Low-rank compression of LLM
2017: the transformer
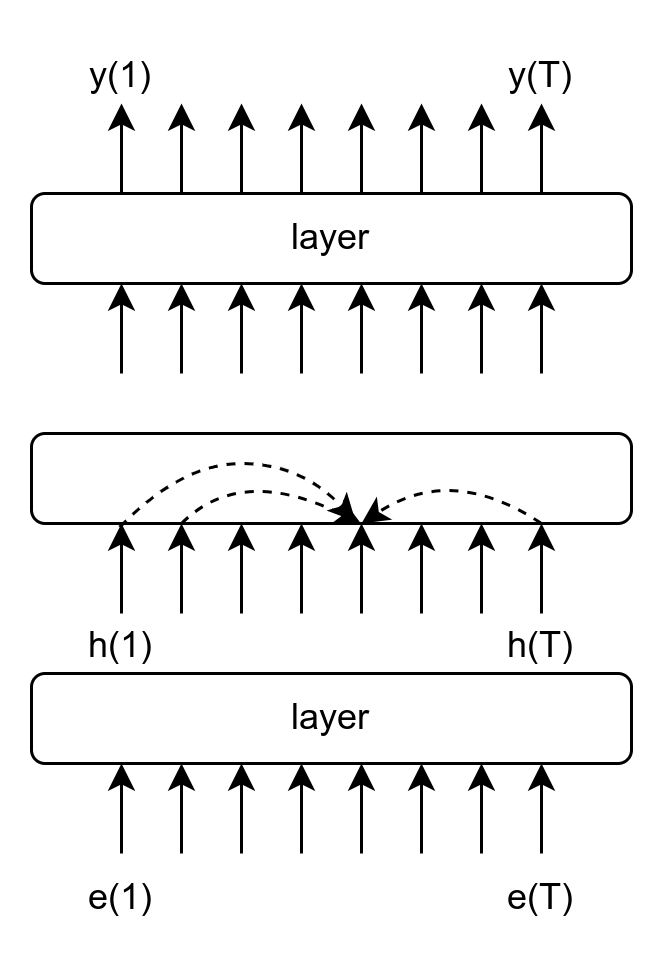
- Reason over layer steps
- Semi-Turing machine
- Learns to learn (2nd order-GD, TD)
- Reason over time steps
Baidu paper 2017
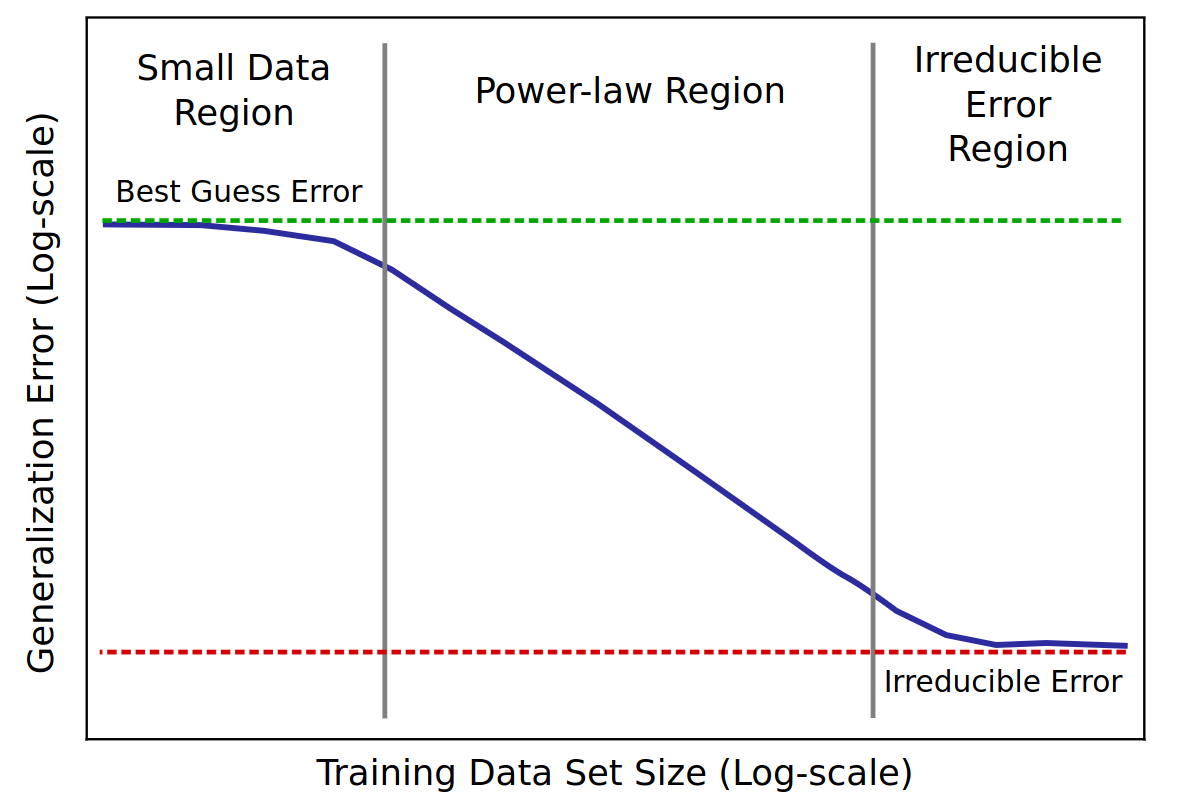

\(L=\) pretraining loss

