Transformer and LLM
Transformer
- Transformer: (Vaswany et al., Google, 2017)
![]()
Details of the stack
- Bottom:
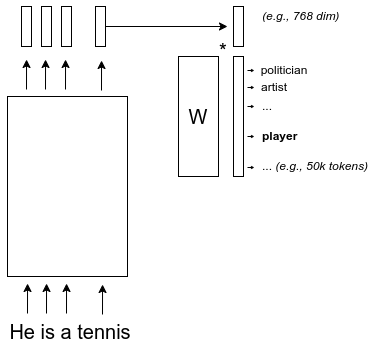
- convert input tokens to static embedding vectors \(X_t\)
- table lookup in Embeddings matrix
- Embeddings trained along with all other parameters (\(\neq\) contrastive)
- 3 matrices transform input embeddings \(X\) into \(Q,K,V\)
- convert input tokens to static embedding vectors \(X_t\)
Positional Encodings
- Self-attention gives the same repr when you shuffle the words !
- Inject information about position through a vector that encodes the position of each word
- Naive approaches:
- \(p=1,\dots,N\): not normalized + never seen N
- \(p=0,0.06,\dots,1\): \(\Delta p\) depends on sentence length
- Better approach:
- inspired by spectral analysis
- positions are encoded along sinusoidal cycles of various frequencies
\[p_t^{(i)} = \begin{cases} sin(w_k \cdot t), \text{if }i=2k \\ cos(w_k \cdot t), \text{if }i=2k+1 \end{cases}\]
with \(d\) encoding dim and
\[w_k = \frac 1 {10000^{2k/d}}\]
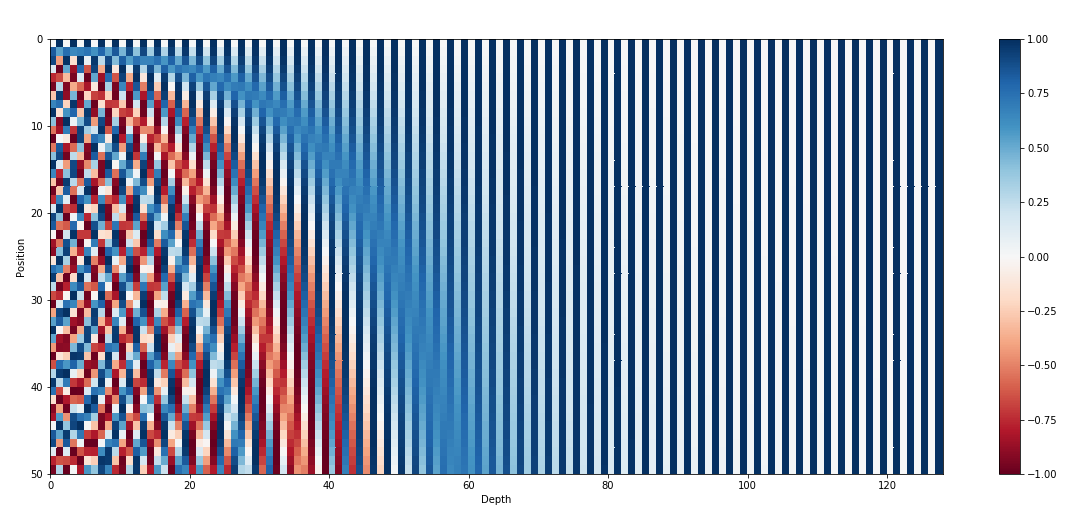
- Remarks:
- by giving positional encodings the same dimension as word embeddings, we can sum them together
- most positional information is encoded in the first dimensions, so summing them with word embeddings enable the model to “let” the first dimensions free of semantics and dedicate them to positions.
- Challenge: long-context
Multi-head self-attention
- several attentions in parallel
- concat outputs after self-att
![]()
Normalisation
- Add a normalization after self-attention
- parametric center+scale 1 vec across dimensions
- keep gradients small (cf arxiv.org/pdf/2002.04745)
MLP = feed forward
- Add another MLP to store/inject knowledge
- Add residual connections: smooth loss landscape
Layer
- Stack this block \(N\) times
- Gives time to reason = execution steps of a program
- Enables redundancy: Mechanistic interpretability:
- developped by Anthropic AI
- multiple/concurrent circuits
Encoder-decoder
- The transformer is designed for Seq2Seq
- So it contains both an encoder and decoder
- Same approach for decoder
- with cross-attention from encoder to decoder matching layers
- with masks to prevent decoder from looking at words \(t+1, t+2\dots\) when predicting \(t\)
- GPT family: only the decoder stack
- BERT family: only the encoder stack (+ classifier on top)
- T5, BART family: enc-dec
- pure encoders (BERT) have been superseded by enc-dec (T5)
- because T5 learns multiple tasks at once, vs. 1 task for BERT
- advantage of denoising loss decreases with scale
- denoising loss are less efficient than next-token prediction => largest LLMs are all decoders
- Implementation details of the transformer:
- great resource:
- see The annotated transformer
Inductive bias of transformer
- Assume discrete inputs (tokens)
- All positions in sentence have equal importance
- Relates tokens based on similarities / content
- 2 major composants with different roles:
- self-att focuses on relations
- MLP inject knowledge
- Solve limitations of previous models
- No bottleneck of information (as in ConvNet, RNN, seq2seq…)
- No preference for “recent tokens” (as in RNN)
- No constraints of locality (as in CNN)
- … but “lost in the middle” effect
- after learning, transformer can be viewed as a semi-Turing Machine:
- proof that transformer learns in context with gradient descent
- another proof that it can apply temporal difference (RL algo)
- deep learning models learn algorithms to compress information
- conclusion: 2 reasoning paths:
- depth = nb of layers
- time = stack again above the grown sequence
Update Oct 2024: Transformers Learn Higher-Order Optimization Methods for In-Context Learning - They learn exponentially better learning algorithms than SGD, apparently similar to Iterative Newton’s method
Desirable properties
- Can scale
- more layers => capture more information
- Can “absorb” huge datasets
- store information == same as database?
- Can “compress” information
- much better than database!
- Transformers progressively replaced other models in many modalites:
- Image: token = small piece of image
- Audio: token = small segment of sound
- Video, code, DNA…

- Language models: a special place
- “Absorb” the written web == all human knowledge
- by far the largest transformers
- 2021: Wu Dao 2.0: 1.75 trillion parameters
- Central wrt other modalities (see multimodality)
Terminology
- Activations: output of each layer
- Embeddings: outputs of the embeddings layer
- Latent representations: all activations
- LM head: final linear layer that outputs 1 score/voc unit
LLM
Life cycle of LLM

Open-source community
- Extremely important for LLMs:
- “We have no moat” (Google, 2023)
- Main contributors in: pretraining, finetuning, model merging, dissemination, efficiency, evaluation
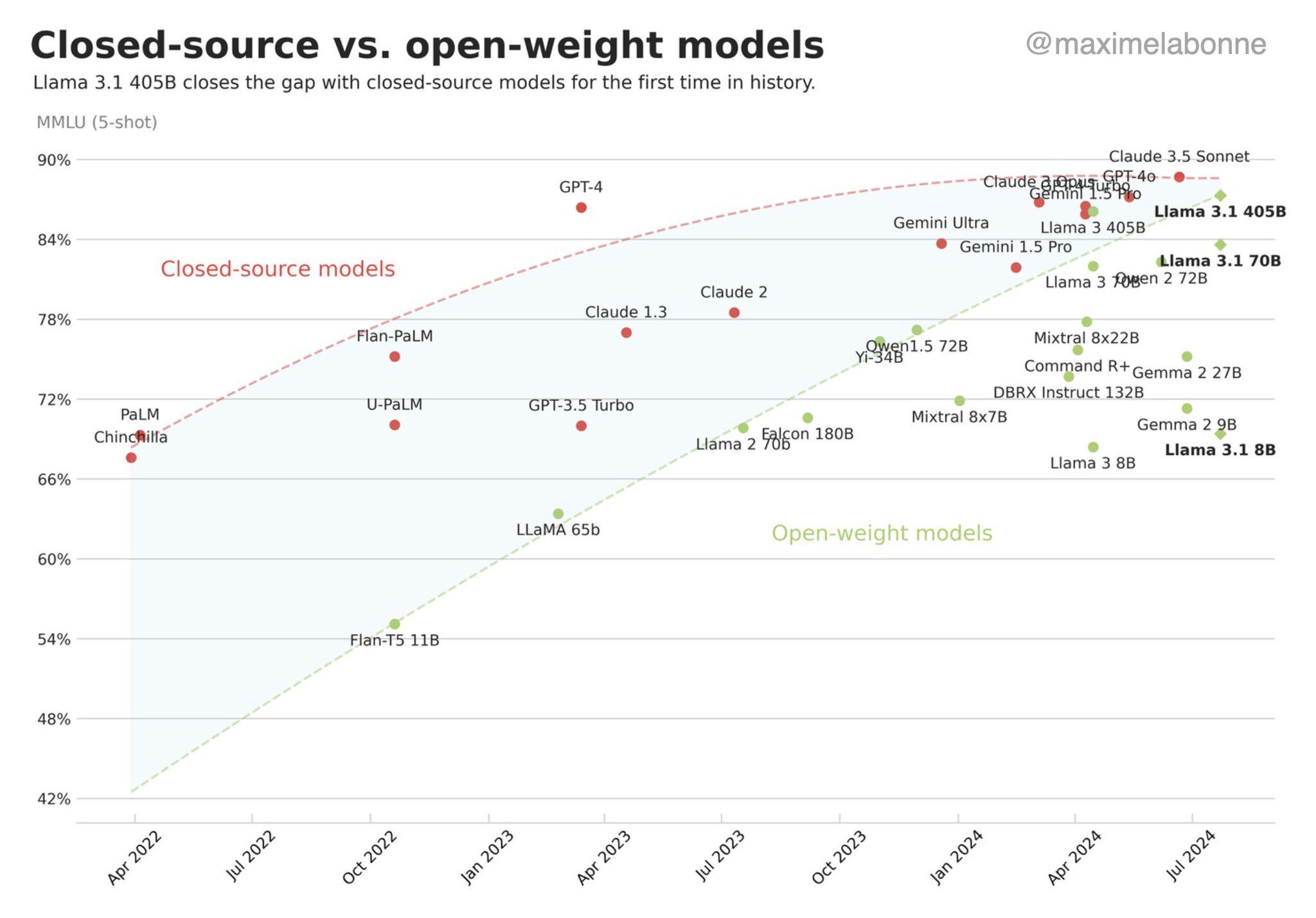
- Main open-source actors:
- Companies: Meta, HuggingFace, Eleuther AI, Mistral, Together AI, Cerebras…
- Civil society: passionates, geeks (TheBloke, Teknium…)
- Academics
- Online: Huggingface-hub, discord
- Towards specialization:
- Foundation: Meta, Eleuther, Mistral…
- Prompting: CoT, PoT, AoT…
- Finetuning: >600k models on HF
- Integrators: LangChain, DSPy, Coala…
- Academics: theory, app domains…
- Conversely to code, there’s a continuum between “fully open” and
“closed” source:
- distribute model weights
- distribute code
- distribute training logs
- distribute training data
- …
LLM and AI-Act

Bloom: the first open-source LLM
- Bloom training led by T. Le Scao & A. Fan (PhDs in Synalp)
- Our participation to FR-MedQA (DEFT, June 2023):
- (ZSL) qBloomZ 27.9%
- (ZSL) Llama-65b 21.8%
BloomChat (Together.AI 2023)
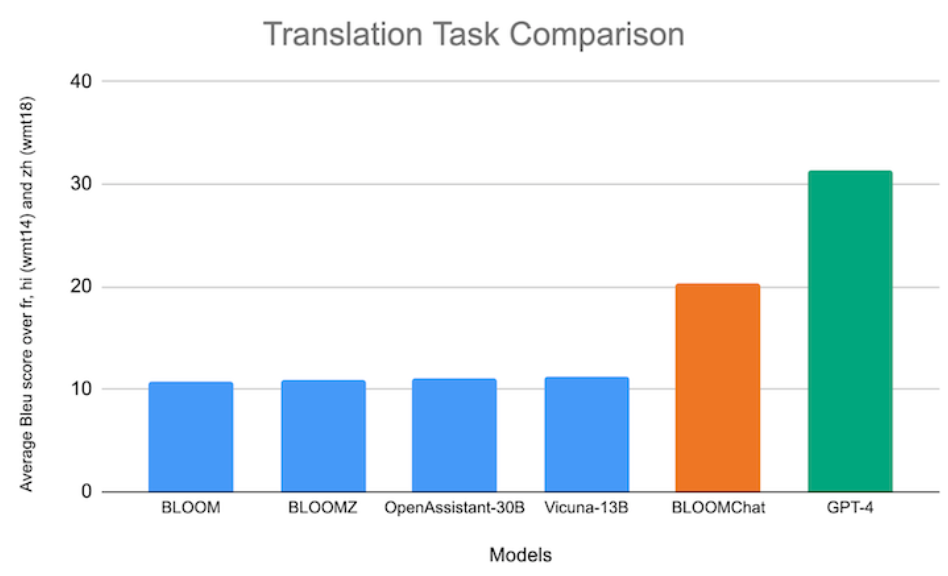
- Crédit Mutuel Bloomz-chat
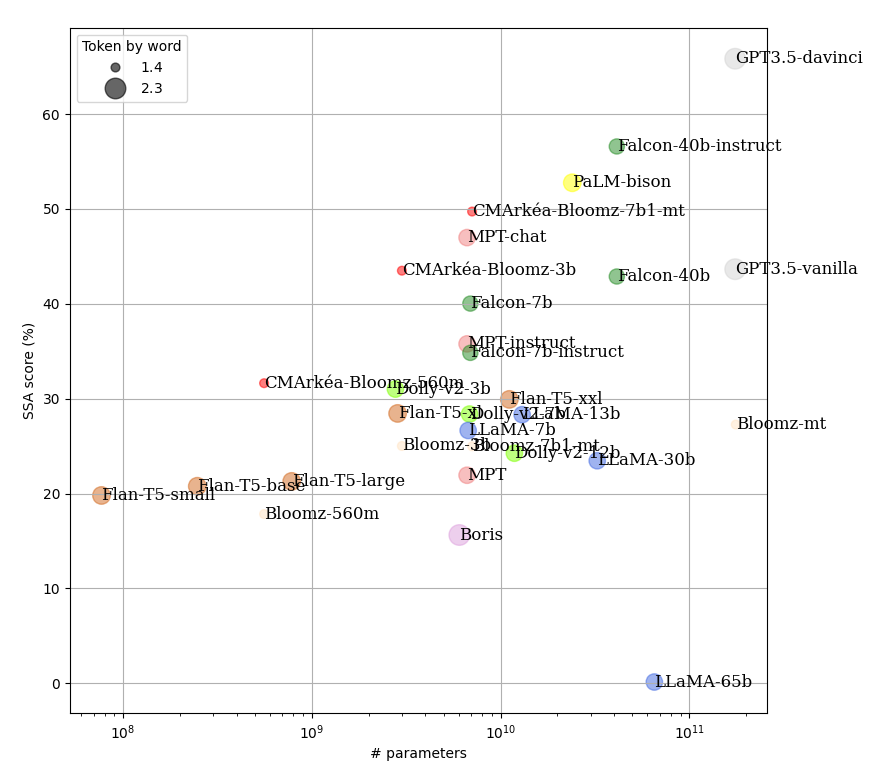
Microsoft study (Nov. 2023)
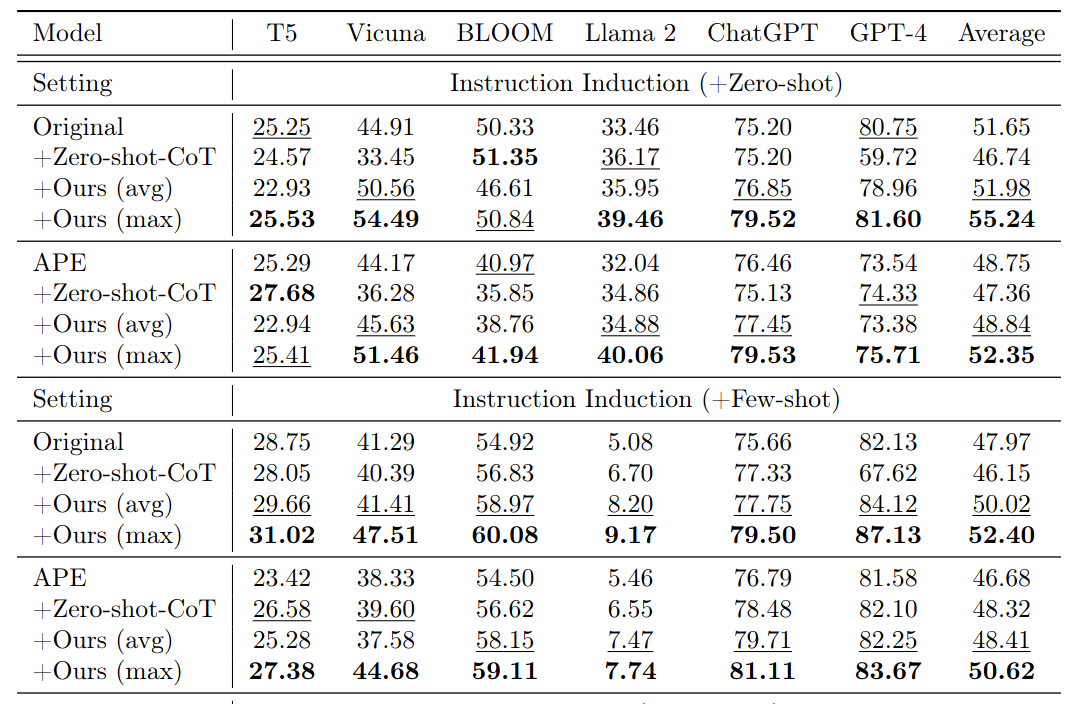
Wrap-up
- LLMs are novel tools to
- interact naturally with humans
- access world knowledge + common-sense
- reason, plan, interact with code
- They will seamlessly integrate most software
- as modules within high-level programs
- as data processors + generators
- as cheap substitutes to humans in boring tasks
Practice: LLM 1
Objectives:
- Intro to 2 libraries: transformers library and ollama
- Analyzes an LLM to map course concepts onto transformers library
- Advanced use: function calling with ollama
Analyzing an LLM
- load the smallest qwen2.5 with Huggingface transformers with mod=AutoModel.from_pretrained(…)
- look at its structure with the help of “for n,p in mod.named_parameters()”
- another option is “for n,p in mod.named_modules()”
- Describe the model: How many layers? Hidden dimension size? Types of normalizations?…
- Hint: “type()” gives you the full name of a variable; you can then view its source code in your conda/pip env
Pretraining scaling laws
Chinchilla law

