layers / params
- or apply a sparse mask?
Lottery-ticket sparse finetuning
- Lottery Ticket
Hypothesis:
- Each neural network contains a sub-network (winning ticket) that, if trained again in isolation, matches the performance of the full model.
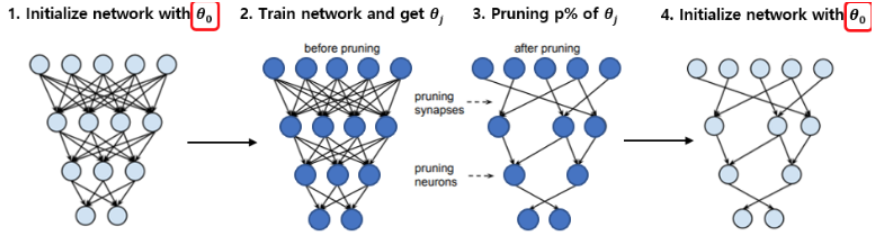
- Advantages:
- Can remove 90% parameters nearly without loss in performances (on image tasks)
- Drawbacks:
- Impossible to find the winning mask without training first the large model
can be applied to sparse FT
FT an LLM on specific task/lang
extract the mask = params that change most
rewind the LLM and re-FT with mask
sparse finetunes can be combined without overlapping!
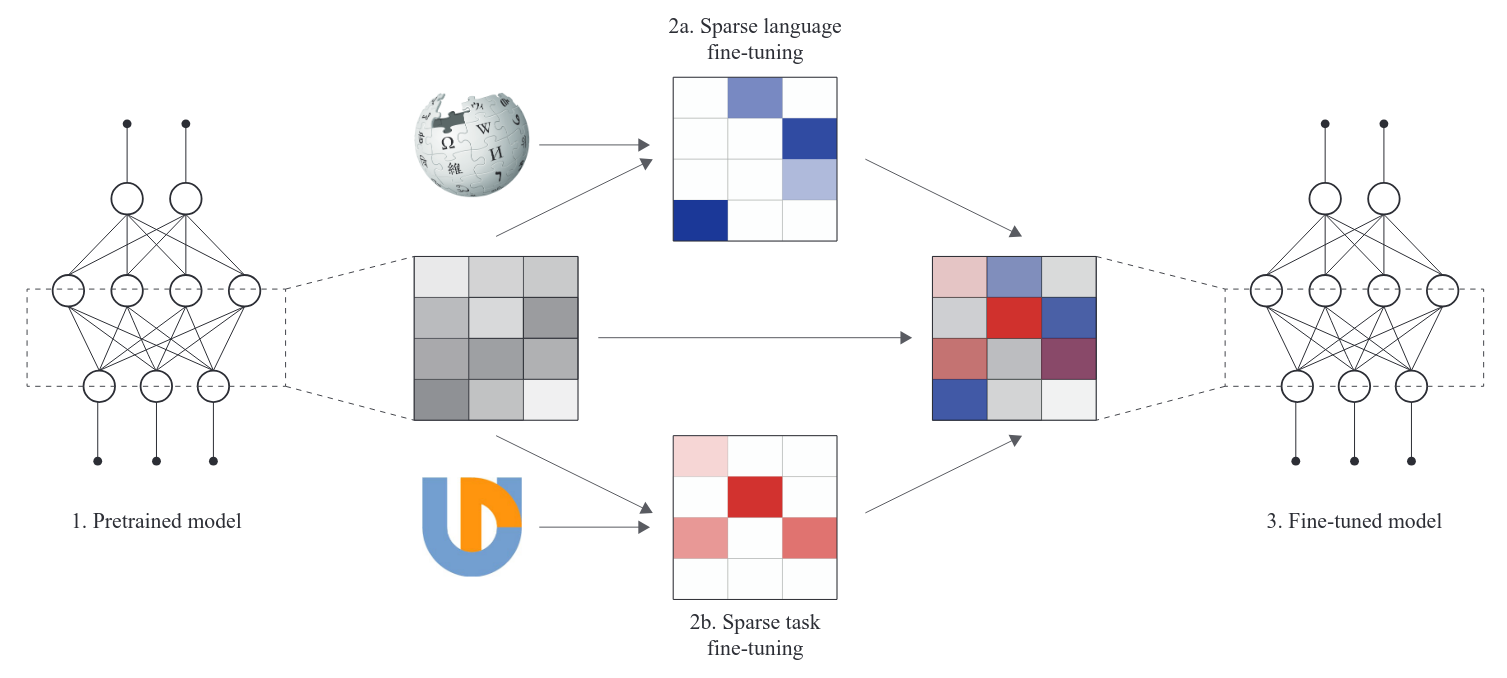
Wrap-up
- Various PEFT methods:
- Reduce model storage? RAM requirements?