Google 2022: paper1, paper2 Flops, Upstream (pretraining), Downstream (acc on 17 tasks), Params
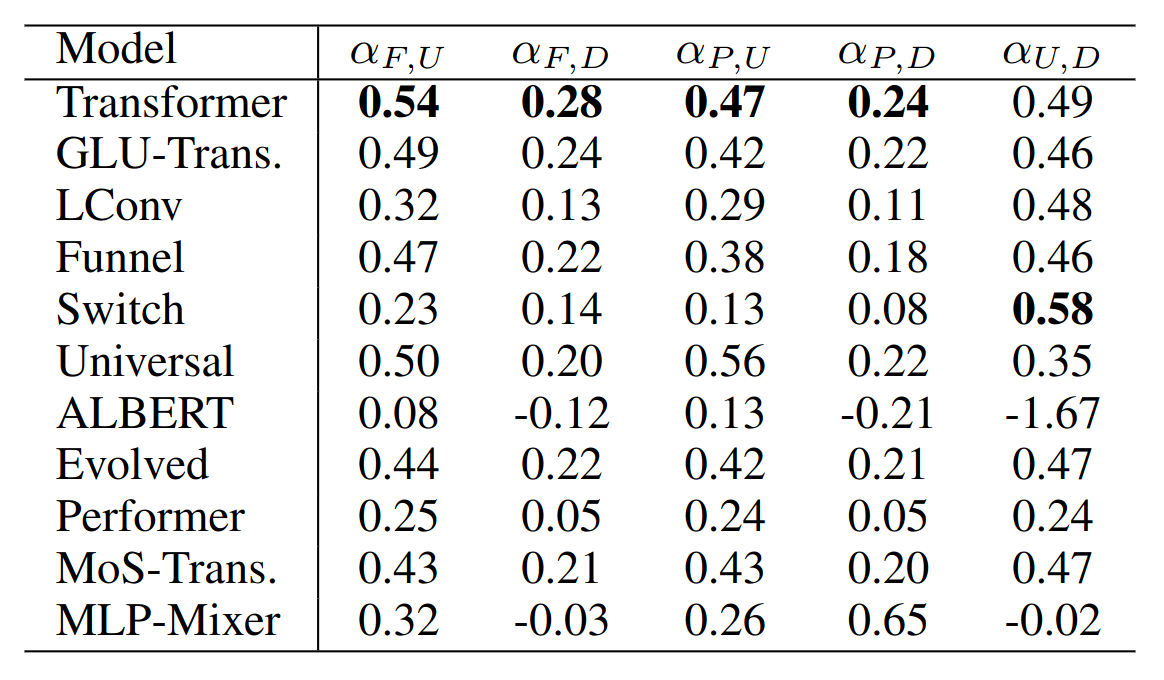
“Scaling Laws for Precision” (Nov, 2024)

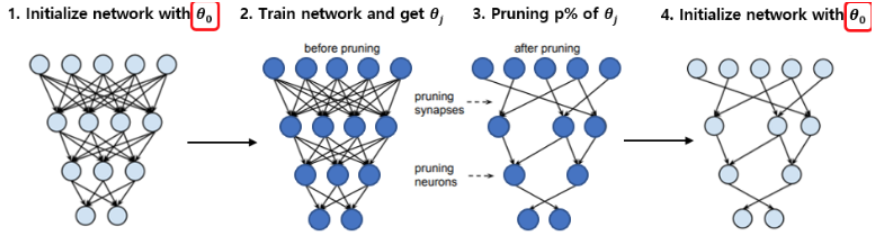
- Lottery Ticket Hypothesis:
- Each neural network contains a sub-network (winning ticket) that, if trained again in isolation, matches the performance of the full model.
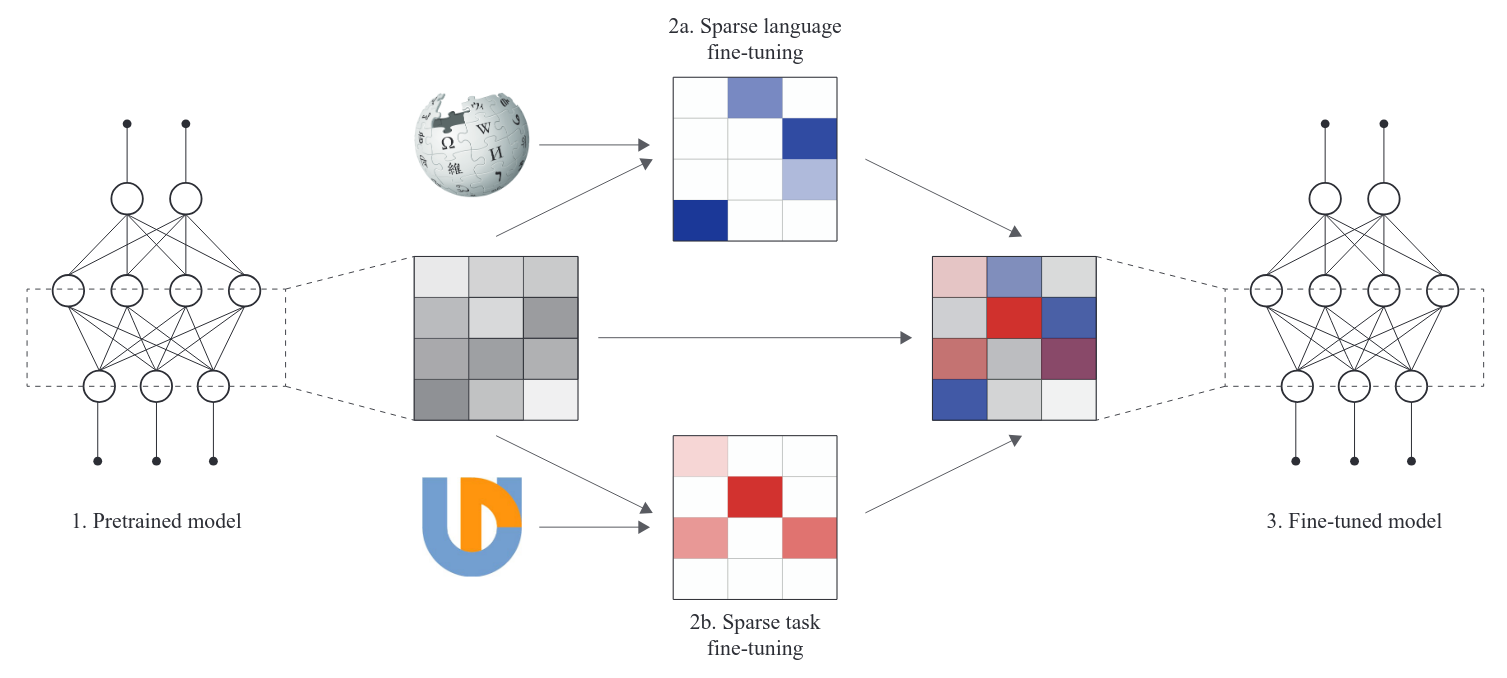
Low-rank matrices
- Weight matrices in LLMs are “slightly low-rank”, or “not totally full-rank”

- Activations are low-rank!