Scaling LLMs
- The more data you train on
- the more the LLM knows about
- the better the LLM generalizes
- scaling law = power law = \(y(x) = ax^{-\gamma} +b\)
- \(y(x) =\) test loss
- \(\gamma\) = slope
Baidu paper 2017
Scaling laws for Neural LM 2020
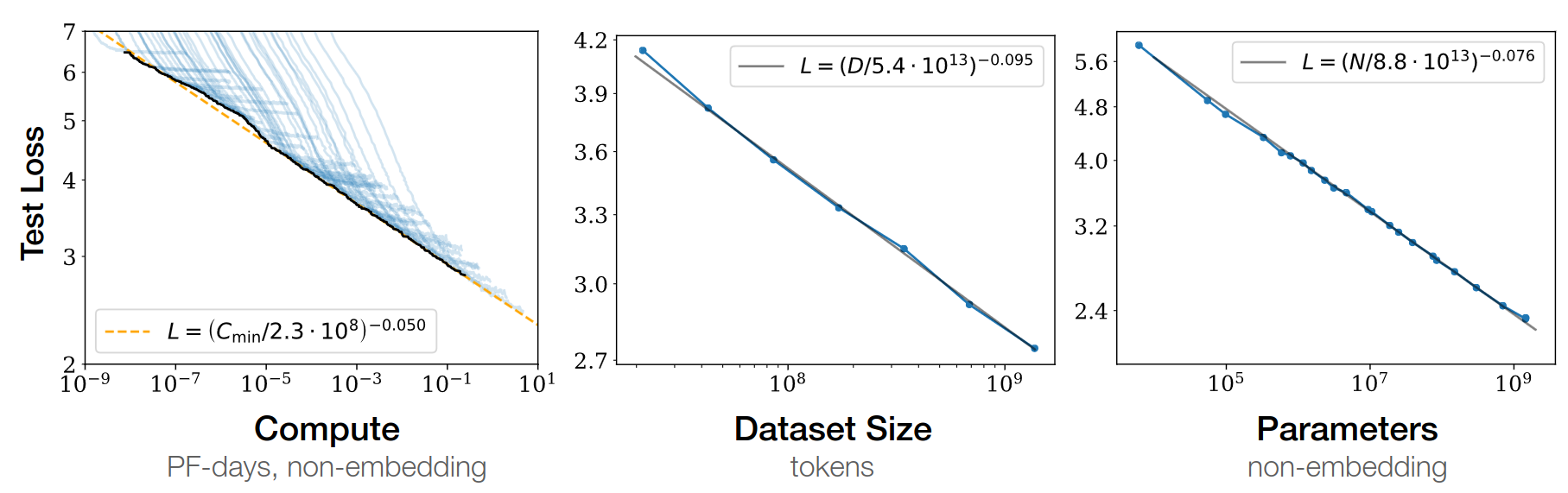
Open-AI 2020
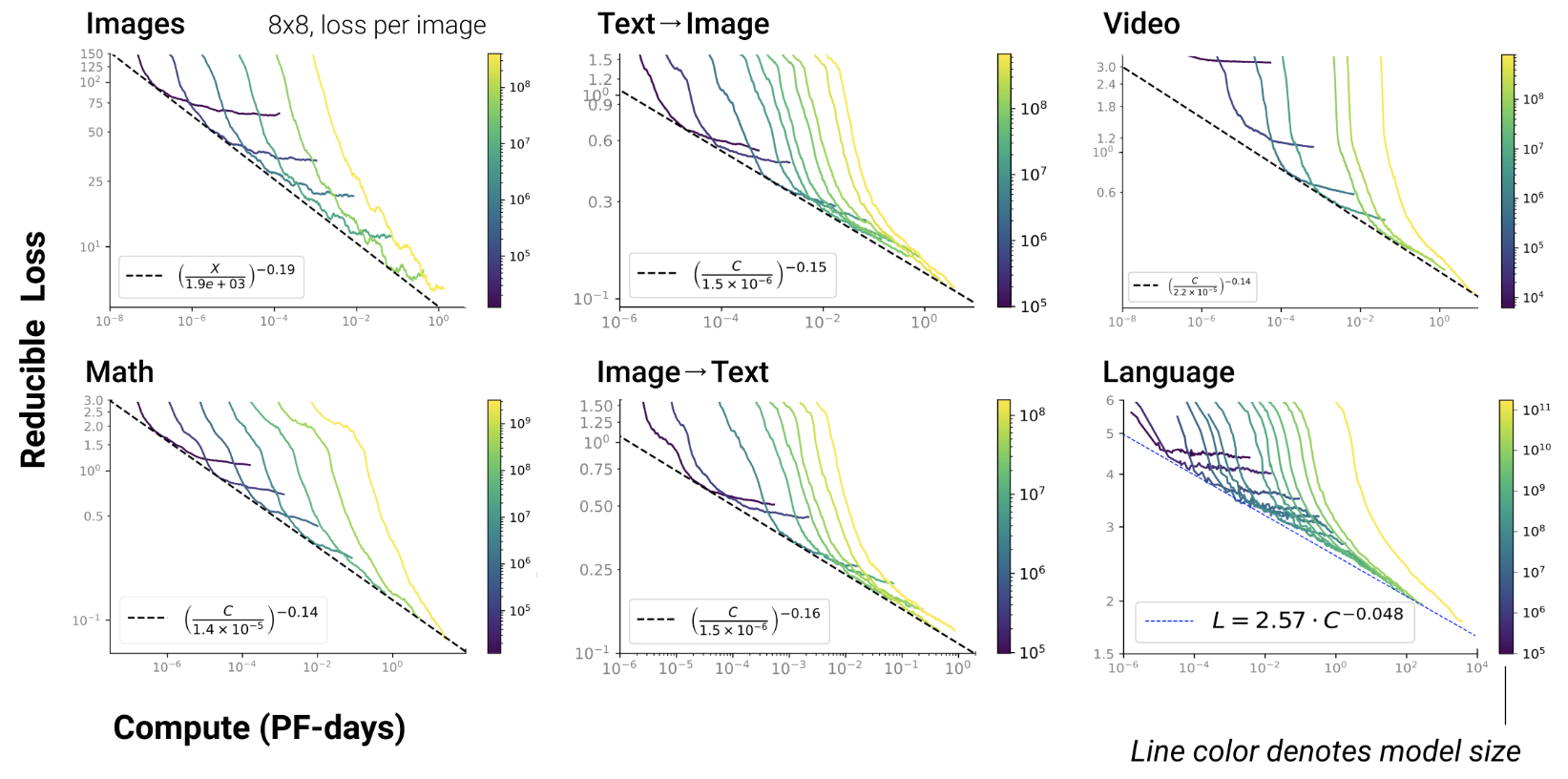
- RL, protein, chemistry…
Chinchilla paper 2022
- GPT3 2020: inc. model capacity
- Chinchilla 2022: inc. data

\(L=\) pretraining loss


Google 2022: paper1, paper2 Flops, Upstream (pretraining), Downstream (acc on 17 tasks), Params
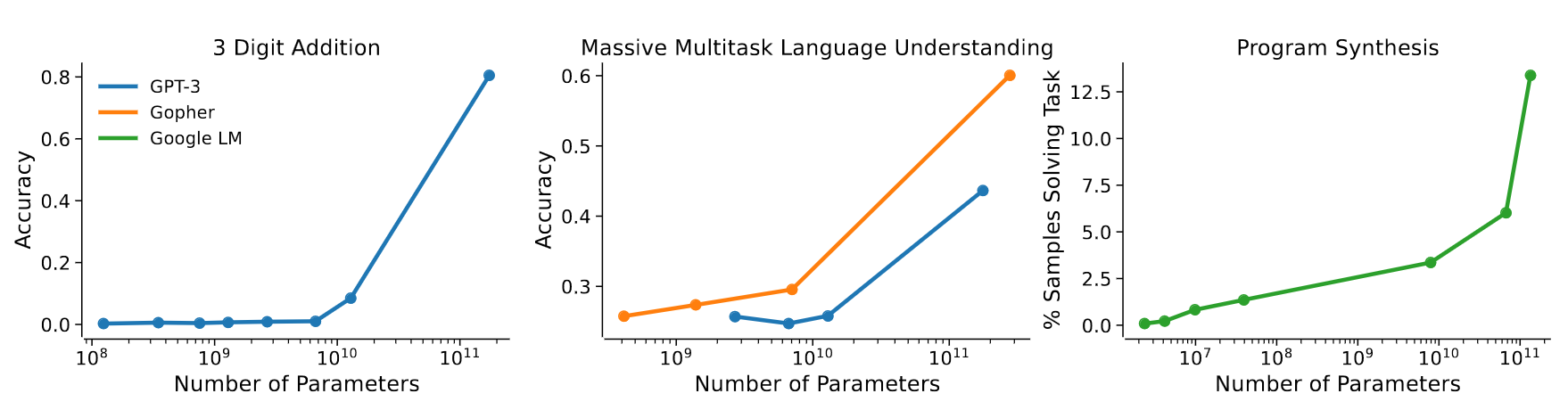
Emerging capabilities
- Scaling laws exist in Machine Learning for a long time (cf. Paper on learning curves)
- But it’s the first time they result from emerging capabilities!
GPT3 paper 2020
- emergence of “In-Context Learning”
- = capacity to generalize the examples in the prompt
- example:
"eat" becomes "ate"
"draw" becomes "drew"
"vote" becomesAnthropic paper 2022
- shows that the scaling law results from combination of emerging capabilities
Jason Wei has exhibited 137 emerging capabilities:

- In-Context Learning, Chain-of-thought prompting
- PoT, AoT, Analogical prompting
- procedural instructions, anagrams
- modular arithmetics, simple maths problems
- logical deduction, analytical deduction
- physical intuition, theory of mind ?
- …
Phase transitions during training
During training, LLMs may abruptly reorganize their latent representation space
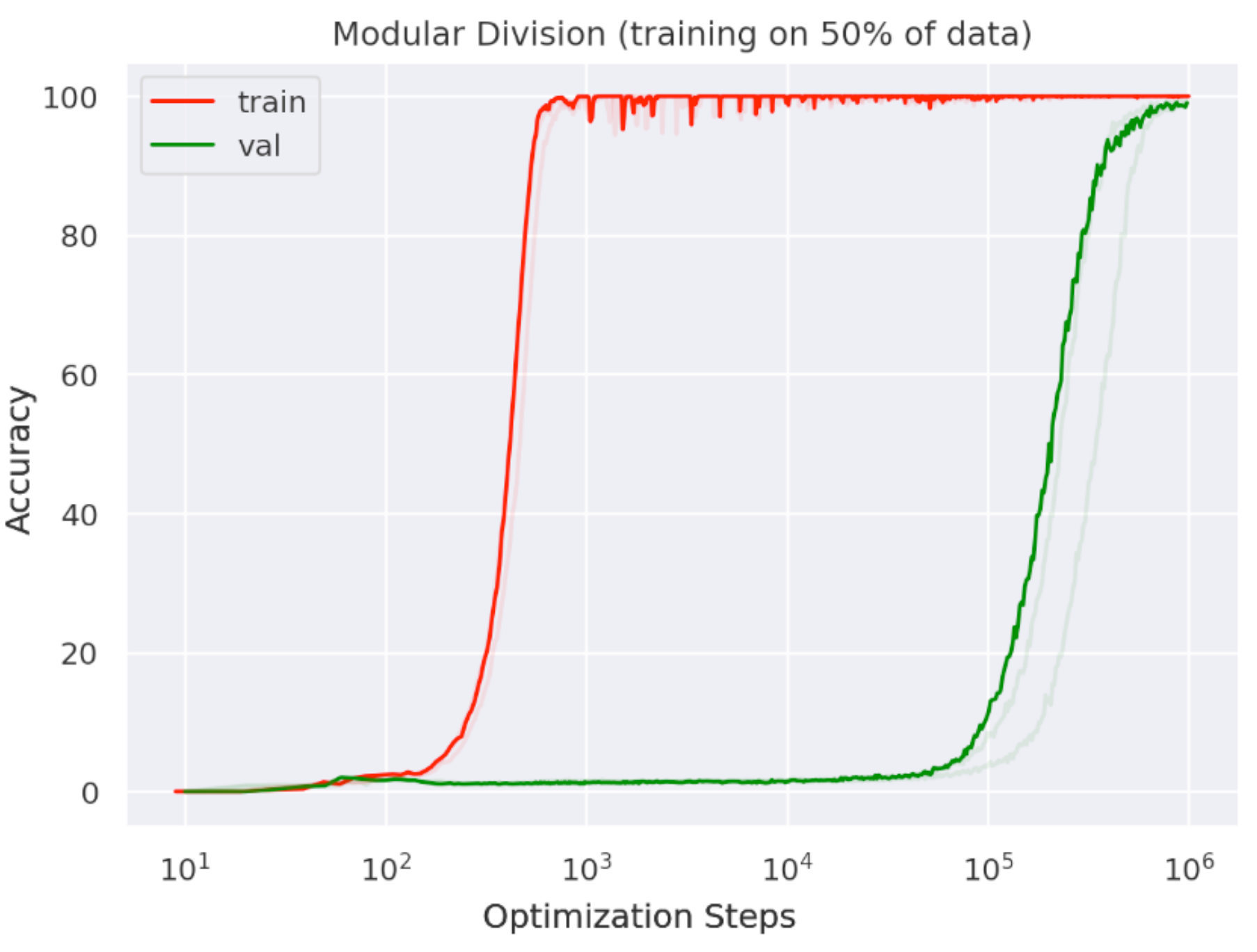
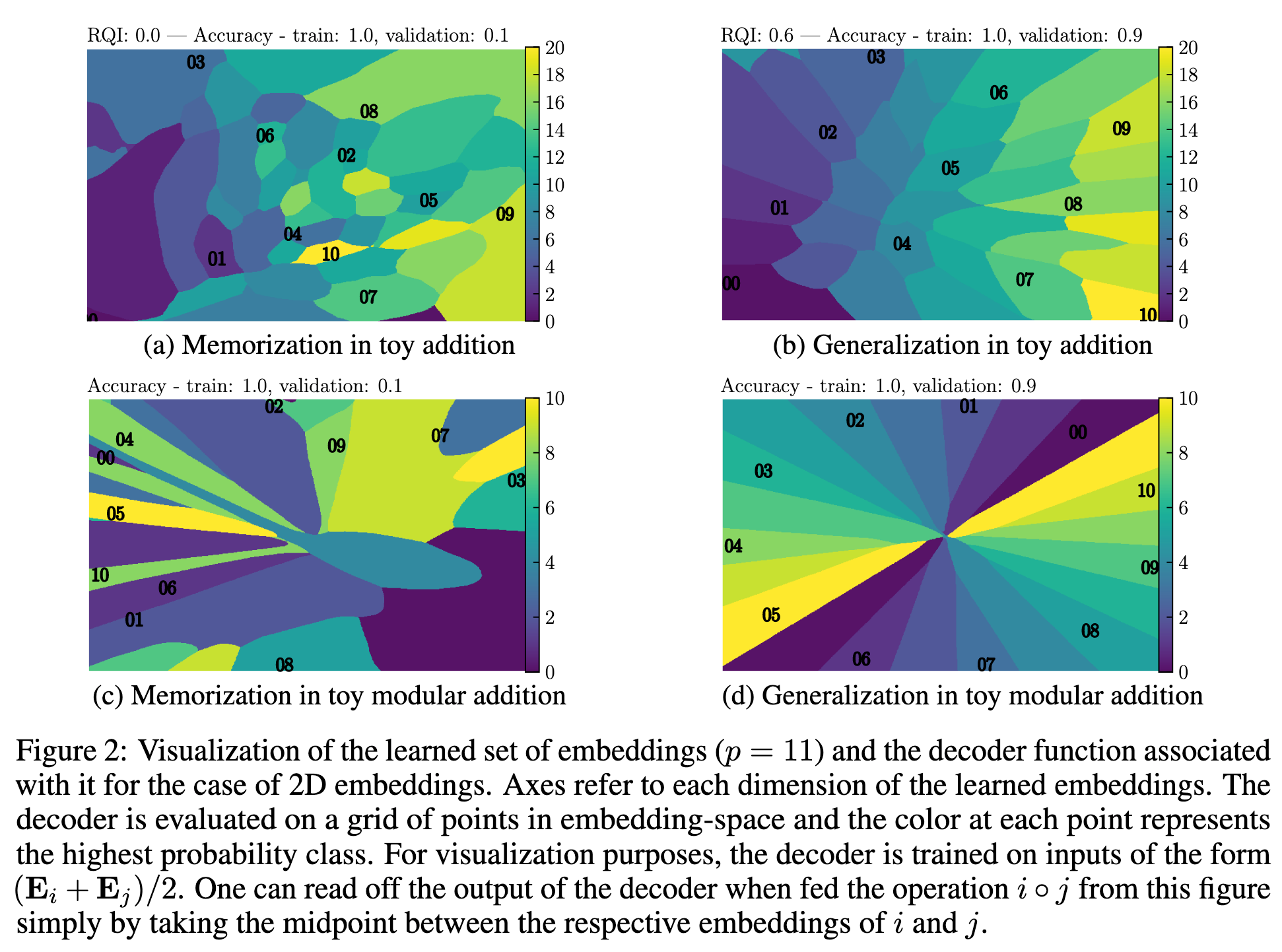
Grokking exhibits structured latent space