- Require backprop through the LLM?
- Additional inference cost?

Finetuning (PEFT or full): advantages
- greatly improve performances on a target task, language, domain
- dig knowledge up to the surface, ready to use
- give the LLM desirable capacities: instruction-following, aligned with human preferences…
Finetuning (PEFT or full): drawbacks
- forgetting
- very slow to learn (BitDelta: Your Fine-Tune May Only Be Worth One Bit)
- increase hallucinations
Memorization, forgetting
Pretraining and FT use same basic algorithm (SGD): what is the difference?
- Difference in scale:
- Pretraining ingests trillions of tokens
- Finetuning uses up to millions of tokens
- This leads to differences in regimes / behaviour:
- Pretraining learns new information
- Finetuning exhumes information it already knows
Why such a difference in regimes?
- Because of the way SGD works:
- When it sees one piece of information, it partially stores it in a few parameters
- But not enough to retrieve it later!
- When it sees it again, it accumulates it in its weights \(\rightarrow\) Memorization
- If it never sees it again, it will be overriden \(\rightarrow\) Forgetting
- How many times shall a piece of information be seen?
- cf. Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
- Universal rule:
- an LLM can store up to 2 bit/param of information
- it requires 1000x exposure to store 1 piece of knowledge
- Finetuning hardly learns new knowledge:
- small data \(\rightarrow\) not enough exposure
- Why not repeat 1000x the finetuning dataset?
- Because previous knowledge will be forgotten!

Why doesn’t pretraining forget?
- It does!
- But by shuffling the dataset, each information is repeated all along training
- So how to add new knowledge?
- continued pretraining: replay + new data
- RAG, external knowledge databases
- LLM + tools (e.g., web search)
- knowledge editing (see ROME, MEND…)
Take home message
- PEFT is used to adapt to a domain, not to add knowledge
- RAG/LLM agents are used to add knowledge (but not at scale)
Prunning, compression, distillation
- Finetuning/PEFT keep the same model size
- Smaller LLMs are desirable for deployment; what is best?
- Train a small-LM from scratch?
- Reduce the size of a LLM?
