WP2 - Appendix
Christophe Cerisara
CNRS, LORIA, Synalp team
Compromise: scaling laws vs. cost
- Scaling is always better
- SmolLMs are not Chinchilla-optimal but improve accessibility
- Approaches to reduce LLM size and cost:
- Optimization / Quantization / Algorithmic
- Distillation
- Pruning / Low-rank compression
Pruning: motivations
- May information stored in LLMs be sparse?
- Despite the fact that LLMs are trained on >10T words…
- In many target applications, a lot of knowledge is not required
\(\rightarrow\) generic vs. specific LLM
Pruning generic LLMs
- Can we prune a pretrained LLM so that it’s still generic?
- Is there “room” for pruning, given all the knowledge the LLM has memorized?
- \(\rightarrow\) Study the rank of parameters
- LoRA: finetune within a lower dimensional space
- GaLore: gradients low-rank projection
- LORD: low-rank decomposition of weight matrices
- CALDERA: joint quantization & low-rank projection
- …
Pruning and merging multiple specific LLMs
- Lottery Ticket Hypothesis:
- Each neural network contains a sub-network (winning ticket) that, if trained again in isolation, matches the performance of the full model.
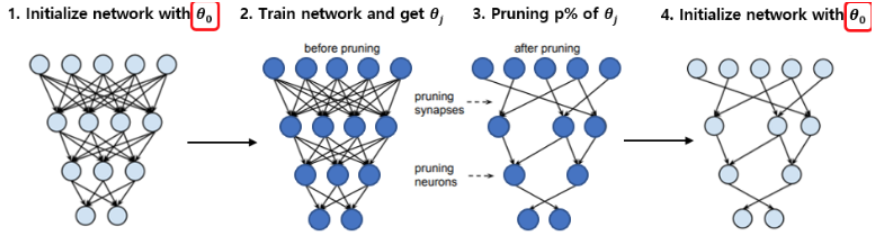
- Advantages:
- Can remove 90% parameters nearly without loss in performances (on image tasks)
- Drawbacks:
- Impossible to find the winning mask without training first the large model
- (Only?) for specialized models
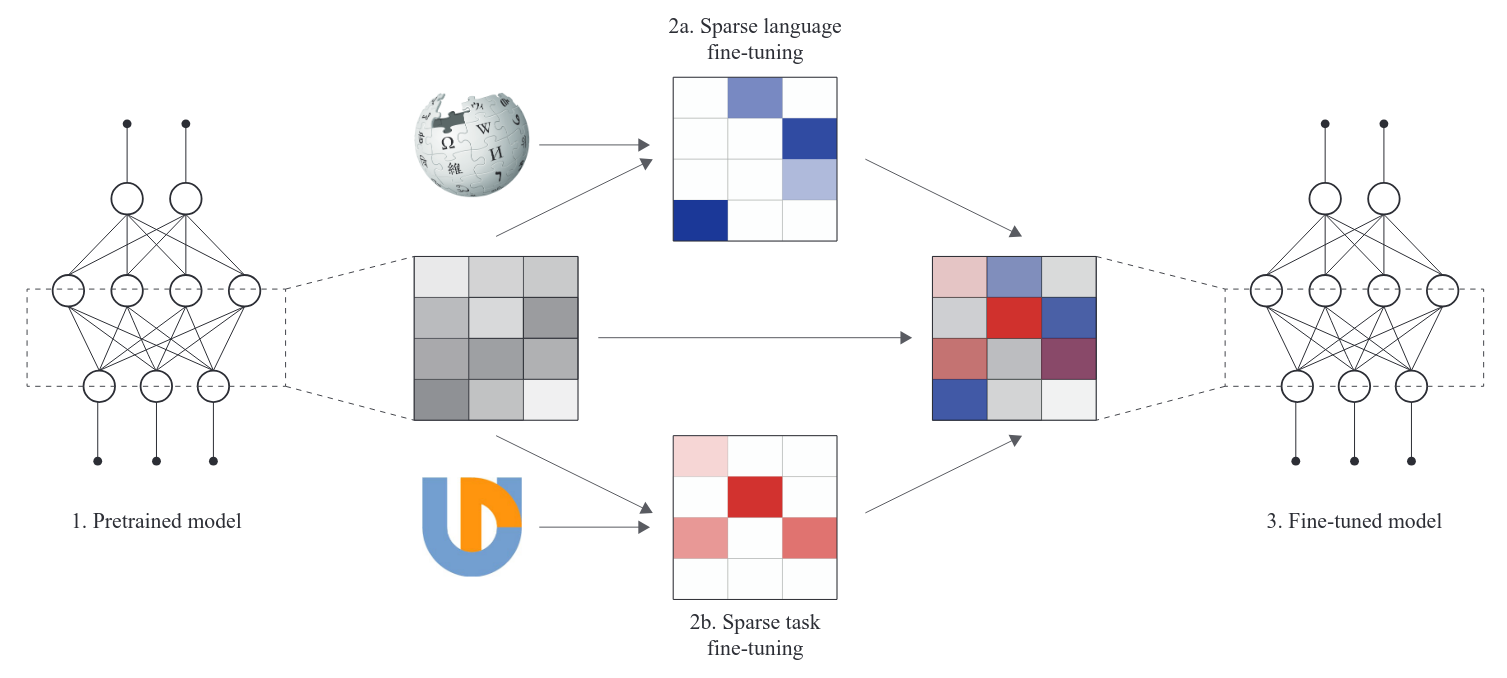
- can be applied to sparse FT
- FT an LLM on specific task/lang
- extract the mask = params that change most
- rewind the LLM and re-FT with mask
- sparse finetunes can be combined without overlapping!
- Approximations of activations: \[\widehat{\Delta W} = \underset{{\Delta W}}{\mathrm{argmin}} \;\; \frac{1}{N}\sum\limits_{x \in \mathcal{D}}\|Wx - {\Delta Wx}\|_{F}\]
- Optimal solution: PCA of covariance: \[\Sigma = \underset{y \in \mathcal{Y}}{\mathbb{E}}\left[yy^T\right] - \mathbb{E}[y]\mathbb{E}[y]^T\]
- Used for LSTM & BERT in (Chen,2021), for transformers in (Yu,2023), and see
- Proposal 1: Generalize to non-linear layers:
- The minimization objective can be viewed as Feature Distillation
- Replace SVD with gradient descent
- Teacher module \(\mathcal{T}^{(i)}(X; \Theta^{(i)})\) and Student module \(\mathcal{S}^{(i)}(X; \Delta \Theta^{(i)})\)
\[\widehat{\Delta \Theta^{(i)}} = \underset{{\Delta \Theta^{(i)}}}{\mathrm{argmin}} \;\; \mathcal{L}^{(i)}(Y^{(i)}, \; \widehat{Y}^{(i)})\]
- Because of unstabilities, augment L1 loss as (Chang,2022):
\[\mathcal{L}^{(i)} = \sum_{t=1}^{b} \left[ \frac{1}{D} \left\| Y^{(i)}_{t} - \widehat{Y}^{(i)}_{t} \right\|_1 - \log \sigma \left( \cos \left( Y^{(i)}_{t}, \widehat{Y}^{(i)}_{t} \right) \right) \right]\]
- Trained with SGD
- Converges towards SVD solution in the linear case
- Proposal 3: Module-level distillation
- Support of non-linear layers \(\rightarrow\) any stack of layers
- Better compromise between atomic/local distillation (matrix level) and global distillation (transformer level)
- We experiments at layer-level