LLM traning dynamics
- High-dim training is not a “continuous”/regular process:
- Phase transitions first observed in 2015 in ConvNets
- Later studied in LLMs
- Traditional ML precepts invalidated:
- Overfitting is not bad
- Finding global optimum is not required
Definitions
- Loss = LLM error function to be minimized during training
- Loss landscape = surface/manifold of the loss \(L(\theta)\) as a function of LLM parameters \(\theta\)
- SGD = training algorithm that iteratively updates \(\theta\) following the direction of the gradient \(-\nabla_{\theta} L\) to progressively reduce the error \(L(\theta)\) made by the LLM on the training corpus
- Objective of training = finding a good \(\theta^*\) that gives the smallest possible
\(L(\theta)\)
- This can be viewed as navigating on the loss landscape to find a minimum/valley in the loss landscape
- Overfitting = “learning by heart” the training dataset
- = finding an optimal \(\theta^*\) that gives a minimum \(L(\theta)\) on the training corpus, but a large loss on another corpus
- The real objective of training is to find a \(\theta^*\) that generalizes, i.e., that has a low error on other datasets than the training corpus
- Regularization = Ways to prevent overfitting and still get
generalization
- reduce nb of parameters, minimize \(||\theta||^2\), dropout, reduce batch size, add noise to data…
Tishby’s bottleneck
- deep learning creates 2 training phases: overfitting, then compression
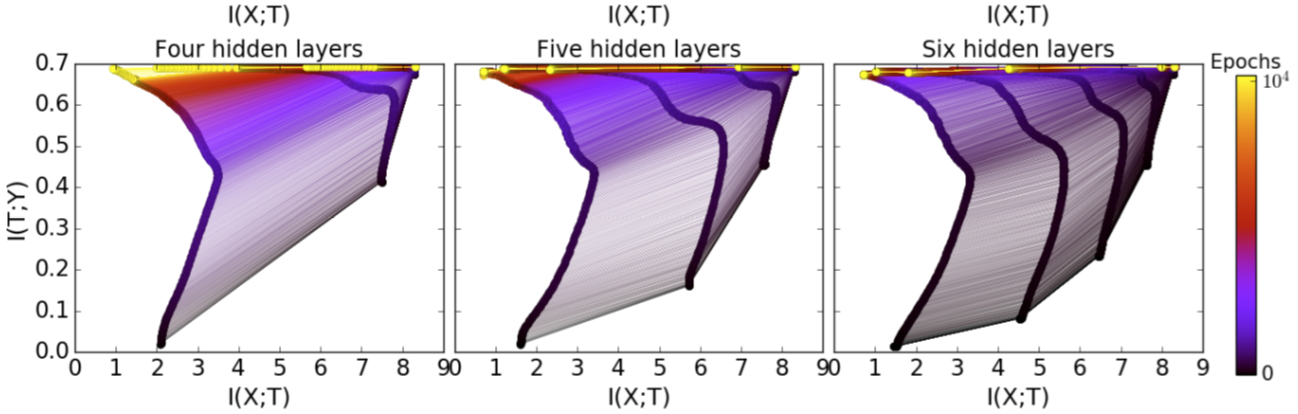
Double descent
First proof that overfitting may be addressed by increasing the nb of parameters!

- Double descent occurs when:
- the model is over-parameterized
- there’s a strong regularization (e.g., L2)
- Intuition:
- With more parameters, many optima exists
- With the help of regularization, the model may find a really good one
Warning
- grokking is a phase transition that occurs during training
- double descent is not a transition of phase that
occurs during training!
- double descent helps to understand the necessary conditions for grokking
Back to grokking
- First observed
by Google in Jan 2022
- Trained on arithmetic tasks
- Must wait well past the point of overfitting to generalize
- It often occurs “at the onset of Slingshots” Apple paper
- Slingshots = type of weak regularization = when “numerical underflow errors in calculating training losses create anomalous gradients which adaptive gradient optimizers like Adam propagate” blog
- post-grokking solutions = flatter minima
- Training involves multiple phases: grokking is one of them MIT paper
- generalization, grokking, memorization and confusion
- When representations becomes structured, then generalization occurs:

- The 4 phases depend on hyper-parameters:
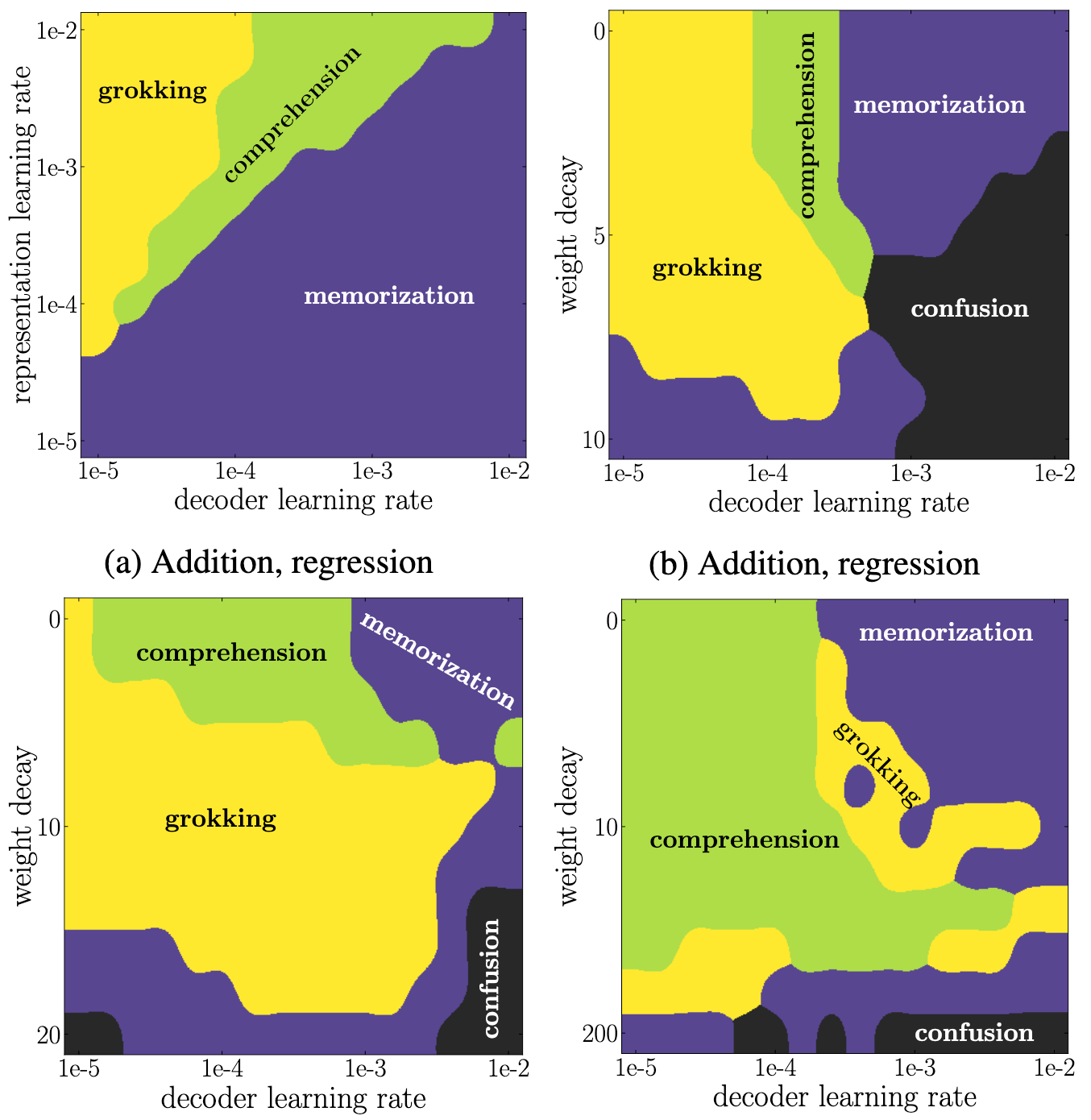
- Why do we observe phases during training?
- NYU paper 2023
- Because of competing sub-networks: dense for memorization and another sparse for generalization
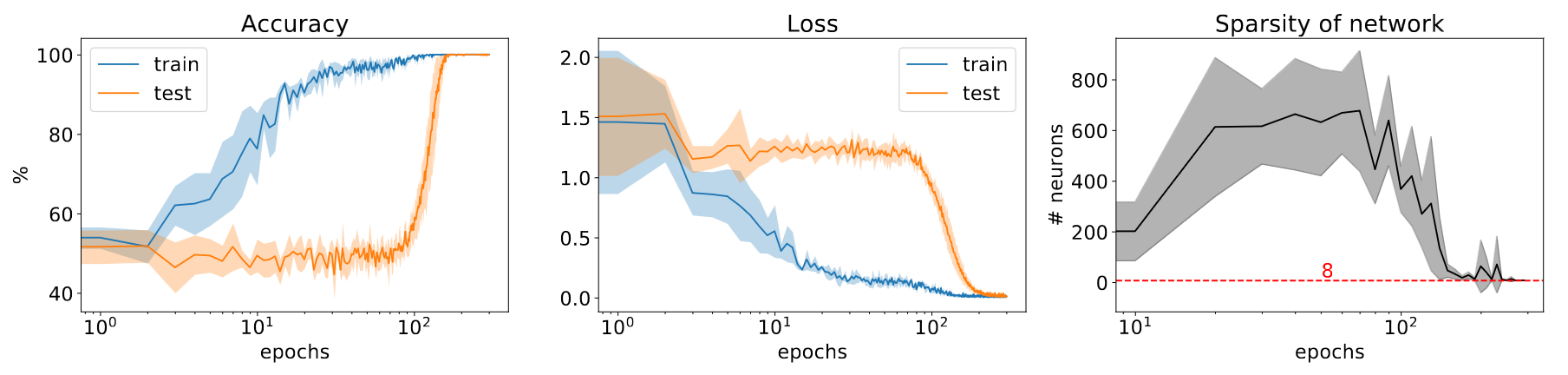
- COLM’24 paper: dual view of double descent and grokking, and training regimes
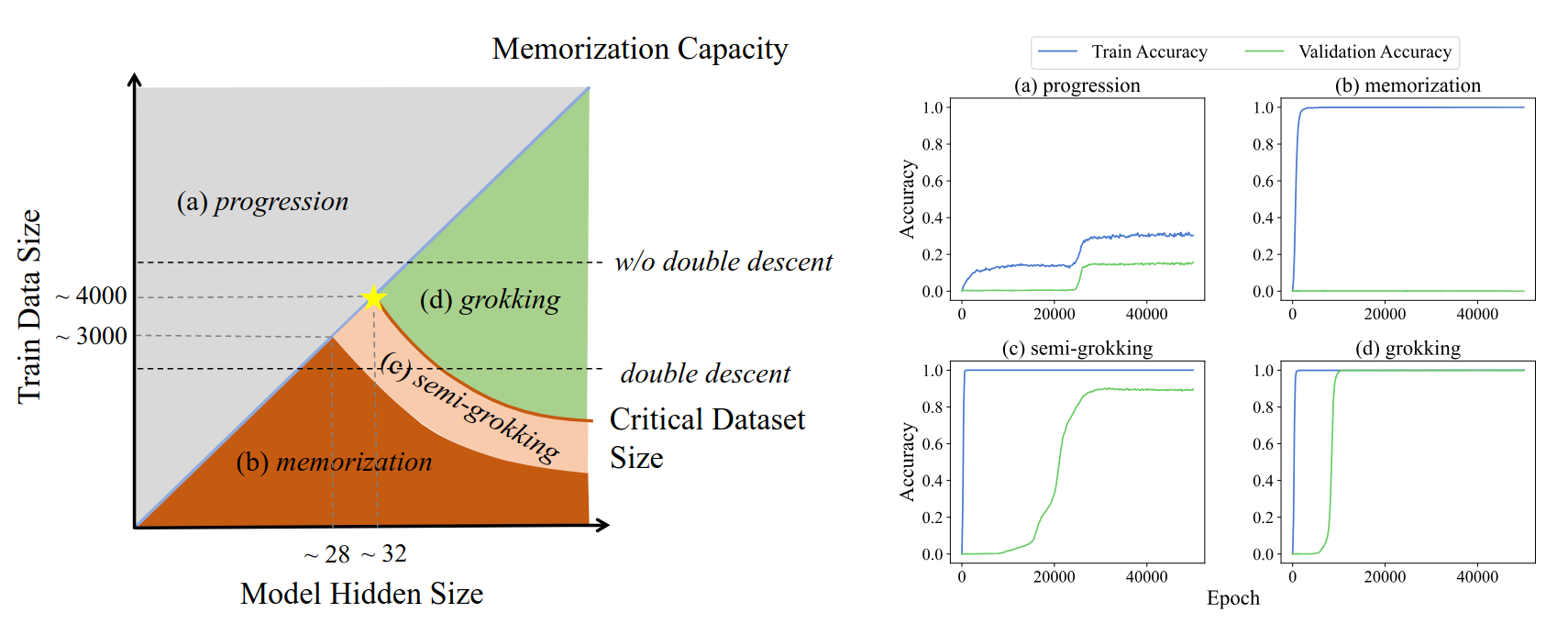
Wrap-up: scaling parameters
- It’s theoretically better to have over-parameterized models, as it unlocks double descent and potentially grokking
- But Kaplan’s law were promoting too large LLMs, Chinchilla’s law make it more reasonable
- Scaling laws are precious tools to design experiments before starting training
- We know since 2015 that training deep models involve multiple phases
- We now know that LLMs have 4 possible phases, depending on the hyper-parameters
- We know these phase transitions come from competing sub-networks (impossible without over-parameterization)
Practice: scaling laws
- The above tutorial does not give yet a scaling law: why?
- Reminder, what we did:
- we fix N=distilGPT2, C=100, and increase D
- if you fix C=100, you cannot predict for D>100
- scaling == requires increasing C
- But in practice, nowadays, C is the main constraint
- scaling law = what is the best we can do for a given C?
- the best D? \(\rightarrow\) as much D as possible
- the best N?
- How do the training curves look like when comparing several N?
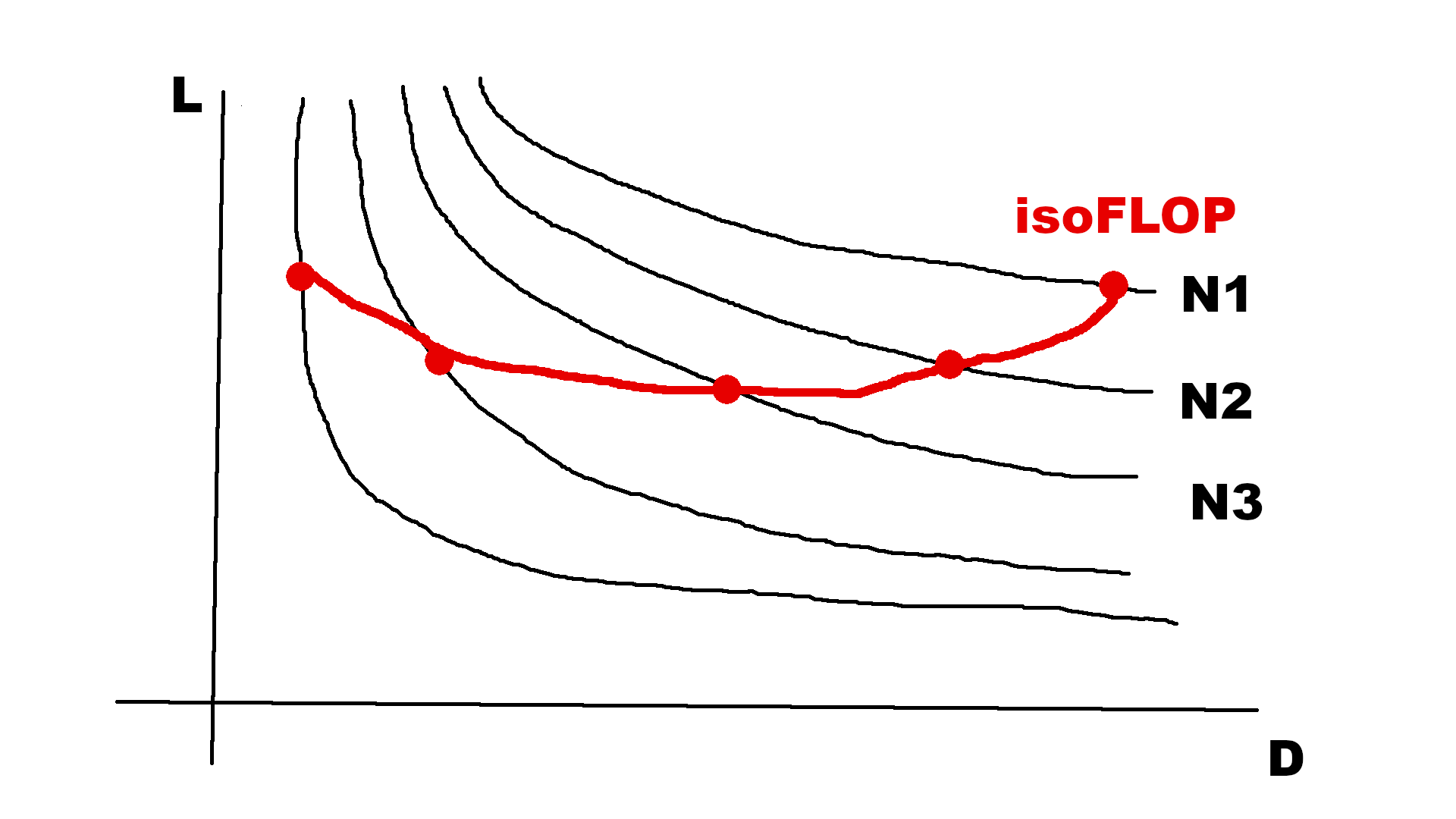
- The minimum of the isoFLOP is the optimal model for a given compute C
- Scaling law = plot this minimum error when increasing C
Design of LLM
Choice of architecture
- Focus on representations: RAG, multimodal,
recommendation
- contrastive learning: S-BERT, BGE, E5
- Classification: BERT? More and more: GPT
- Focus on generation:
- Transformer-based (GPT family)
- MoE
- SSM: S4, Mamba
- Diffusion
Mixture of Experts
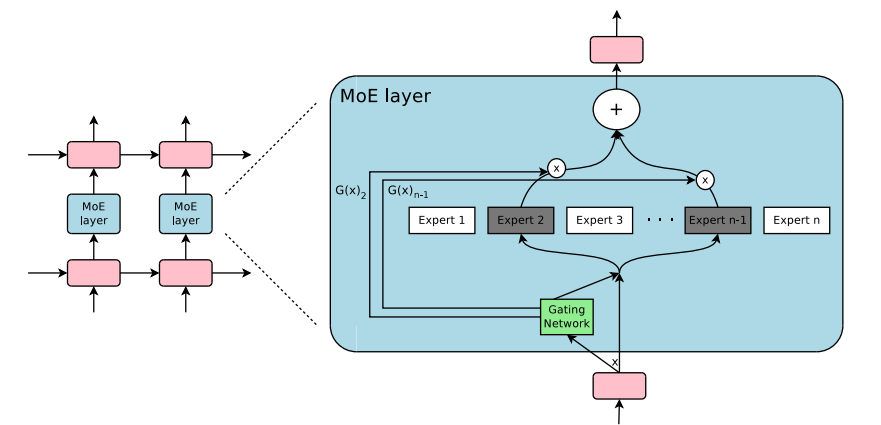
(from huggingface)
Mixture of Experts
- Main advantage: reduced cost
- Ex: 24GB VRAM (4-bit Mixtral-8x7b) 7b-params during forward pass
- Drawbacks:
- more redundancy across parameters
- hard to train
State-Space Models
- Discrete SSM equation similar to RNN:
\[h_t = Ah_{t-1} + Bx_t\] \[y_t = Ch_t + D x_t\]
- but A,B,C,D are computed: they depend on the context
Mamba
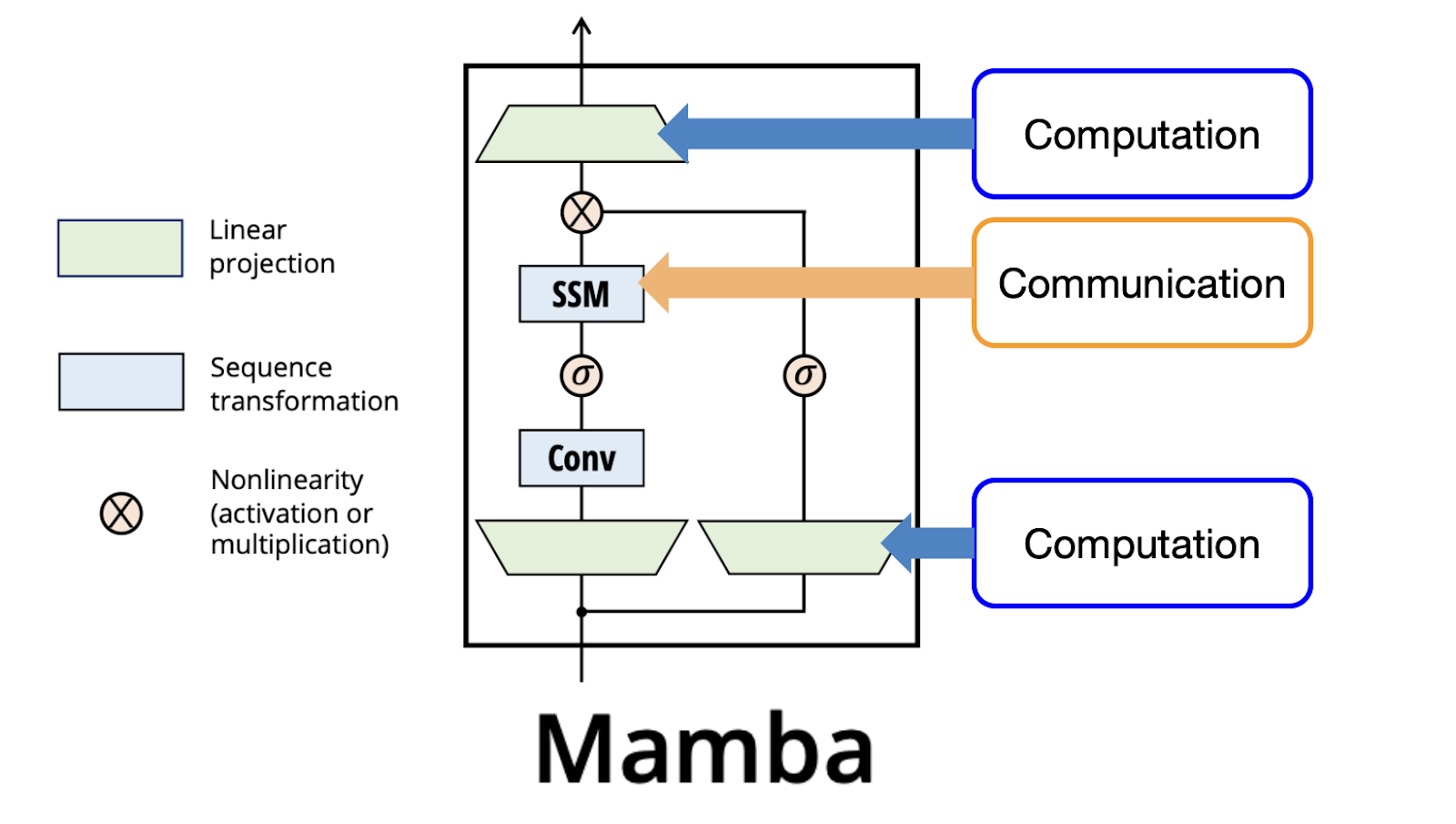
Ex: Mamba
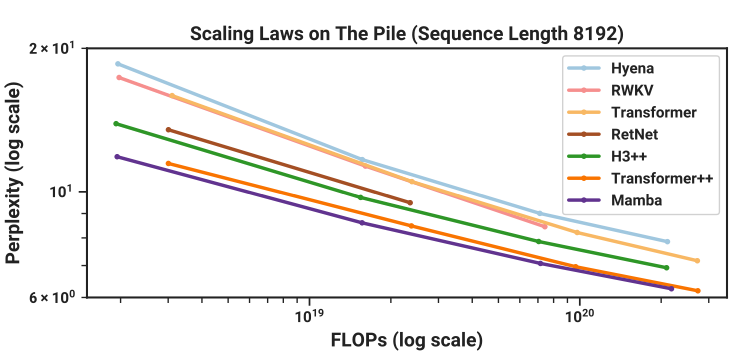
- scaling law comparable to transformer (up to \(10^{20}\) PFLOPs)
- linear \(O(n)\) in context length
- faster inference, but slower training
Diffusion transformer
- Diffusion models: forward noise addition
- Adds noise, step by step to input \[q(x_t|x_{t-1}) = N(x_t;\sqrt{1-\beta_t} x_{t-1}, \beta_t I)\]
- backward denoising process
- starts from white noise
- reverse the forward process with a model (U-Net or transformer): \[p_\theta(x_{t-1}|x_t) = N(x_{t-1}, \mu_\theta(x_t,t), \Sigma_\theta(x_t,t))\]
- iteratively denoise
Many text diffusion models