Model size reduction
- Best method: quantization
- Astonishing method: pruning (Lottery ticket)
- Principled method: compression (LoRA, LORD)
- Flexible method: distillation
Pruning
- Basic: magnitude pruning
- principle: remove the least important parameters
- = parameters with smallest magnitude
- can remove 10% to 20% without too much degradation
- Enhancement: iterative magnitude pruning
- magnitude pruning (e.g., -5%)
- retrain to compensate for degradation
- iterate
- Why retraining is needed? \(\rightarrow\) geometric interpretation
- Let’s consider the loss landscape:
- dim 1, 2, …, N-1: all parameters
- dim N: loss (= error) on corpus
- We want to find a minimum in this landscape
- Traditional Machine Learning theory:
- search for global optimum
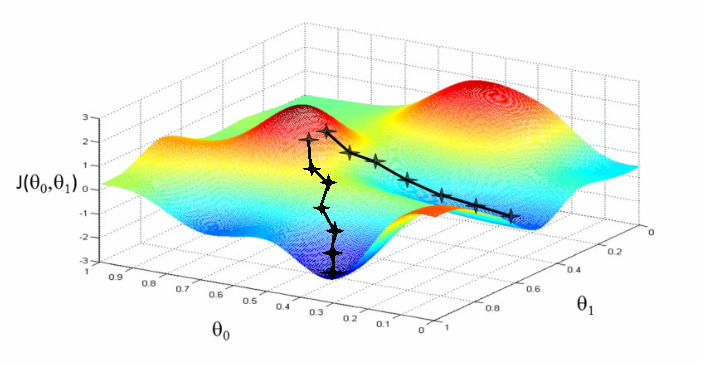
- Deep learning discoveries:
- all local minima are also global
- minina are linearly connected \(\rightarrow\) valleys
- search for local minima good enough
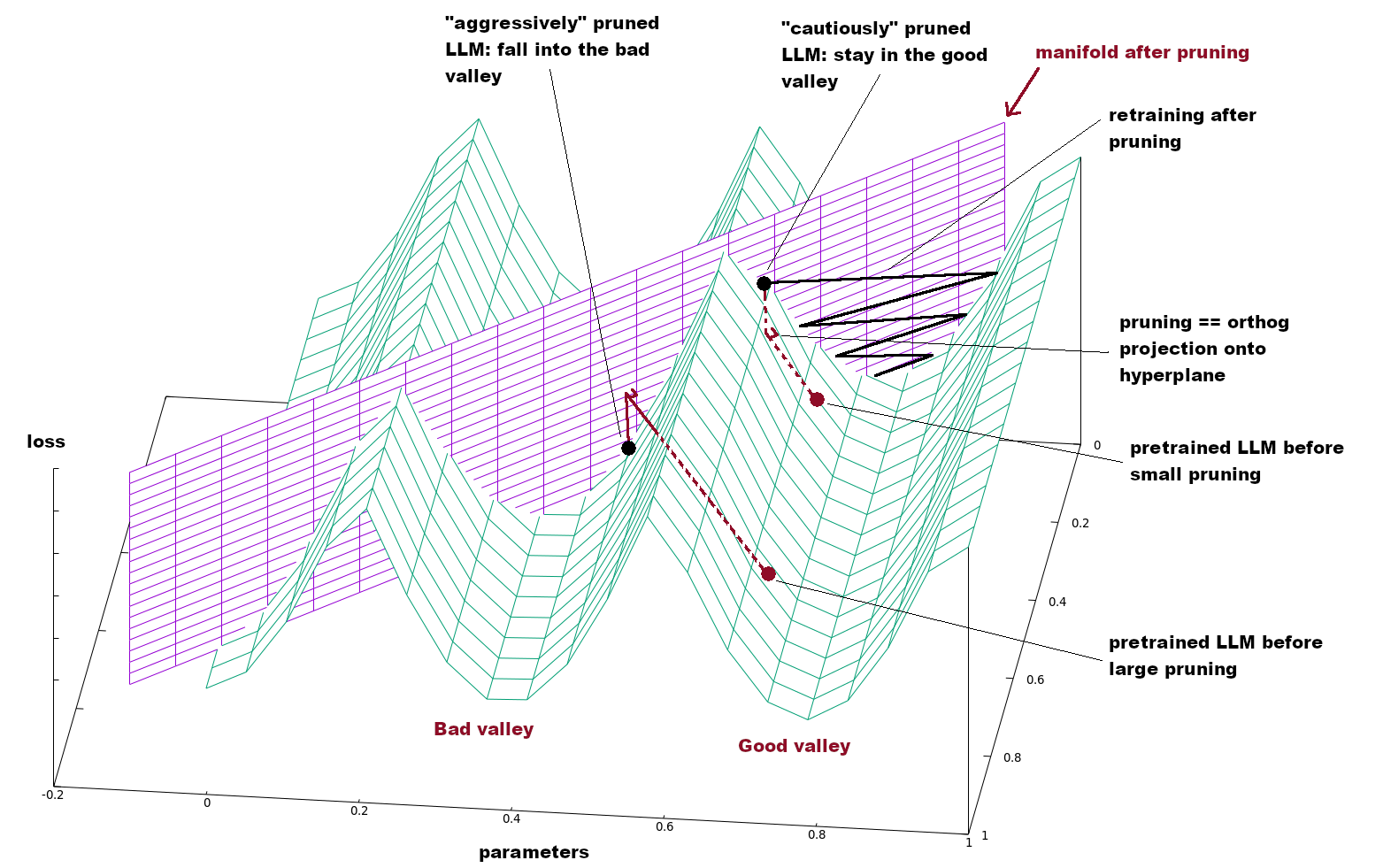
- Lottery Ticket Hypothesis suggests pruning has a huge potential
- But in practice, no savings in memory/compute!