- Proposal 2: Better teacher/student inputs compromise
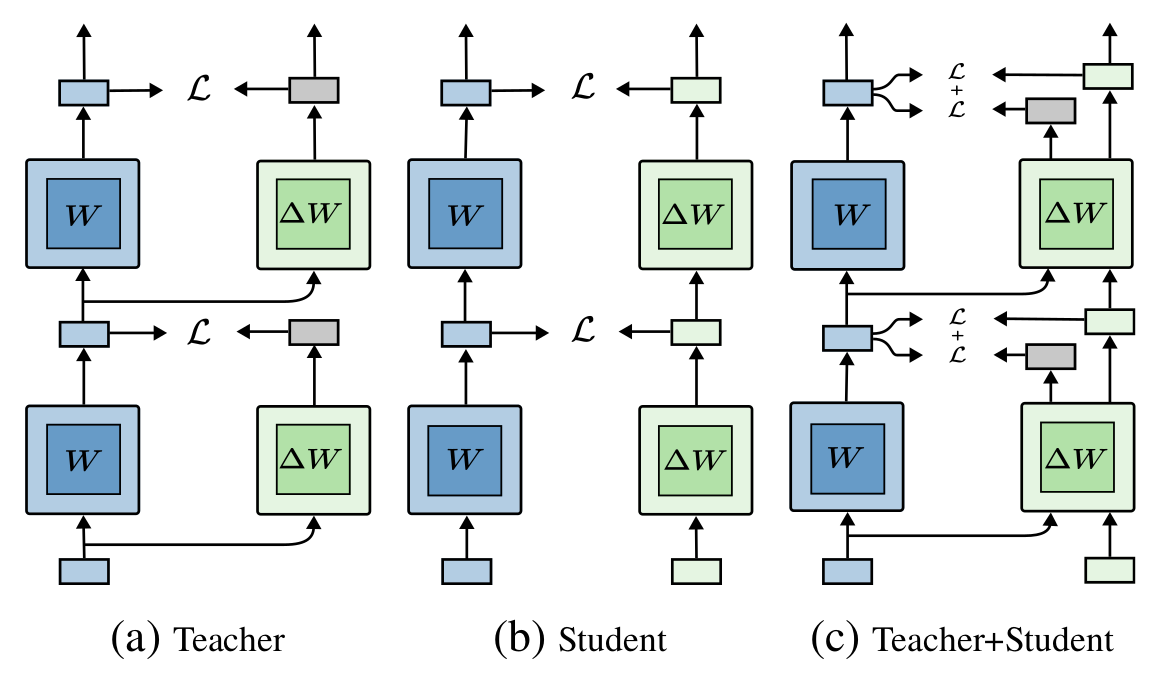
- Every layer has the same rank?