(from PMC24)
Comparison
- Diffusion models are much slower than LLM, because of many sampling steps
- But they produce a complete sentence at each step
Case study: Llama3.1
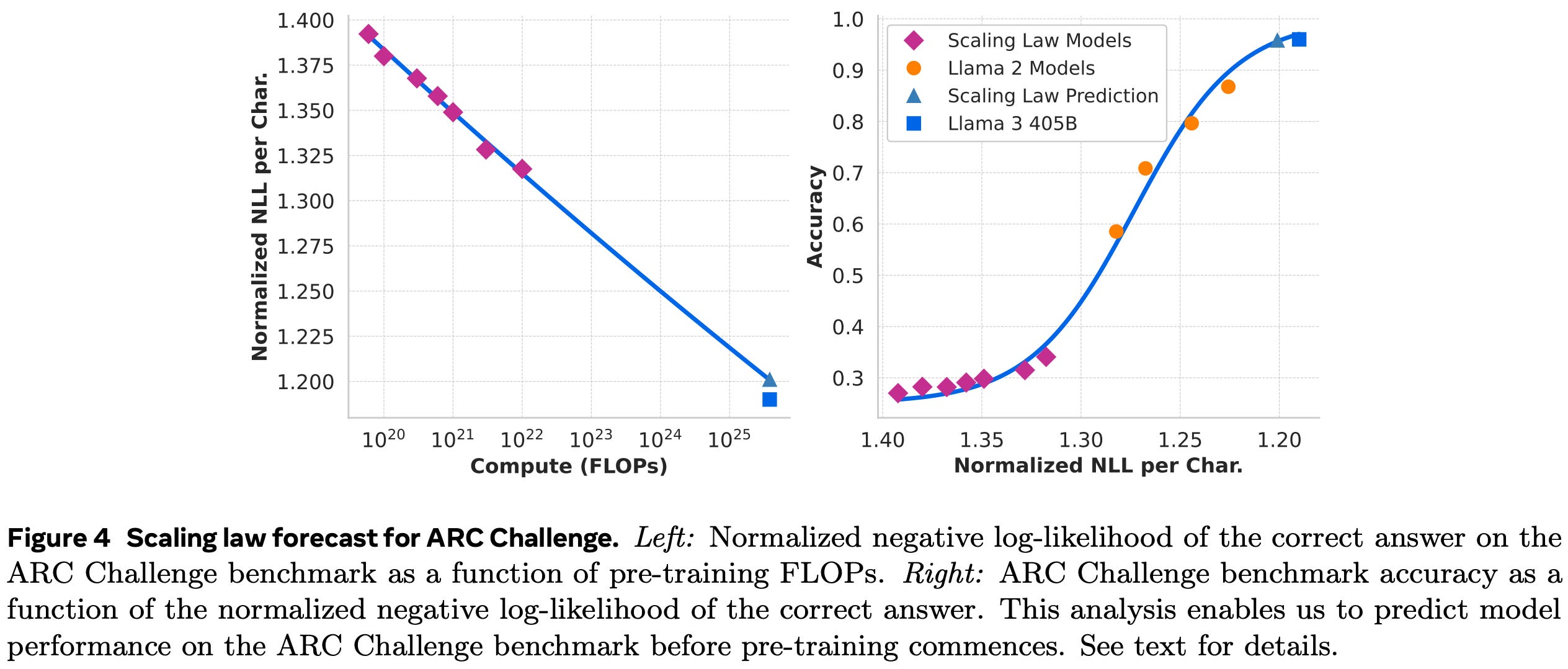
- Main constraint = training compute = \(3.8\times 10^{25}\) FLOPs
- Chinchilla scaling laws not precise enough at that scale, and not for end-task accuracy
- so they recompute they own scaling laws on ARC challenge benchmark!
- They fix compute \(c\) (from \(10^{18}\) to \(10^{22}\) FLOPs)
- They pick a model size \(s\), deduce from \((s,c)\) the nb of data points \(d\) the model can be trained on
- They train it, get the dev loss \(l(s,c,d)\)
- They plot the point \((x=d,y=l)\)
and iterate for a few other \(s\)
- For each \(c\), they get a quadratic curve: why?
- Because:
- the largest model is more costly to train, so it’s trained on the fewest data (\(x_{min}\))
- when it’s too large, it’s trained on too few data \(\rightarrow\) high loss
- the smallest model is trained on lots of data (\(x_{max}\))
- but it has too few parameters to memorize information \(\rightarrow\) high loss
- so there’s a best compromise in between
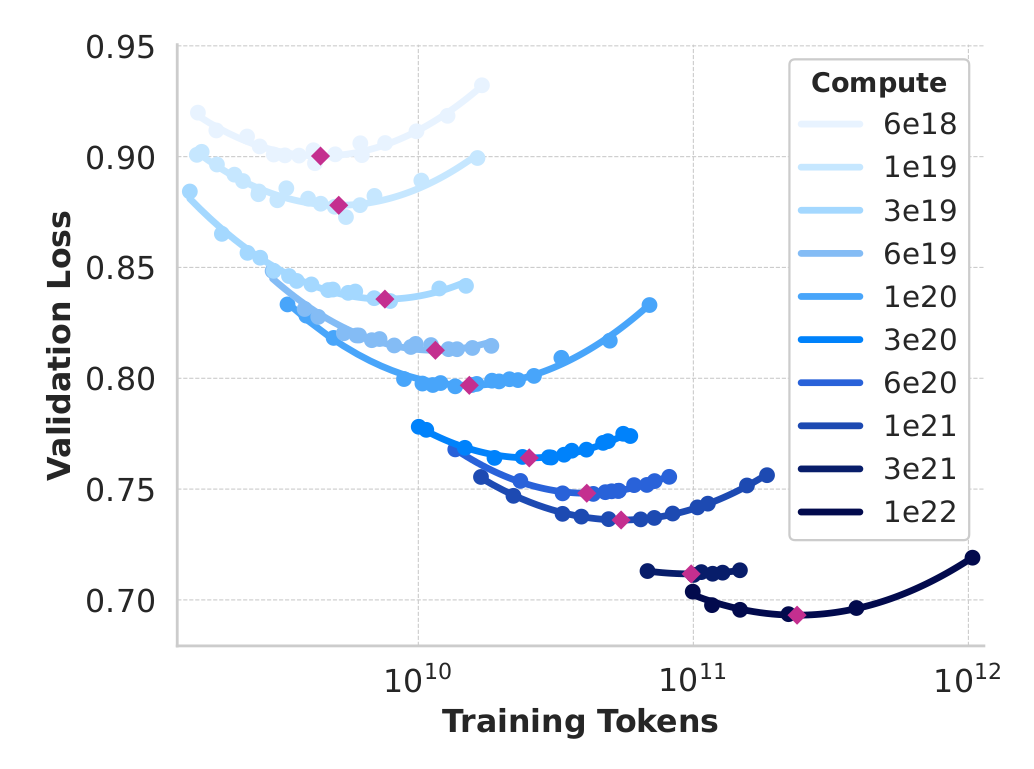
- Terms to remind:
- compute = nb of operations to train
- IsoFLOP curve = plot obtained at a constant compute
- compute-optimal model = minimum of an IsoFLOP curve
- But these scaling laws are mostly computed at “low” FLOPs range
- So they compute for these models & the largest llama2 models both the dev loss and accuracy
- Assume accuracy = sigmoid(test loss)
- Extrapolate the scaling law with this relation, and get 405b parameters
Pretraining
- After data processing, the most important step:
- store all knowledge into the LLM
- develop emergent capabilities
- Most difficult step
Principle:
- Train model on very large textual datasets
- ThePile
- C4
- RefinedWeb
- …
Which tasks for training?
- predict next token (GPT)
- predict masked token (BERT)
- next sentence prediction (BERT)
- denoising texts (BART)
- pool of “standard” NLP tasks (T5, T0pp):
- NLI, sentiment, MT, summarization, QA…
Multilingual models:
- old models:
- XLM-R
- trained on 100 languages
- Bloom, M-BERT, M-GPT…
- new models:
- Qwen2: 29 languages
- all LLMs!
Training
- Next token prediction
Training algorithm: SGD
- Initialize parameters \(\theta\) of LLM \(f_\theta()\)
- Stochastic Gradient Descent:
- Sample 1 training example \((x_{1\dots T-1},y_T)\)
- Compute predicted token \(\hat y_T = f_\theta(x_{1\dots T-1})\)
- Compute cross-entropy loss \(l(\hat y_T, y_T)\)
- Compute gradient \(\nabla_\theta l(\hat y_T, y_T)\)
- Update \(\theta' \leftarrow \theta -\epsilon \nabla_\theta l(\hat y_T, y_T)\)
- Iterate with next training sample
Compute gradient: back-propagation
- Compute final gradient \(\frac{\partial l(\hat y_T, y_T)}{\partial \theta_{L}}\)
- Iterate backward:
- Given “output” gradient \(\frac{\partial l(\hat y_T, y_T)}{\partial \theta_{i+1}}\)
- Compute “input” gradient: \(\frac{\partial l(\hat y_T, y_T)}{\partial \theta_{i}} = \frac{\partial l(\hat y_T, y_T)}{\partial \theta_{i+1}} \frac{\partial \theta_{i+1}}{\partial \theta_i}\)
- every operator in pytorch/tensorflow is equipped with its local derivative \(\frac{\partial \theta_{i+1}}{\partial \theta_i}\)
Key ingredients to success:
- The prediction task is forcing the model to learn every linguistic level
- The model must be able to attend long sequences
- Impossible with ngrams
- The model must have enough parameters
- Impossible without modern hardware
- The model must support a wide range of functions
- Impossible before neural networks
- The data source must be huge
LLMs store knowledge
- “In order to cook bacon, you…”
- “place the bacon in a large skillet and cook over medium heat until crisp.”
- “The main characters in Shakespeare’s play Richard III are…”
- “Richard of Gloucester, his brother Edward, and his nephew, John of Gaunt”
LLMs “reason”
- “On a shelf, there are five books: a gray book, a red book, a purple
book, a blue book, and a black book. The red book is to the right of the
gray book. The black book is to the left of the blue book. The blue book
is to the left of the gray book. The purple book is the second from the
right. Which book is the leftmost book?”
- “The black book”
- “Reasoning” capacity acquired by next token prediction:
- famous Ilya Sutskever’s example: imagine a detective book that distills cues and hints all along the story and finish with: “Now, it is clear that the culprit is…”
- “Reasoning” of an LLM:
- Match/combine subgraphs ?
- Pretraining wrap-up:
- “next token prediction” objective \(\rightarrow\) knowledge storing + reasoning
- Simple training algorithm to do that: SGD with backprop
- But needs training at scale
- Training at scale is very hard:
- trillions training steps \(\rightarrow\) GPUs are mandatory (Llama3.1 trained on 16k A100 simultaneously)
- billions parameters \(\rightarrow\) need to shard data + LLM across GPUs
- data/model/compute Parallelization is key
Training at scale
Data P., model sharding, Tensor P., Sequence P., pipeline P…
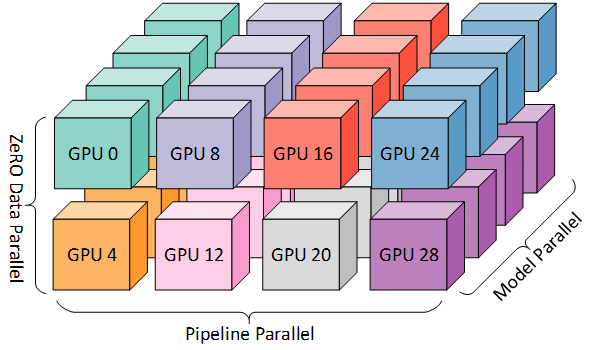
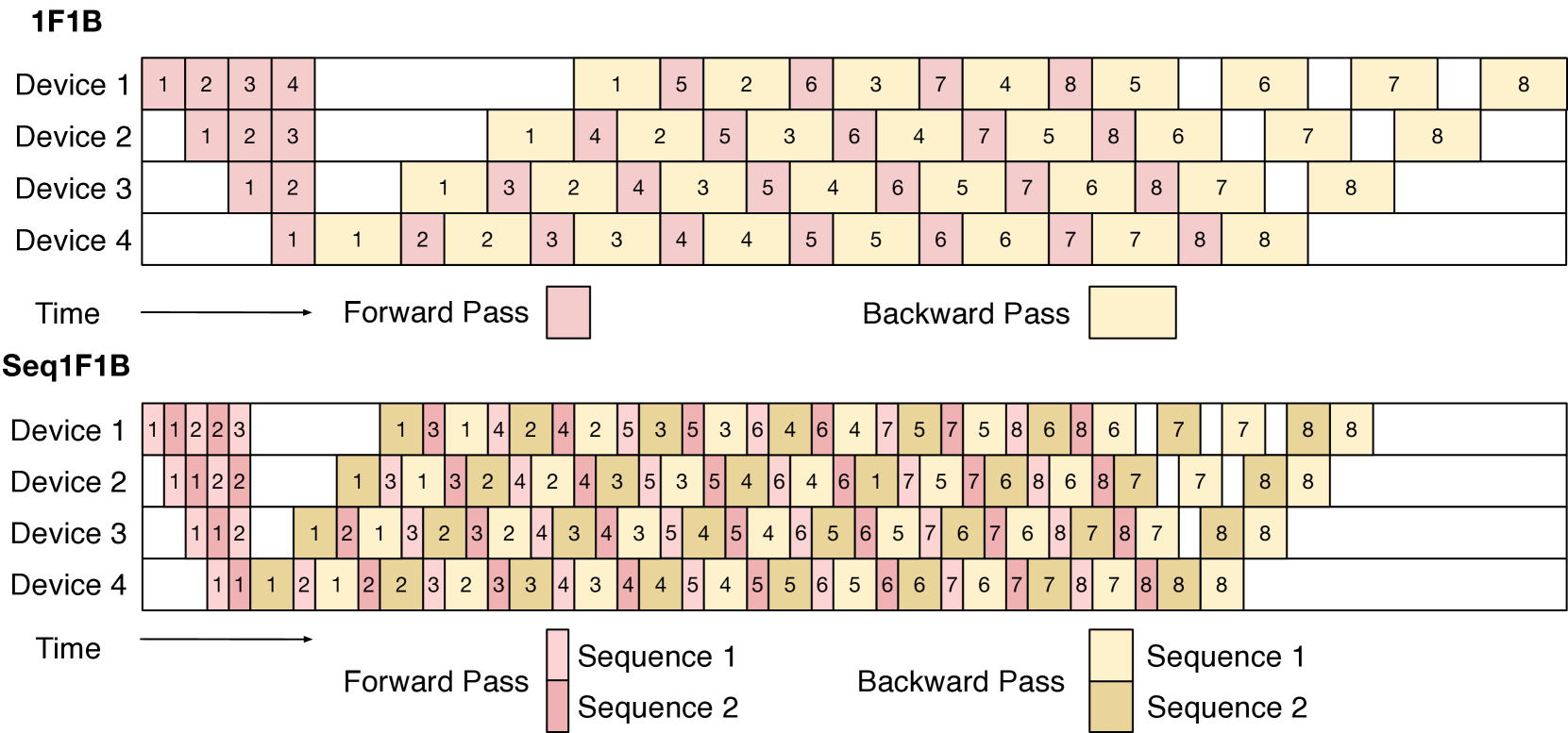
- Tooling:
- Megatron-DS
- Deep Speed
- Accelerate
- Axolotl
- Llama-factory
- GPT-NeoX
- MS-Swift…
Practice: training
Objectives:
- Manual training loop with transformers, pytorch Dataset and DataLoader
- Understanding batching in practice
- Track the training curves
- Download the following code, which is a draft of a code to train a distilGPT2 with batchsize>1: train.py
- This code is buggy!
- Debug it to make it run with batchsize=1
- Then debug it to make it run with batchsize=4
- In both cases, track the training loss and compares
Local usage
- Directly use the LLM for the target task
- Zero-Shot Learning, prompt engineering…
- Adapt the LLM to the task
- Finetuning, model merging…
- Integrate the LLM with other soft
- function calling, tools using, LLM agents
- Generate synthetic training data
Zero-Shot Learning (teaser)
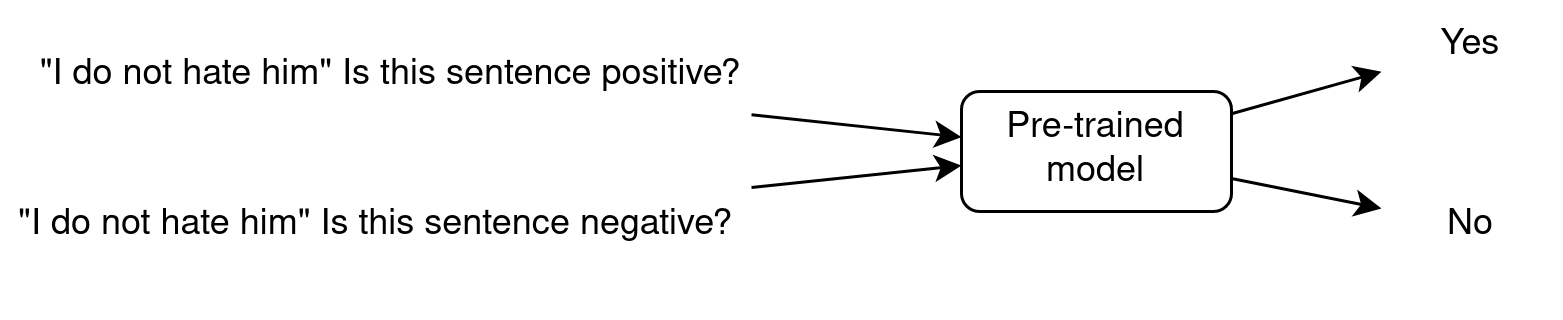
- Zero-Shot because the LLM has been trained on task A (next word prediction) and is used on task B (sentiment analysis) without showing it any example.
In-context Few-Shot Learning
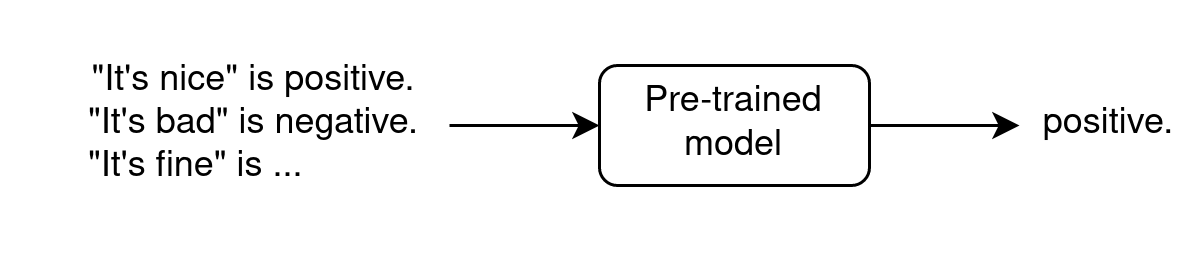
- requires very few annotated data
- In context because examples are shown as input
- does not modify parameters
- see paper “Towards Zero-Label Language Learning” (GoogleAI, sep 2021)
As frozen embeddings
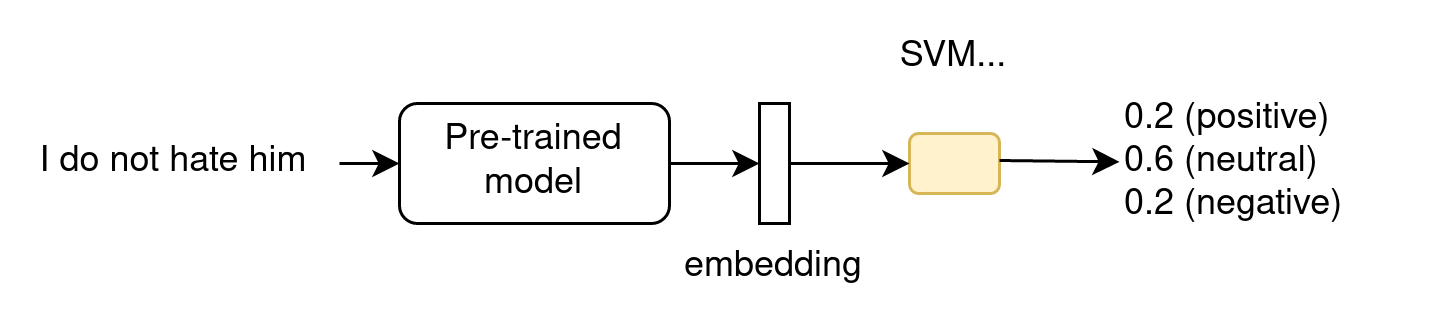
- does not modify the LLM parameters
- for ML-devs, as the LLM is part of a larger ML architecture
Modifying LLM parameters
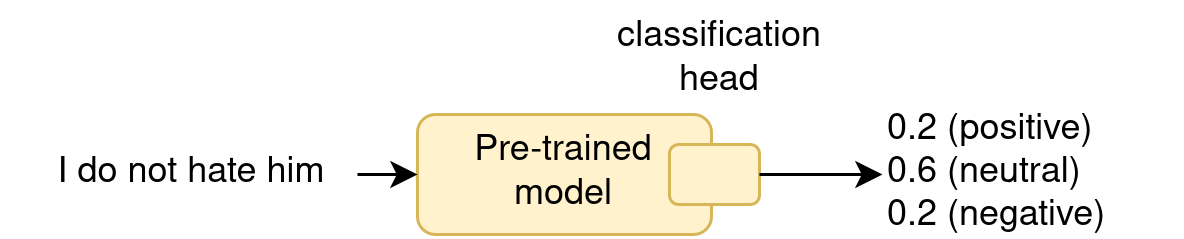
- Many ways to finetune:
- often give the best results
- full, half, sparse… finetuning
- finetuning with new parameters: adapters…
- finetuning without new parameters: LoRA…
- often give the best results
- Model merging
| Finetuning | Continual pretraining |
|---|---|