- Unstructured pruning = remove individual parameters
- Enables largest pruning levels: Wanda: -50% parameters
- But no gain in memory nor compute!
- Structured pruning = remove blocks of parameters
- depth pruning: remove layers
- width pruning: decrease vectors’ dimensionality
- loss decreases more: requires finetuning
- SparseGPT: solve for optimal masks (MSE)
- Wanda: prune based on magnitude \(\times\) input activations
- SliceGPT: prune dims & compensates on next matrix
- LLM Pruner: prune less important global path
- ShearedLlama: IMP + continued pretraining
- Pruning wrapup:
- Active research field
- Less powerful than quantization (but complementary) to reduce size
- Preferred: quantization, distillation
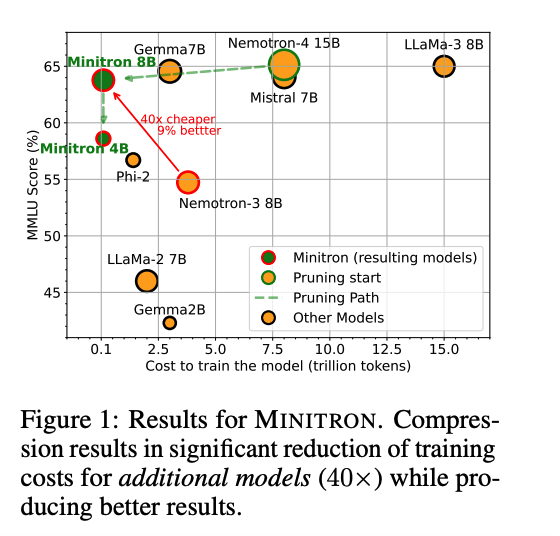
- Ex: NVIDIA minitron
- width + depth pruning
- followed by distillation (after FT teacher on distillation dataset)
Compression: low-rank
- Instead of removing parameters, replace matrix \((W\in R^{d\times d}) \simeq (A\in R^{k\times d}) \times (B\in R^{d\times k})\)
- Similar to LoRA, but replaces matrices: cf. LORD paper
- Weight matrices are high rank, but activation covariances are low rank
Compression: quantization
- Principle: no need of high precision parameters!