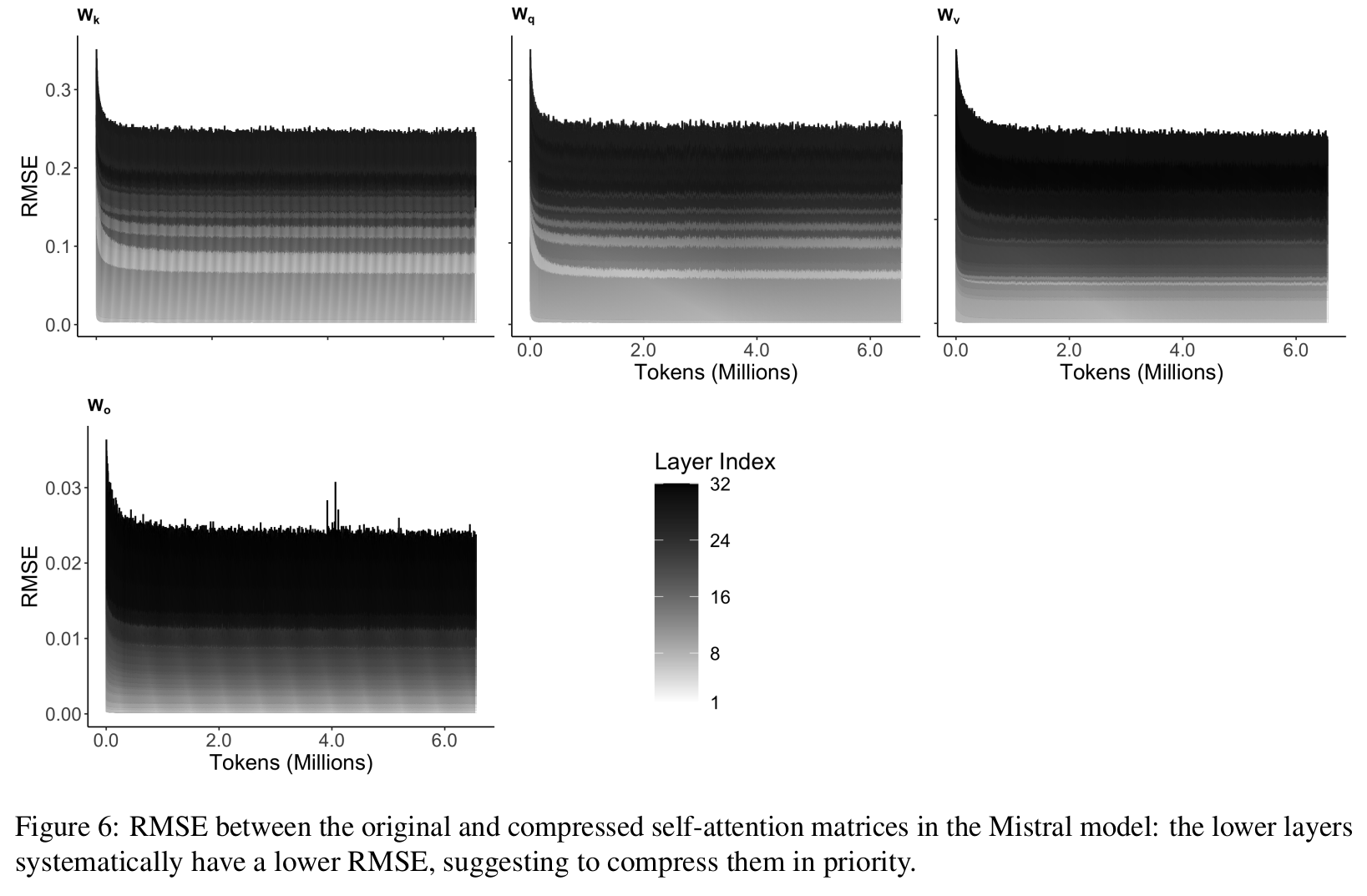
Conclusion
- Low-rank is everywhere in LLM tools
- But it’s not enough to make LLMs commodities:
- Quantization is more efficient
- Hardware/software optimization is key!
![]()
Happy to chat! cerisara@loria.fr, @cerisara@mastodon.online