| Adapt to domain/lang/task | acquire new knowledge |
| LLM looses other capacities | capture language drift |
| stays generic and adaptable | |
Major issues
| Finetuning | Continual pretraining |
|---|---|
| overfitting | overfitting |
| catastrophic forgetting | |
| overcoming reduced learnability | |
| cost |
Prompt engineering
- Prompt = input (text) to the LLM
- composed of: system prompt, context, instructions, query, dialogue history, tools…
- A lot can be done without finetuning, just by changing the prompt
- The prompt depends on the model type:
- Foundation model: “text continuation” type of prompt; think as if it’s a web page
- Instruct LLM: add instructions
- Chat LLM: add dialogue history
- Coder LLM: add pieces of code…
- Relies on In-Context Learning capability
- Vanilla prompting
- Chain-of-thought (CoT)
- Self-consistency
- Ensemble refinment
- Automatic chain-of-thought (Auto-CoT)
- Complex CoT
- Program-of-thoughts (PoT)
- Least-to-Most
- Chain-of-Symbols (CoS)
- Structured Chain-of-Thought (SCoT)
- Plan-and-solve (PS)
- MathPrompter
- Contrastive CoT/Contrastive self-consistency
- Federated Same/Different Parameter self-consistency/CoT
- Analogical reasoning
- Synthetic prompting
- Tree-of-toughts (ToT)
- Logical Thoughts (LoT)
- Maieutic Prompting
- Verify-and-edit
- Reason + Act (ReACT)
- Active-Prompt
- Thread-of-thought (ThOT)
- Implicit RAG
- System 2 Attention (S2A)
- Instructed prompting
- Chain-of-Verification (CoVe)
- Chain-of-Knowledge (CoK)
- Chain-of-Code (CoC)
- Program-Aided Language Models (PAL)
- Binder
- Dater
- Chain-of-Table
- Decomposed Prompting (DeComp)
- Three-Hop reasoning (THOR)
- Metacognitive Prompting (MP)
- Chain-of-Event (CoE)
- Basic with Term definitions
- Basic + annotation guideline + error-analysis- lists the best prompting techniques for every possible NLP task.
- Another survey of prompt engineering
Prompt engineering
- It’s the process/workflow to design a prompt:
- define tasks
- write prompts
- test prompts
- evaluate results
- refine prompts; iterate from step 3
Template of prompt
<OBJECTIVE_AND_PERSONA>
You are a [insert a persona, such as a "math teacher" or "automotive expert"]. Your task is to...
</OBJECTIVE_AND_PERSONA>
<INSTRUCTIONS>
To complete the task, you need to follow these steps:
1.
2.
...
</INSTRUCTIONS>
------------- Optional Components ------------
<CONSTRAINTS>
Dos and don'ts for the following aspects
1. Dos
2. Don'ts
</CONSTRAINTS>
<CONTEXT>
The provided context
</CONTEXT>
<OUTPUT_FORMAT>
The output format must be
1.
2.
...
</OUTPUT_FORMAT>
<FEW_SHOT_EXAMPLES>
Here we provide some examples:
1. Example #1
Input:
Thoughts:
Output:
...
</FEW_SHOT_EXAMPLES>
<RECAP>
Re-emphasize the key aspects of the prompt, especially the constraints, output format, etc.
</RECAP>Best practices
- Do not start from scratch, better use a template or example of prompt
- the role/persona is important:
- It can be used to generate synthetic data
- To get variable outputs, much better to change the persona than generate with beam search
- may use prefixes for simple prompts:
TASK:
Classify the OBJECTS.
CLASSES:
- Large
- Small
OBJECTS:
- Rhino
- Mouse
- Snail
- Elephant- may use XML or JSON for complex prompts
Few-Shot Learning
- Add a few examples of the task in the prompt
- requires large enough LLM
- few-shot examples are mainly used to define the format, not the content!
Ask for explanations
What is the most likely interpretation of this sentence? Explain your reasoning. The sentence: “The chef seasoned the chicken and put it in the oven because it looked pale.”
- Llama3.1-7b: “[…] the chef thought the chicken was undercooked or not yet fully cooked due to its pale appearance […]”
CoT workflow
- break the pb into steps
- find good prompt for each step in isolation
- tweak the steps to work well together
- enhance with finetuning:
- generate synthetic samples to tune each step
- finetune small LLMs on these samples
CoT for complex tasks
Extract the main issues and sentiments from the customer feedback on our telecom services.
Focus on comments related to service disruptions, billing issues, and customer support interactions.
Please format the output into a list with each issue/sentiment in a sentence, separated by semicolon.
Input: CUSTOMER_FEEDBACKClassify the extracted issues into categories such as service reliability, pricing concerns, customer support quality, and others.
Please organize the output into JSON format with each issue as the key, and category as the value.
Input: TASK_1_RESPONSEGenerate detailed recommendations for each category of issues identified from the feedback.
Suggest specific actions to address service reliability, improving customer support, and adjusting pricing models, if necessary.
Please organize the output into a JSON format with each category as the key, and recommendation as the value.
Input: TASK_2_RESPONSECoT for simpler tasks
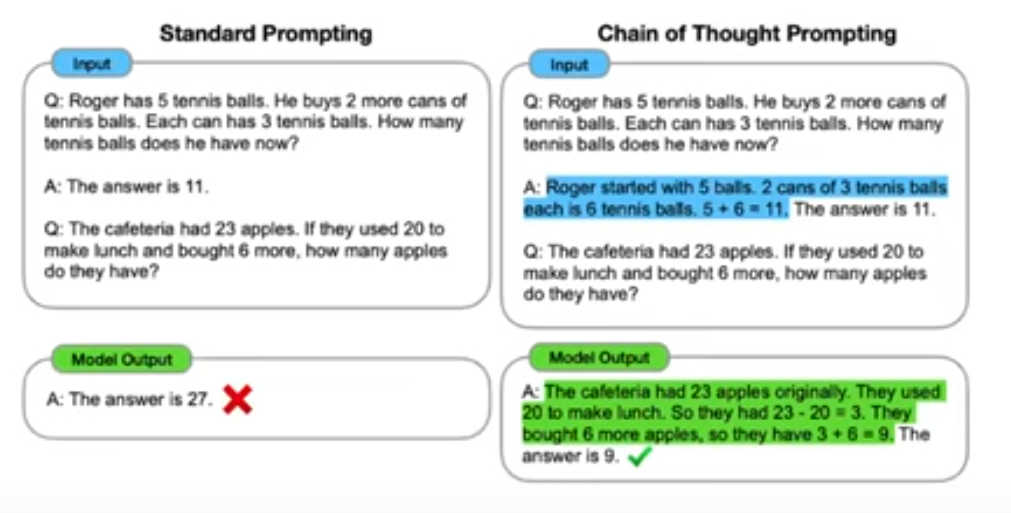
CoT requires large models:
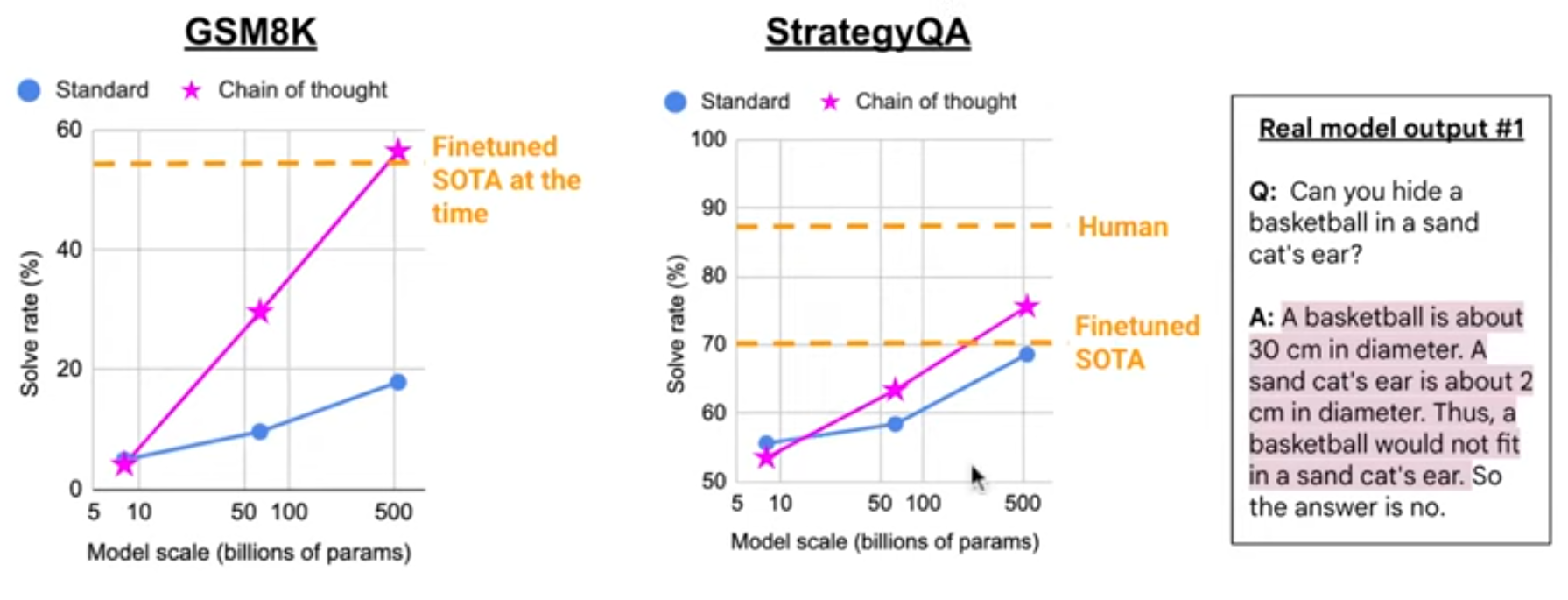
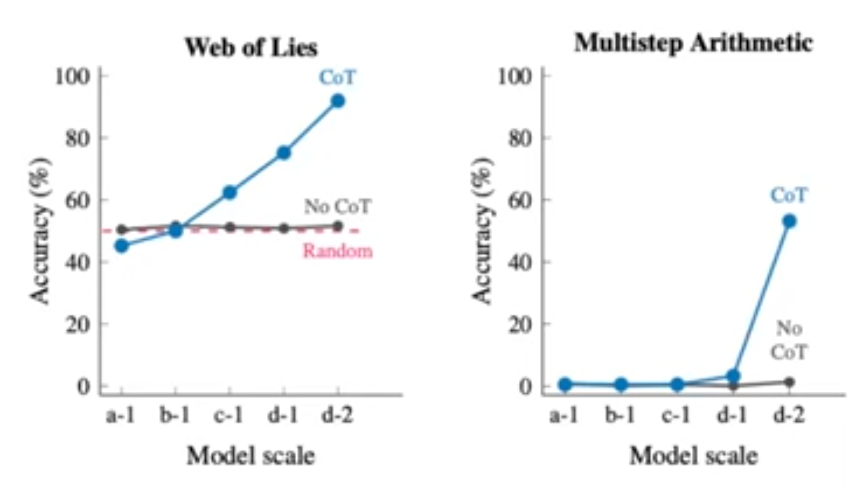
Self-consistency
- Self-consistency greatly improves CoT prompting
- For one (CoT prompts, question) input, sample multiple outputs
- take majority vote among outputs
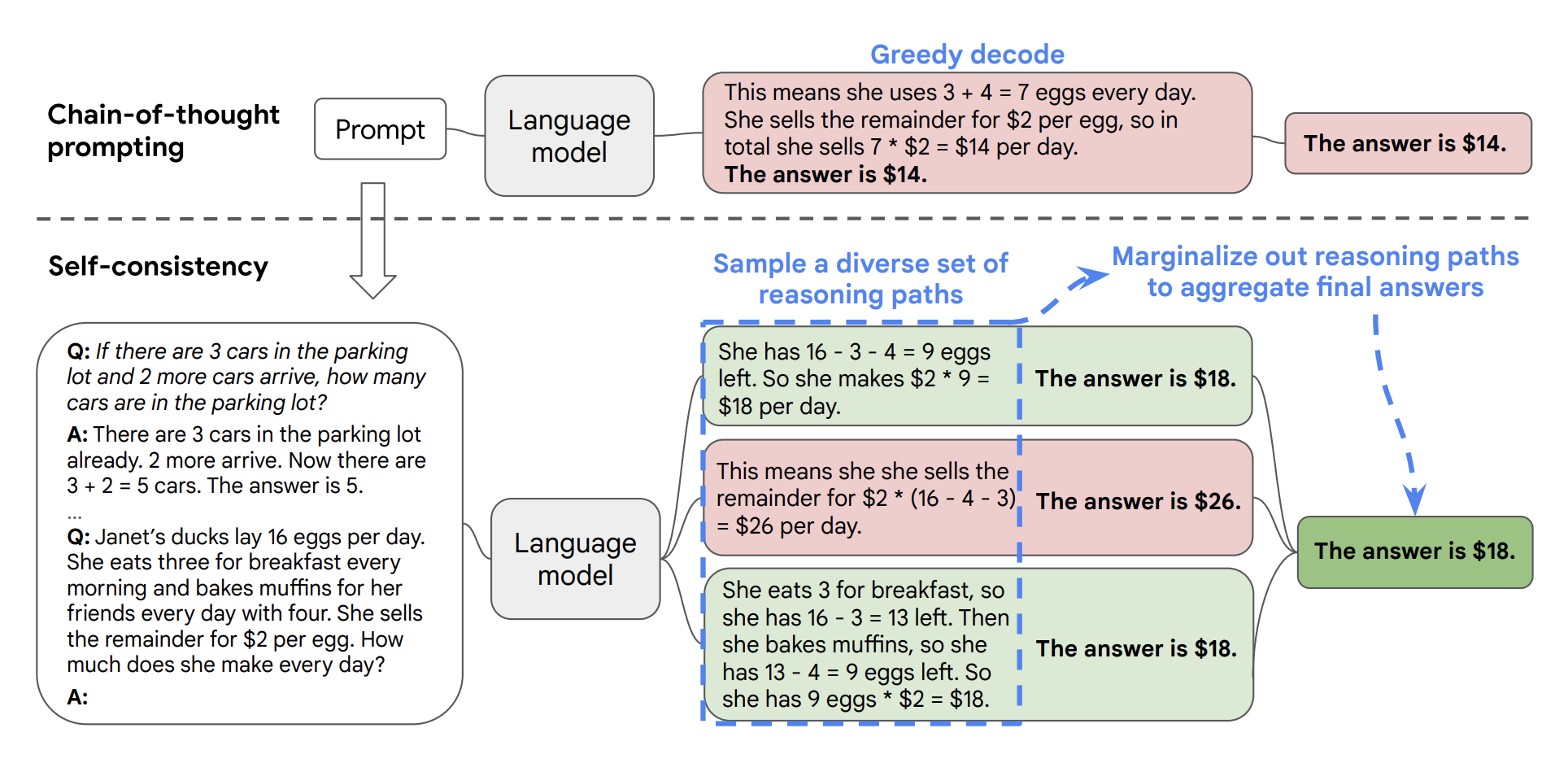
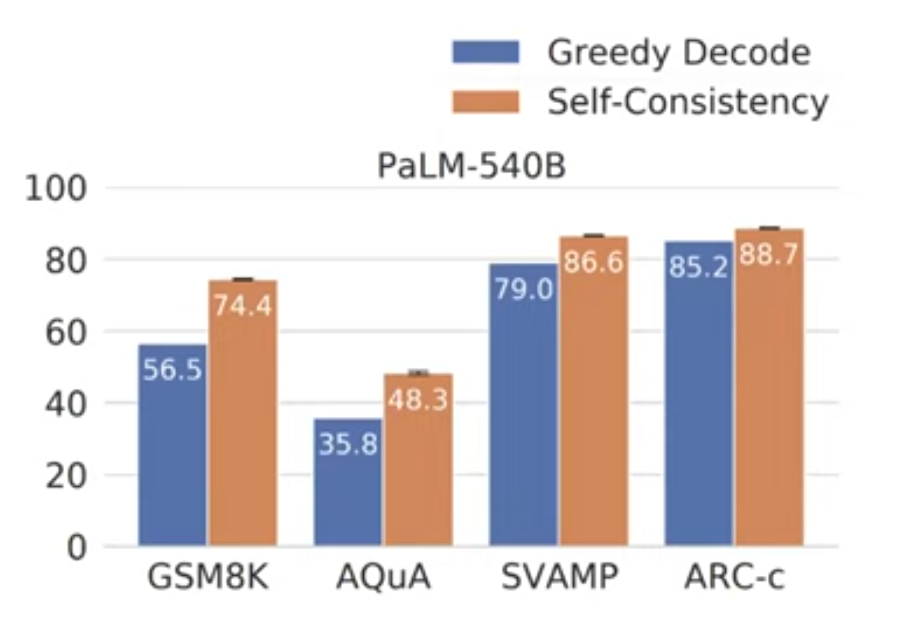
Analogical prompting
- Few-Shot with self-generated examples:
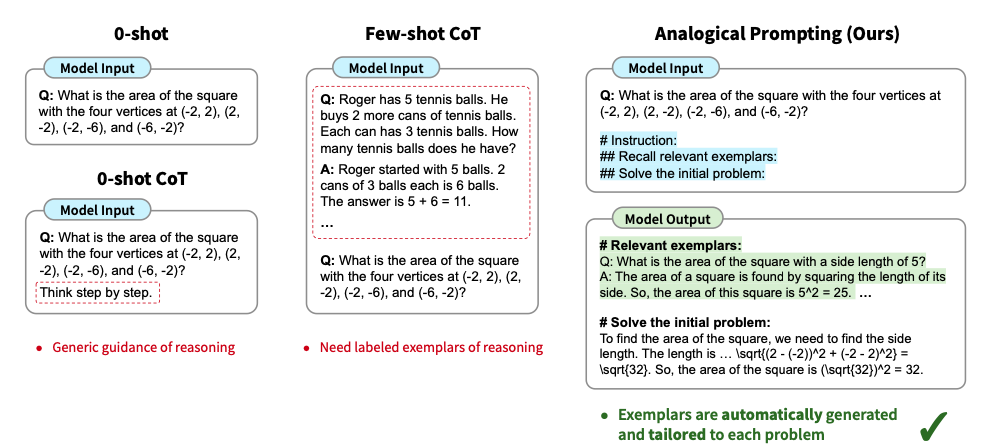
ReAct prompting
- Principle: Ask the LLM to interleave multiple steps of reasoning and actions
- Workflow:
- First devise few-shot examples
- Adapt a SOTA ReAct prompt
- Test, evaluation, iterate
- ReAct prompt decomposition:
- Primary instruction: “Solve a question answering task…”
- ReAct steps: “… with interleaving Thought, Action, Observation steps”
- Reasoning: “Thought can reason about the current situation”
- Actions: “Actions can be of three types: Search[entity], which searches…; Lookup[keyword], which returns the next sentence containing keyword in the current passage; Finish[answer], which returns the answer and finished the task”
- ReAct few-shot examples:
Question What is the elevation range for the area that the eastern sector of the
Colorado orogeny extends into?
Thought 1 I need to search Colorado orogeny, find the area that the eastern sector
of the Colorado orogeny extends into, then find the elevation range of the
area.
Action 1 Search[Colorado orogeny]
Observation 1 The Colorado orogeny was an episode of mountain building (an orogeny) in
Colorado and surrounding areas.
Thought 2 It does not mention the eastern sector. So I need to look up eastern
sector.
Action 2 Lookup[eastern sector]
Observation 2 (Result 1 / 1) The eastern sector extends into the High Plains and is called
the Central Plains orogeny.
Thought 3 The eastern sector of Colorado orogeny extends into the High Plains. So I
need to search High Plains and find its elevation range.Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with?