- 2012: 16-bits better than 32-bits, because of regularization
- True for LLM parameters (inference)
- But LLM training requires 32-bits gradients/activations
- Proposed bf16, better for LLM training
- Reducing to 8 bits requires remapping distributions
- current researches on FP8 vs. INT8 training
- 2012: 16-bits better than 32-bits, because of regularization
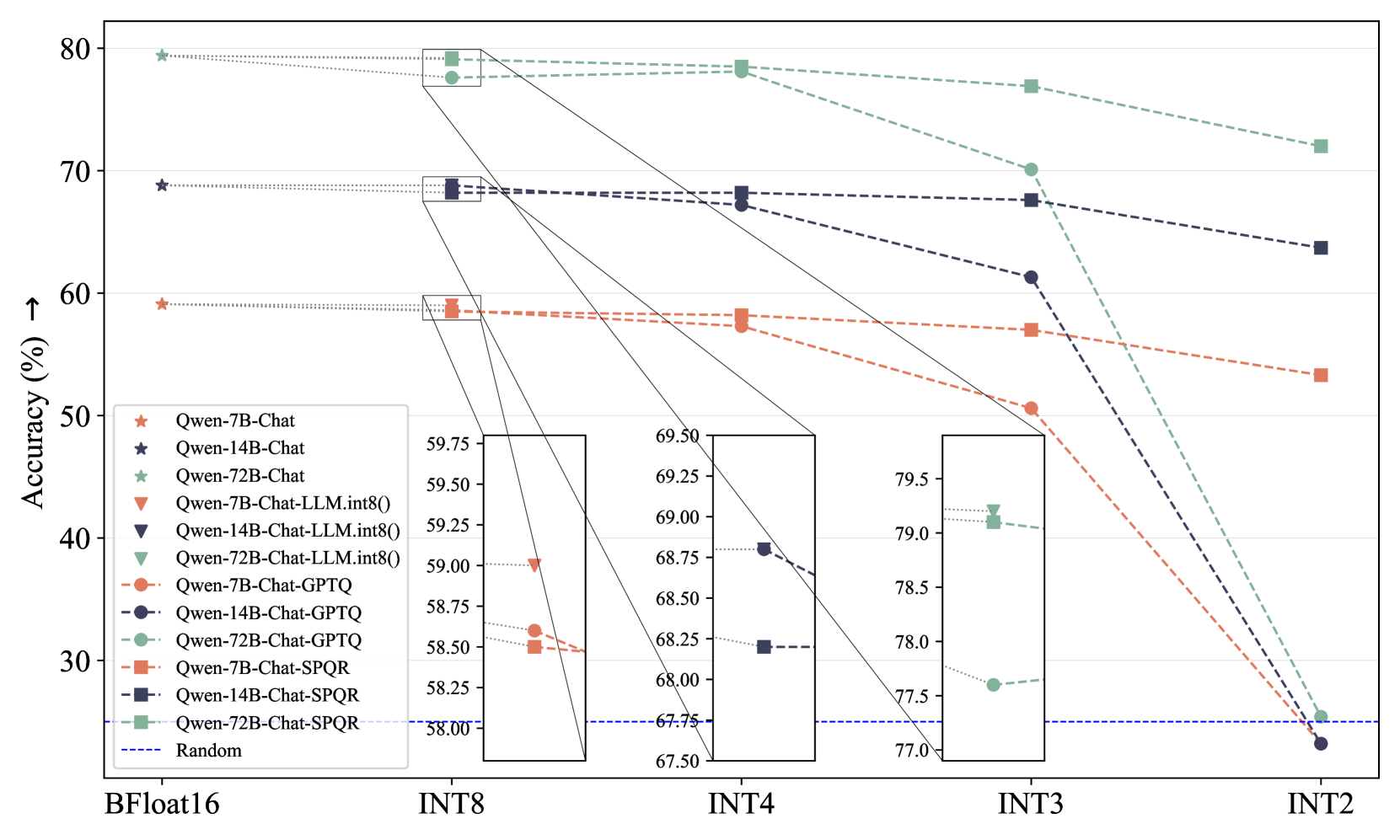
- But after training, quantizing to 4-bits is standard in 2024
- Enable local usage of LLMs: llama.cpp, llamafile, ollama, vllama…
- Quant libs: bits&bytes, gptq, awq…
- Quantized file format: (GGML), GGUF models
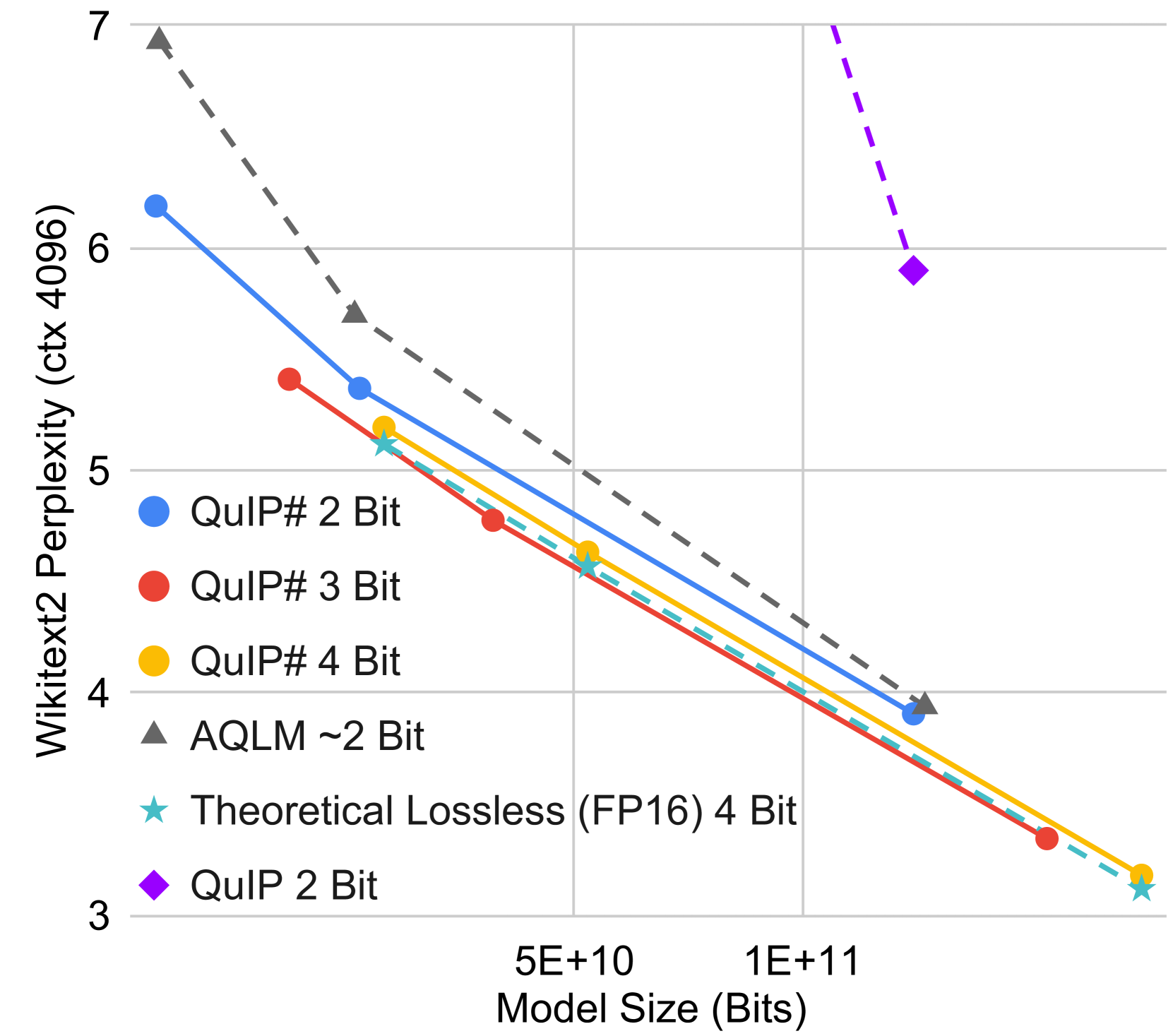
- Research for inference on 2 bits, even ternary LLMs
- WIP: Non-uniform compression, 3 bits (QuIP#), 2.5 bits, ternary, 1 bit
Distillation
- On a (unlabeled) dataset, a (large) teacher LLM outputs labels, logits, latent representations
- A (small) student model is trained to reproduce these outputs
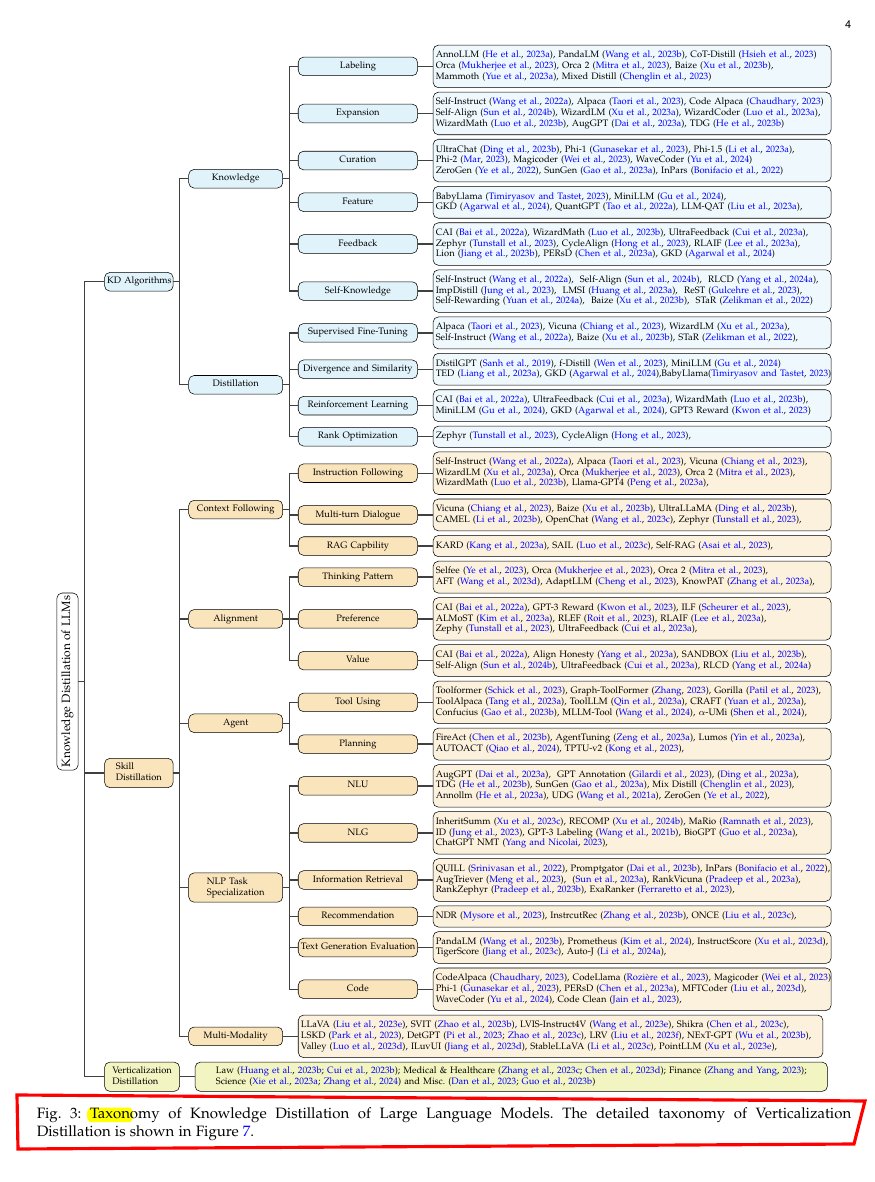