Examples of prompts
- See Google cloud examples
- See Prompt Hub
Prompt tuning: DSPy
- DSPy uses LM-driven optimizers to tune prompts and weights
- DSPy concepts:
- LLMs are blackboxes with inputs/outputs described in English
- program = LLMs connected together/used by a program
- compiler = try to find the best prompts
DSPy compilers
- LabeledFewShot: sample randomly examples from training set and add them as demos (few-shots) in the prompt
- BootstrapFewShot:
- create Teacher program = run LabeledFewShot on the Student program
- Evaluate teacher on the train set, keeping when it’s correct
- Add the kept demos as few-shot
- …
Basic usage of DSPy
- launch an LLM provider, e.g., ollama
import dspy
lm = dspy.LM(model="ollama/qwen2.5", api_base="http://localhost:11434")
dspy.configure(lm=lm)
qa = dspy.Predict('question: str -> response: str')
response = qa(question="what are high memory and low memory on linux?")
print(response.response)
dspy.inspect_history(n=1)- What is a typical prompt used for Chain of Thought?
cot = dspy.ChainOfThought('question -> response')
res = cot(question="should curly braces appear on their own line?")
print(res.response)
dspy.inspect_history(n=1)- Let’s evaluate on a MATH benchmark:
from dspy.datasets import MATH
dataset = MATH(subset='algebra')
dev = dataset.dev[0:10]
example = dataset.train[0]
print("Question:", example.question)
print("Answer:", example.answer)
module = dspy.ChainOfThought("question -> answer")
print(module(question=example.question))
evaluate = dspy.Evaluate(devset=dev, metric=dataset.metric)
evaluate(module)- Going further:
Practical session: RAG optimization
- Prompt engineering = manual prompt optimization
- Auto-prompt optimization: DSPy, AdalFlow…
- Components that can be optimized:
- System prompt (CoT)
- Few-shot examples
- LLM parameters…
Implementing a RAG with DSPy; required imports:
import dspy
from dspy.teleprompt import BootstrapFewShot
from dspy.datasets import HotPotQA
from dspy.evaluate import Evaluate
from sentence_transformers import SentenceTransformer
import pandas as pd
from dspy.evaluate.evaluate import Evaluate- Get database of biological documents:
passages0 = pd.read_parquet("hf://datasets/rag-datasets/rag-mini-bioasq/data/passages.parquet/part.0.parquet")
test = pd.read_parquet("hf://datasets/rag-datasets/rag-mini-bioasq/data/test.parquet/part.0.parquet")
passages = passages0[0:20]- Build a retriever on these passages:
class RetrievalModel(dspy.Retrieve):
def __init__(self, passages):
self.passages = passages
self.passages["valid"] = self.passages.passage.apply(lambda x: len(x.split(' ')) > 20)
self.passages = self.passages[self.passages.valid]
self.passages = self.passages.reset_index()
for i,x in enumerate(self.passages.passage.tolist()):
print("DOC",i,x)
self.model = SentenceTransformer("all-MiniLM-L6-v2")
self.passage_embeddings = self.model.encode(self.passages.passage.tolist())
def __call__(self, query, k):
query_embedding = self.model.encode(query)
similarities = self.model.similarity(query_embedding, self.passage_embeddings).numpy() # cosine similarities
top_indices = similarities[0, :].argsort()[::-1][:k] # pick TopK documents having highest cosine similarity
response = self.passages.loc[list(top_indices)]
response = response.passage.tolist()
return [dspy.Prediction(long_text= psg) for psg in response]
rm = RetrievalModel(passages)- Test retriever:
qq = "Which cell may suffer from anemia?"
print(rm(qq,2))- Add the generator LLM:
llm = dspy.LM(model="ollama/qwen2.5:0.5b", api_base="http://localhost:11434")
print("llm ok")
dspy.settings.configure(lm=llm,rm=rm)- Define the RAG module:
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
class RAG(dspy.Module):
def __init__(self, num_passages=2):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)- Test your RAG:
rag = RAG()
pred = rag(qq)
print(f"Question: {qq}")
print(f"Predicted Answer: {pred.answer}")
print(f"Retrieved Contexts (truncated): {[c[:200] + '...' for c in pred.context]}")
llm.inspect_history(n=1)- Build a train and dev set:
dataset = []
for index, row in test.iterrows():
dataset.append(dspy.Example(question=row.question, answer=row.answer).with_inputs("context", "question"))
trainset, devset = dataset[:4], dataset[17:20]- Define an evaluation metric:
def validate_context_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer_exact_match(example, pred)
answer_PM = dspy.evaluate.answer_passage_match(example, pred)
return answer_EM and answer_PM- Evaluate quantitatively your RAG:
valuate_on_devset = Evaluate(devset=devset, num_threads=1, display_progress=True, display_table=10)
evalres = evaluate_on_devset(rag, metric=validate_context_and_answer)
print(f"Evaluation Result: {evalres}")- Add few-shot samples automatically sampled/optimised from the train set:
teleprompter = BootstrapFewShot(metric=validate_context_and_answer, max_bootstrapped_demos=2, max_labeled_demos=2)
compiled_rag = teleprompter.compile(rag, trainset=trainset)
evalres = evaluate_on_devset(compiled_rag, metric=validate_context_and_answer)
print(f"Evaluation Result: {evalres}")
llm.inspect_history(n=1)- TODO:
- run these steps one after the other, and check how the LLM prompt changes
- define a metric that favours short answers and optimize your prompts accordingly
- implement multi-hop RAG in DSPy (see next slides)
- Multi-hop RAG is when decomposing a single RAG query into multiple steps
- The following code shows using a vector-DB
- TODO: in the following code:
- add the LLM with Ollama
- add both missing DSPy signatures
- add more phones from the “Amazon Reviews: Unlocked Mobile Phones” Kaggle dataset
- execute the code
- Multi-hop RAG draft:
import dspy
from dsp.utils import deduplicate
from dspy.teleprompt import BootstrapFewShot
from dspy.retrieve.qdrant_rm import QdrantRM
from qdrant_client import QdrantClient
formatted_list = ["Phone Name: HTC Desire 610 8GB Unlocked GSM 4G LTE Quad-Core Android 4.4 Smartphone - Black (No Warranty)\nReview: The phone is very good , takes very sharp pictures but the screen is not bright'",
"Phone Name: Apple iPhone 6, Space Gray, 128 GB (Sprint)\nReview: I am very satisfied with the purchase, i got my iPhone 6 on time and even received a screen protectant with a charger. Thank you so much for the iPhone 6, it was worth the wait.",
]
client = QdrantClient(":memory:")
def add_documents(client, collection_name, formatted_list, batch_size=10):
for i in range(0, len(formatted_list), batch_size):
batch = formatted_list[i:i + batch_size]
batch_ids = list(range(i + 1, i + 1 + len(batch)))
client.add(
collection_name=collection_name,
documents=batch,
ids=batch_ids
)
print(f"Batch {i // batch_size + 1} added with {len(batch)} documents.")
add_documents(client, "phone_collection", formatted_list)
qdrant_retriever_model = QdrantRM("phone_collection", client)
dspy.settings.configure(lm= llm, rm=qdrant_retriever_model)
class Multihoprag(dspy.Module):
def __init__(self, passages_per_hop=3, max_hops=2):
super().__init__()
self.generate_query = [dspy.ChainOfThought(GenerateSearchQuery) for _ in range(max_hops)]
self.retrieve = dspy.Retrieve(k=passages_per_hop)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
self.max_hops = max_hops
def forward(self, question):
context = []
for hop in range(self.max_hops):
query = self.generate_query[hop](context=context, question=question).query
passages = self.retrieve(query).passages
context = deduplicate(context + passages)
pred = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=pred.answer)
trainset_list = [
{
"Question": "Which phones have the best camera quality and battery life based on recent reviews and specifications?",
"Answer": "Here's a list of phones that meet your criteria:\n\n1. Samsung Galaxy S21 Ultra\n2. Google Pixel 6 Pro\n3. Apple iPhone 13 Pro Max\n4. OnePlus 9 Pro\n5. Xiaomi Mi 11 Ultra\n\nNotes: These phones were picked based on their high ratings for camera quality and long-lasting battery life, as reported by recent reviews and detailed specifications."
},
{
"Question": "What are the top-rated phones with the best display and performance in the market right now?",
"Answer": "Here's a list of phones that meet your criteria:\n\n1. Samsung Galaxy S22\n2. Apple iPhone 14 Pro\n3. OnePlus 10 Pro\n\nNotes: These phones were selected because they have received excellent reviews for their display clarity and performance speed, making them ideal for users seeking high-quality visuals and efficient processing."
},
{
"Question": "Can you recommend phones that have the best user interface and build quality according to recent user reviews?",
"Answer": "Here's a list of phones that meet your criteria:\n\n1. Nokia 8.3 5G\n2. Sony Xperia 1 III\n\nNotes: These phones were chosen due to their outstanding user interface design and robust build quality, which have been highly praised in recent user reviews and expert evaluations."
}
]
trainset = [dspy.Example(question=item["Question"], answer=item["Answer"]).with_inputs('question') for item in trainset_list]
# metric function that prefers short and non-repetitive answers
def validate_answer_and_hops(example, pred, trace=None):
# if not validate(pred.answer == example.answer): return False
hops = [example.question] + [outputs.query for *_, outputs in trace if 'query' in outputs]
if max([len(h) for h in hops]) > 100: return False
if any(dspy.evaluate.answer_exact_match_str(hops[idx], hops[:idx], frac=0.8) for idx in range(2, len(hops))): return False
return True
teleprompter = BootstrapFewShot(metric=validate_answer_and_hops, )
uncompiled_rag = Multihoprag()
compiled_rag = teleprompter.compile(student=uncompiled_rag, trainset= trainset)
print(uncompiled_rag("Which smartphones are highly rated for its low-light camera performance also have a great front camera"))
print(compiled_rag("Which smartphones are highly rated for its low-light camera performance also have a great front camera"))Finetuning
- Finetuning = continue training the AI model on domain-specific data
- The training objective may change (e.g., new image classification)
- Or it may stay the same as pretraining (e.g., language modeling)
- Pretraining \(\rightarrow\) Foundation models
- Finetuning \(\rightarrow\) Domain-specific models
- Why not just training a small model from scratch on the target
domain?
- Transfer learning: we expect to transfer capabilities from the generic AI to get a better target model
- Small data: we often don’t have enough domain data to train a small model from scratch, but specializing the generic AI model usually requires few data
- Stochastic Gradient Descent (SGD) algorithm:
- You need a training corpus \(C = \{x_i,y_i\}_{1\leq i\leq N}\)
- Initialize the model’s parameters randomly: \(\theta_i \sim \mathcal{N}(0,\mu,\Sigma)\)
- Forward pass: sample one example \(x_i \sim \mathcal{U}(C)\) and predict its output: \(\hat y=f_{\theta}(x_i)\)
- Compute the loss = error made by the model: \[l(\hat y, y_i) = ||\hat y - y_i||^2\]
- Backward pass: compute the gradient of the loss with respect to each parameter: \[\nabla l(\hat y, y_i) = \left[ \frac {\partial l(\hat y, y_i)}{\partial \theta_k}\right]\]
- Update parameters: \(\theta_k \leftarrow \theta_k - \epsilon \frac {\partial l(\hat y, y_i)}{\partial \theta_k}\)
- Iterate from the forward pass
- Backpropagation algorithm (for the backward pass):
- Compute the derivative of the loss wrt the output: \(\frac {\partial l(\hat y, y_i)}{\partial \theta_T}\)
- Use the chain rule to deduce the derivative of the loss after the op just before: \[\frac {\partial l(\hat y, y_i)}{\partial \theta_{T-1}} = \frac {\partial l(\hat y, y_i)}{\partial \theta_T} \times \frac {\partial \theta_T}{\partial \theta_{T-1}}\]
- Only requires to know the analytic derivative of each op individually
- Iterate back to the input of the model
Motivation for PEFT
- PEFT = Parameter-Efficient Fine-Tuning
- It’s just finetuning, but cost-effective:
- only few parameters are finetuned
- cheaper to train
- cheaper to distribute
When do we need finetuning?
- Improve accuracy, adapt LLM behaviour
- Finetuning use cases:
- Follow instructions, chat…
- Align with user preferences
- Adapt to domain: healthcare, finance…
- Improve on a target task
- So finetuning is just training on more data?
- Yes:
- Same training algorithm (SGD)
- No:
- different hyperparms (larger learning rate…)
- different type of data
- higher quality, focused on task
- far less training data, so much cheaper
- not the same objective:
- adaptation to domain/style/task/language…
Pretrained LLM compromise
- Training an LLM is fundamentally a compromise:
- training data mix: % code/FR/EN…
- text styles: twitter/books/PhD…
- Pretraining data mix defines where the LLM excels
- Finetuning modifies this equilibrum to our need
- The art of pretraining:
- finding the balance that fits most target users’ expectation
- finding the balance that maximizes the LLM’s capacities +
adaptability
- e.g., pretraining only on medical data gives lower performance even in healthcare, because of limited data size and lack of variety.
- But for many specialized tasks, pretrained LLM does not give the
best performance:
- Finetuning adapts this compromise
- So finetuning is required for many specialized domains:
- enterprise documentations
- medical, finance…
- But it is costly to do for large LLMs:
- collecting, curating, cleaning, formatting data
- tracking training, preventing overfitting, limiting forgetting
- large LLMs require costly hardware to train
- For instance, finetuning LLama3.1-70b requires GPUs with approx. 1TB
of VRAM
- = 12x A100-80GB
- Can’t we avoid finetuning at all, but still adapt the LLM to our task?
If the LLM good enough, no need to finetune?
- Alternative: prompting
- “Be direct and answer with short responses”
- “Play like the World’s chess champion”
- Alternative: memory/long context/RAG
- “Adapt your answers to all my previous interactions with you”
- Alternative: function calling
- “Tell me about the events in July 2024”
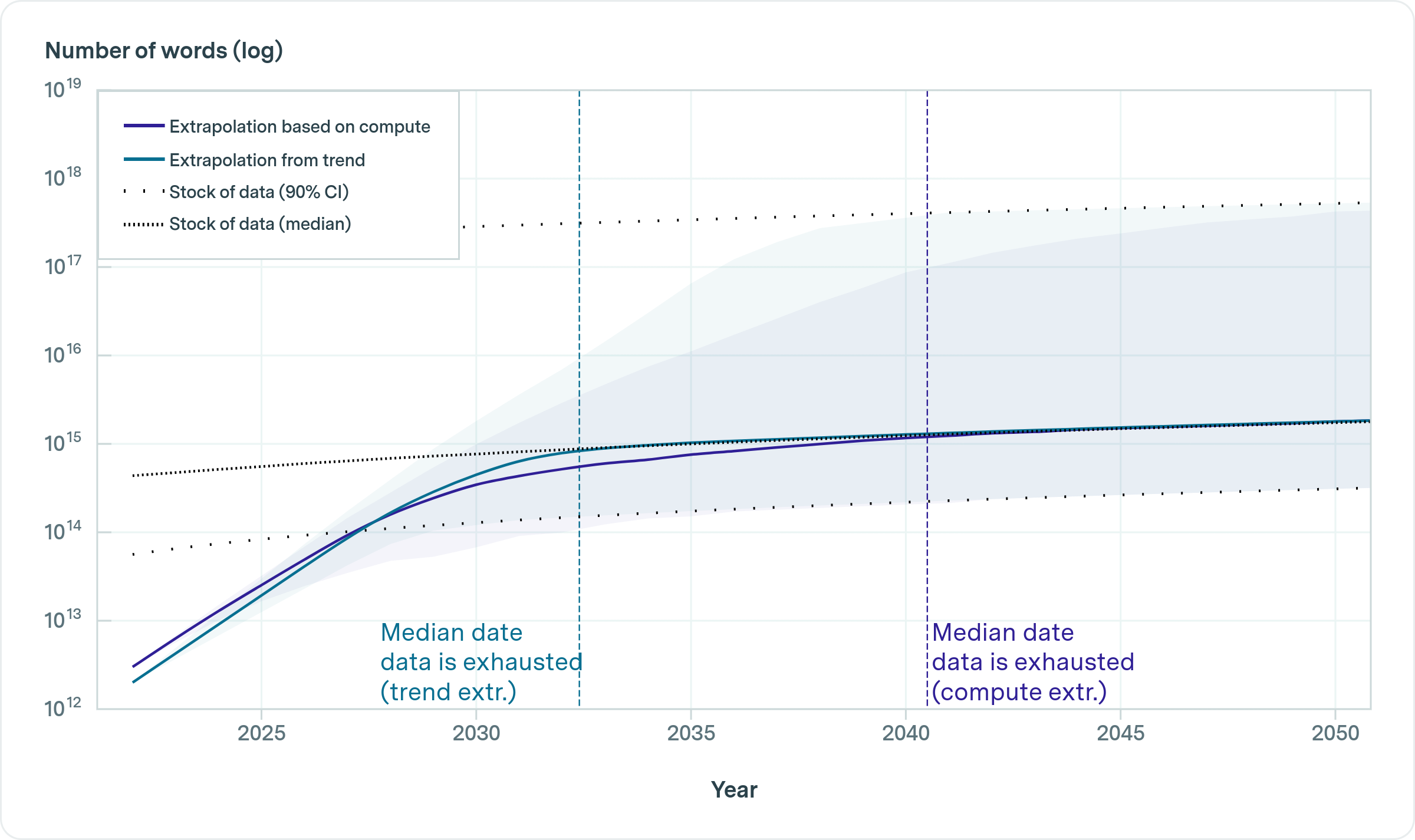
Is it possible to get a good enough LLM?
- more data is always best (even for SmolLM!)
- So why not training the largest LLM ever on all data and use it
everywhere?
- Usage cost
- Obsolescence
- Data bottleneck
- So far, not good enough for most cases!
- Better approach (in 2024):
- For each task (domain, language):
- gather “few” data
- adapt an LLM to the task
- For each task (domain, language):
- Because it is done multiple times, training costs become a
concern
- Parameter-efficient training (PEFT)
Which pretrained LLM to finetune?
- Option 1: large LLM
- benefit from best capacities
- fine for not-so-much specialized tasks
- high cost
- Option 2: “small” LLM
- fine for specialized task
- low cost
- hype: small agent LLMs, smolLM
- larger LLM \(\rightarrow\) less forgetting
Challenges
- Choose pretrained LLM
- Depends on the task and expected performance, robustness…
- Collect quality data
- Finetuning data must be high quality!
- Format data
- Format similar to final task
- FT on raw text may impact instruction following
- Track & prevent overfitting, limit forgetting
- Cost of finetuning may be high
Cost
- Cost of inference << cost of finetuning << cost of
pretraining
- quantization: we don’t know (yet) how to finetune well quantized LLMs; so finetuning requires 16 or 32 bits
- inference: no need to store all activations: compute each layer output from it’s input only
- inference: no need to store gradients, momentum
- Inference can be done with RAM = nb of parameters / 2
- Full finetuning requires RAM = \(11\times\) nb of parameters (according to
Eleuther-AI), \(12-20\times\) according
to UMass
- 1 parameter byte = +1B (gradient) + 2B (Adam optimizer state: 1st and 2nd gradient moments) (see next slide)
- Can be reduced to \(\simeq
5\times\):
- gradient checkpointing
- special optimizers (1bitAdam, Birder…)
- offloading…
- Adam equations:
- \(m^{(t)} = \beta_1 m^{(t-1)} + (1-\beta_1) \nabla L(\theta^{(t-1)})\)
- \(v^{(t)} = \beta_2 v^{(t-1)} + (1-\beta_2) \left(\nabla L(\theta^{(t-1)})\right)^2\)
- Bias correction:
- \(\hat m^{(t)} = \frac {m^{(t)}}{1-\beta_1}\)
- \(\hat v^{(t)} = \frac
{v^{(t)}}{1-\beta_2}\)
- \(\theta^{(t)} = \theta^{(t-1)} - \lambda\frac{\hat m^{(t)}} {\sqrt{\hat v^{(t)}} + \epsilon}\)
- PEFT greatly reduce RAM requirements:
- can keep LLM parameters frozen and quantized (qLoRA)
- store gradients + momentum only in 1% of parameters
- But:
- still need to backpropagate gradients through the whole LLM and save all activations
- with large data, PEFT underperforms full finetuning
VRAM usage
| Method | Bits | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full | 32 | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| Full | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| LoRA/GaLore/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | 48GB | 18GB | 48GB |
Training methods
| Method | data | notes |
|---|---|---|
| Pretraining | >10T | Full training |
| Cont. pretr. | \(\simeq 100\)b | update: PEFT? |
| Finetuning | 1k … 1b | Adapt to task: PEFT |
| Few-Shot learning | < 1k | Guide, help the LLM |
Wrap-up
- With enough compute, prefer full-finetuning
- HF transformer, deepspeed, llama-factory, axolotl…
- With 1 “small” GPU, go for PEFT
- qLoRA…
- Without any GPU: look for alternatives
- Prompting, RAG…
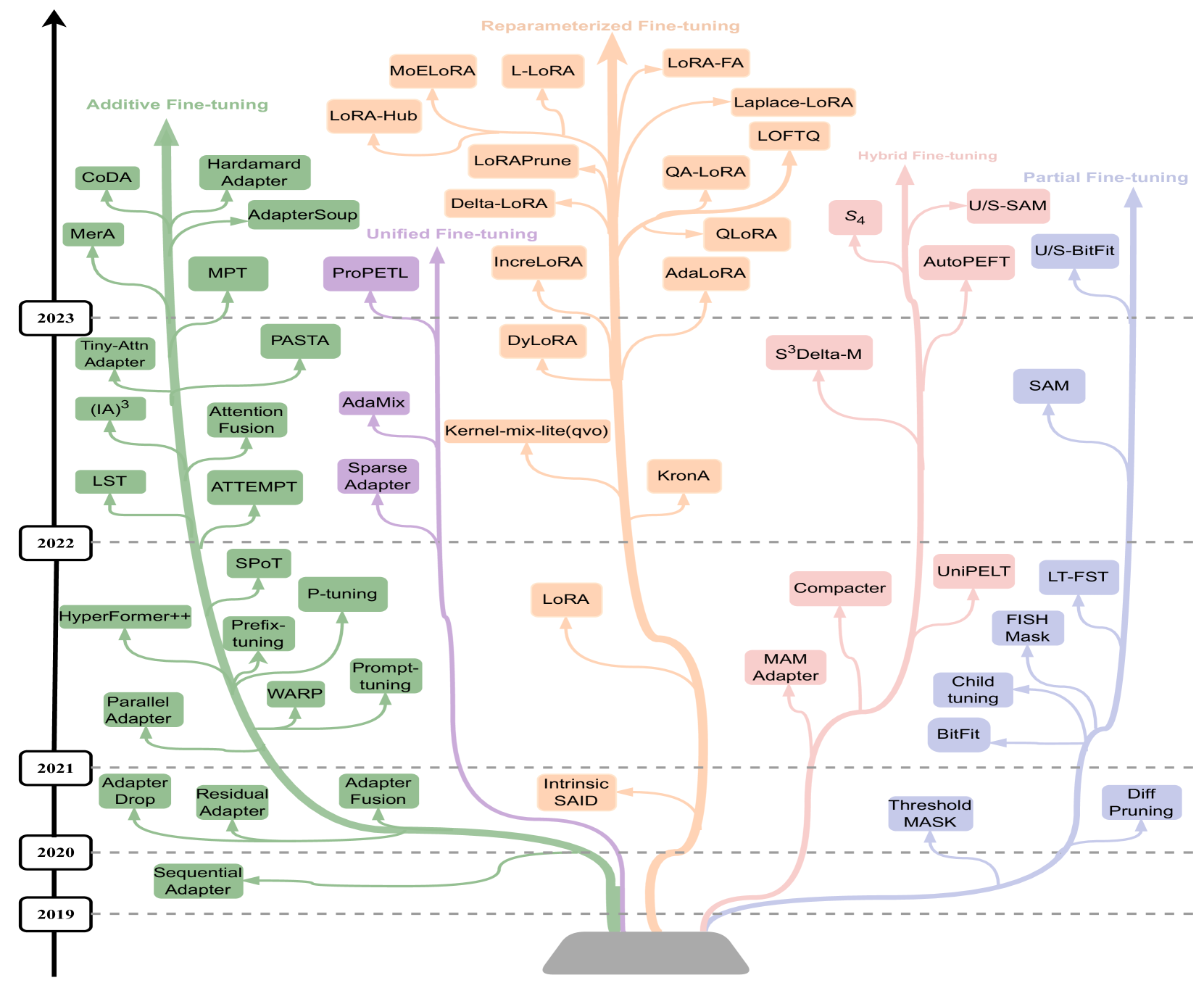
PEFT methods
- do not finetune all of the LLM parameters
- finetune/train a small number of (additional) parameters
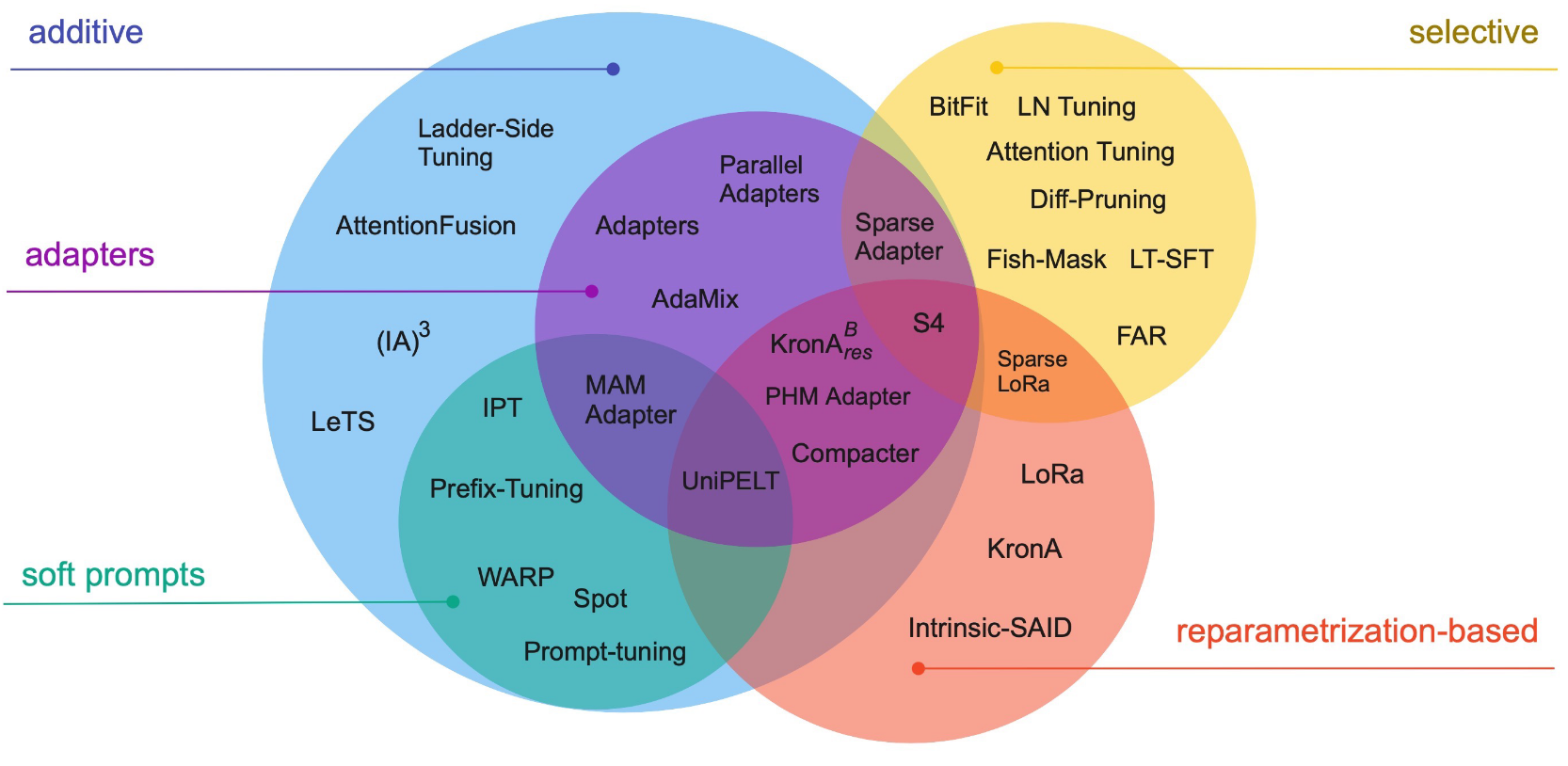
References
We’ll focus on a few
- Additive finetuning: add new parameters
- Adapter-based: sequential adapter
- soft-prompt: prefix tuning
- others: ladder-side-networks
- Partial finetuning: modify existing parameters
- Lottery-ticket sparse finetuning
- Reparameterization finetuning: “reparameterize” weight matrices
- qLoRA
- Hybrid finetuning: combine multiple PEFT
- manually: MAM, compacter, UniPELT
- auto: AutoPEFT, S3Delta-M
- Unified finetuning: unified framework
- AdaMix: MoE of LoRA or adapters
- SparseAdapter: prune adapters
- ProPETL: share masked sub-nets
Sequential adapters
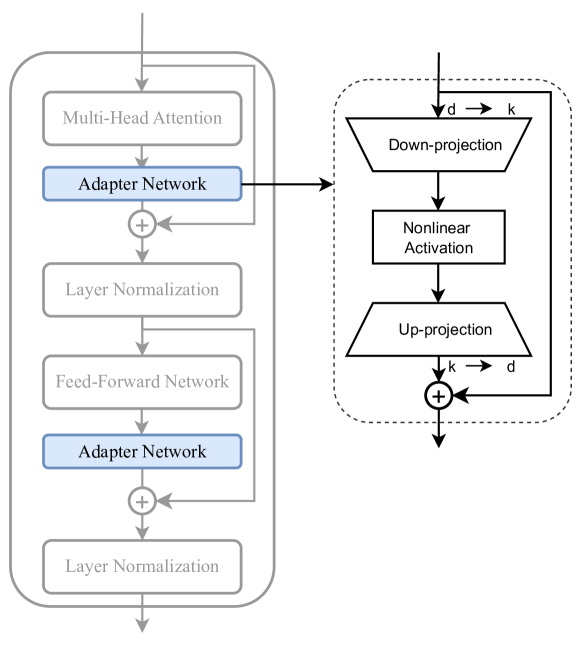
\[X=(RELU(X\cdot W_{down})) \cdot W_{up} + X\]
with
\[W_{down} \in R^{d\times k}~~~~W_{up} \in R^{k\times d}\]
- Advantages:
- Collection of available adapters: AdapterHub
- Drawbacks:
- Full backprop required
- Interesting extensions
- Parallel Adapter (parallel peft > sequential peft)
- CoDA: skip tokens in the main branch, not in the parallel adapter
- Tiny-Attention adapter: uses small attn as adapter
- Adapter Fusion: (see next slide)
- Train multiple adapters, then train fusion
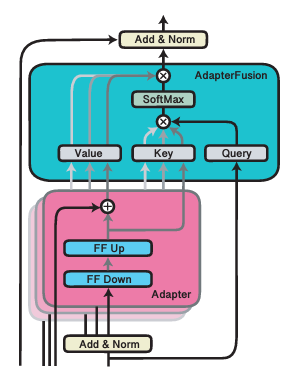
- Related to Adapter merging and LLM merging/LoRA extraction
Prefix tuning
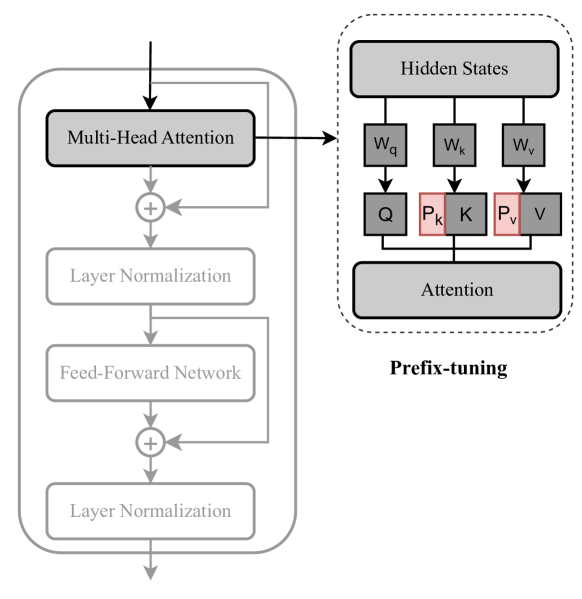
- Concat \(P_k,P_v \in R^{l\times d}\) before \(K,V\) \[head_i = Attn(xW_q^{(i)}, concat(P_k^{(i)},CW_k^{(i)}), concat(P_v^{(i)},CW_v^{(i)})\]
- with \(C=\)context, \(l=\)prefix length
- ICLR22 shows some form of equivalence:

- Advantages:
- More expressive than adapters, as it modifies every attention head
- One of the best PEFT method at very small parameters budget
- Drawbacks:
- Does not benefit from increasing nb of parameters
- Limited to attention head, while adapters may adapt FFN…
- … and adapting FFN is always better
Performance comparison

qLoRA = LoRA + quantized LLM
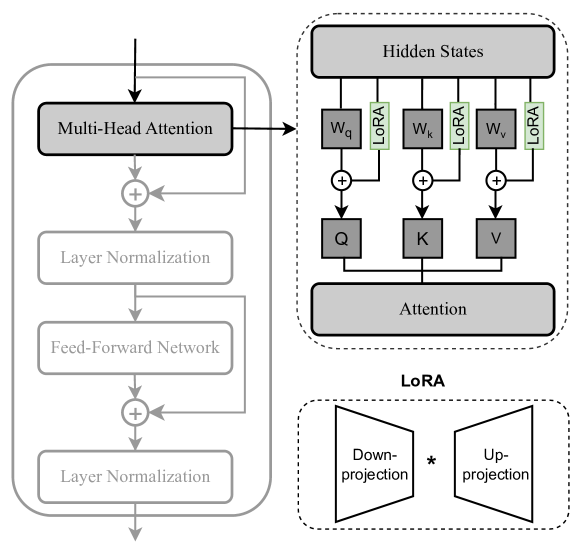
- Advantages:
- de facto standard: supported in nearly all LLM frameworks
- Many extensions, heavily developped, so good performances
- can be easily merged back into the LLM
- Drawbacks:
- Full backprop required
Adapter lib v3
- AdapterHubv3
integrates several family of adapters:
- Bottleneck = sequential
- Compacter = adapter with Kronecker prod to get up/down matrices
- Parallel
- Prefix, Mix-and-Match = combination Parallel + Prefix
- Uniformisation of PEFT functions: add_adapter(), train_adapter()
- heads after adapters: add_classification_head(), add_multiple_choice_head()
- In HF lib, you can pre-load multiple adapters and select one active:
model.add_adapter(lora_config, adapter_name="adapter_1")
model.add_adapter(lora_config, adapter_name="adapter_2")
model.set_adapter("adapter_1")Ladder-side-networks