- From A Survey on
Knowledge Distillation of Large Language Models:
- Knowledge distillation
- Skill distillation
- Verticalization distillation
- Keys to LLM distillation:
- design prompt to elicit knowledge or skills
- e.g., student learns to mimic the reasoning process (via CoT)
- data augmentation
- starting from seed knowledge, generate data (diverse, with reasoning…)
- design prompt to elicit knowledge or skills
- Distillation algorithms:
- supervised finetuning
- divergence minimization
- reinforcement learning
- rank optimization
- Teacher elicit knowledge by:
- labeling: generate labels
- expansion: generate similar data
- curation: generate data from topic/entity/…
- feature: output logits and latent representations
- feedback: teacher correct student generations
- self-knowledge: student self-filters its outputs (Self-Instruct, Self-Align, RLCD, Impossible distillation, LMSI, ReST, Self-Play, Self-Rewarding…)
- Skill distillation
- Context following: instruction (Evol-Instruct, Instruction fusion), code, maths, expert (SelFee, reflection tuning, DEITA, MUFFIN…)
- Multi-turn dialogue: UltraChat, UltraLlama
- RAG: SAIL, KARD, Slef-Rag
- Alignment: DEBATunE, Imitation Learning from Language Feedback, ALMoST, Conditioned-RLFT
- Agent: ToolFormer, Gorilla, ToolAlpaca, ToolLLM, ToolLlama, CRAFT, Confucius, FireAct, TPTU, AUTOACT…
- NLP tasks
- Multi-modality
- Verticalization distillation:
- Domain specific: law, healthcare, finance, science…
- Methods:
- continued pretraining followed by fine-tuning from self-constructed and augmented data
- augmented domain-specific dialogues, QAs
- self-instruct for science papers: DARWIN, teacher answers questions: SciGLM…
- Advantages of distillation vs. pretraining
- High quality data
- Richer information than standard causal LM, e.g., logits, latent representations
- \(\rightarrow\) requires less training data
- Drawbacks
- Requires a teacher model
- The teacher model is an “upper bound” (?)
- Challenge: reduce distillation cost: pruning, PEFT…
- Layer-wise distillation:
- Force the student to have the “same” latent representations than the teacher
- adds a 3rd loss = MSE between the layer’s activations (A matrix is also learned to map the dimensions)
- Less is
More, ICML23:
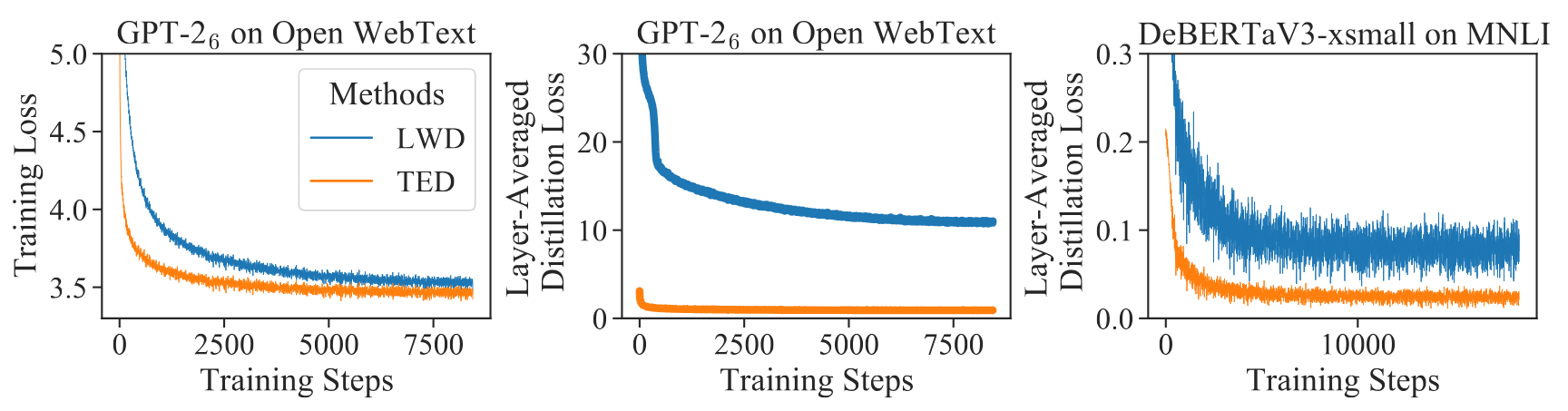
- Trains a teacher-filter from each layer’s activations to do the task (e.g., next token pred)
- Jointly distill the student + a student-filter \(\rightarrow\) only important knowledge is distilled
- Content inspired from slides by Dr. Simon Ostermann
Thank you!
- Pratical session:
- Language adaptation for causal reasoning
- Additional PEFT exercices by Tatiana Anikina and Simon Ostermann
- Slides: https://www.cerisara.fr
Contact: cerisara@loria.fr