- Advantages:
- Do not backprop in the main LLM!
- Only requires forward passes in the main LLM
- Drawbacks:
- LLM is just a “feature provider” to another model
- \(\simeq\) enhanced “classification/generation head on top”
- Forward pass can be done “layer by layer” with “pipeline
parallelism”
- load 1 layer \(L_i\) in RAM
- pass the whole corpus \(y_i=L_i(x_i)\)
- free memory and iterate with \(L_{i+1}\)
- LST: done only once for the whole training session!
- This approach received an outstanding award at ACL’2024:
Partial finetuning
- Add a linear layer on top and train it
- LLM = features provider
- You may further backprop gradients deeper in the top-N LLM layers
- … Or just FT the top-N layers without any additional parameters
- Simple, old-school, it usually works well
- Fill the continuum between full FT and classifier head FT:
- can FT top 10%, 50%, 80% params
- or FT bottom 10%, 50% params
- or FT intermediate layers / params
- or apply a sparse mask?
Lottery-ticket sparse finetuning
- Lottery Ticket
Hypothesis:
- Each neural network contains a sub-network (winning ticket) that, if trained again in isolation, matches the performance of the full model.
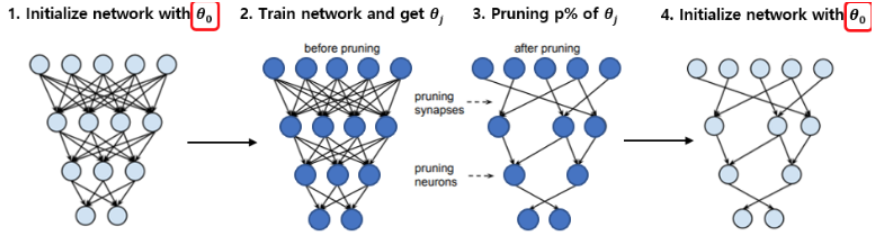
- Advantages:
- Can remove 90% parameters nearly without loss in performances (on image tasks)
- Drawbacks:
- Impossible to find the winning mask without training first the large model
can be applied to sparse FT
FT an LLM on specific task/lang
extract the mask = params that change most
rewind the LLM and re-FT with mask
sparse finetunes can be combined without overlapping!
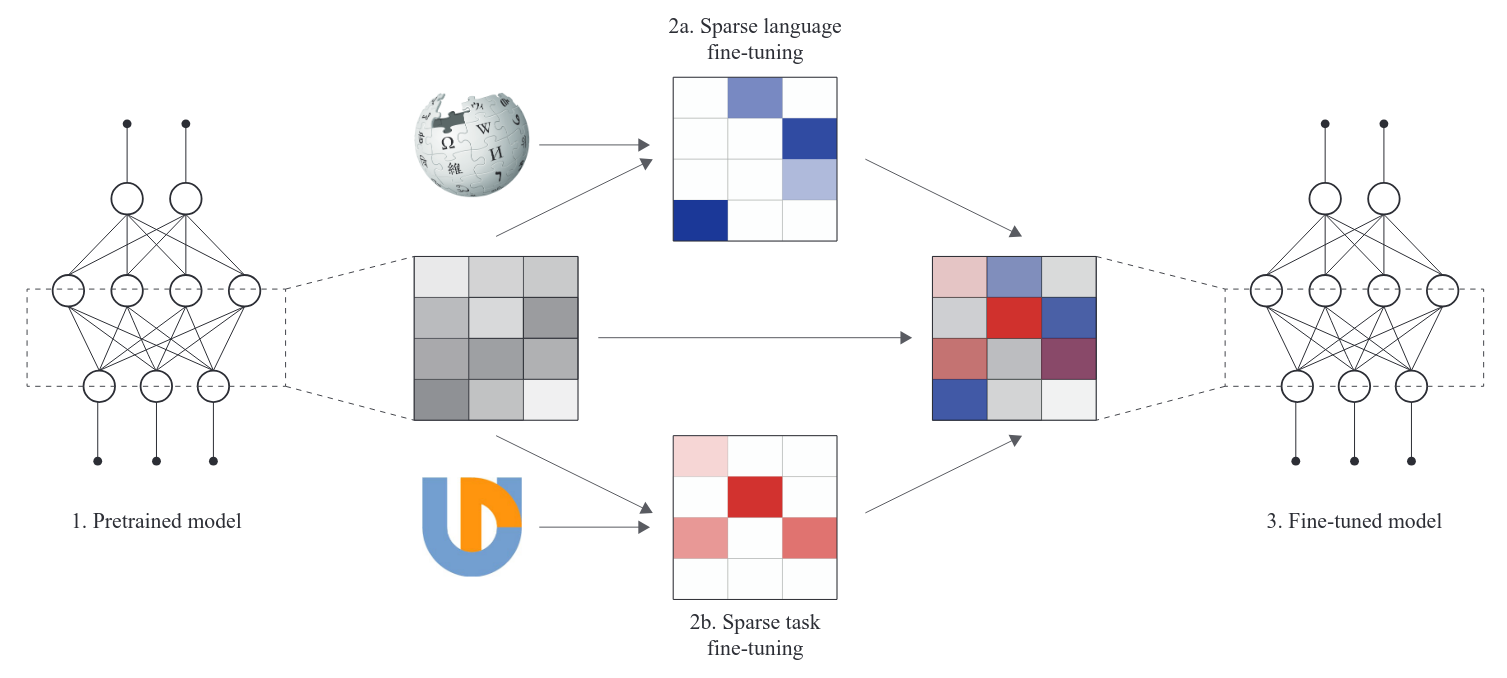
Wrap-up
- Various PEFT methods:
- Reduce model storage? RAM requirements?
- Require backprop through the LLM?
- Additional inference cost?

Finetuning (PEFT or full): advantages
- greatly improve performances on a target task, language, domain
- dig knowledge up to the surface, ready to use
- give the LLM desirable capacities: instruction-following, aligned with human preferences…
Finetuning (PEFT or full): drawbacks
- forgetting
- very slow to learn (BitDelta: Your Fine-Tune May Only Be Worth One Bit)
- increase hallucinations
Memorization, forgetting
Pretraining and FT use same basic algorithm (SGD), but the differences in data size lead to differences in training regimes.
- Difference in scale:
- Pretraining ingests trillions of tokens
- Finetuning uses up to millions of tokens
- This leads to differences in regimes / behaviour:
- Pretraining learns new information
- Finetuning exhumes information it already knows
Why such a difference in regimes?
- Because of the way SGD works:
- When it sees one piece of information, it partially stores it in a few parameters
- But not enough to retrieve it later!
- When it sees it again, it accumulates it in its weights \(\rightarrow\) Memorization
- If it never sees it again, it will be overriden \(\rightarrow\) Forgetting
- How many times shall a piece of information be seen?
- cf. Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
- Universal rule:
- an LLM can store up to 2 bit/param of information
- it requires 1000x exposure to store 1 piece of knowledge
- Finetuning hardly learns new knowledge:
- small data \(\rightarrow\) not enough exposure
- Why not repeat 1000x the finetuning dataset?
- Because previous knowledge will be forgotten!

Why doesn’t pretraining forget?
- It does!
- But by shuffling the dataset, each information is repeated all along training
- So how to add new knowledge?
- continued pretraining: replay + new data
- RAG, external knowledge databases
- LLM + tools (e.g., web search)
- knowledge editing (see ROME, MEND…)
Take home message
- PEFT is used to adapt to a domain, not to add knowledge
- RAG/LLM agents are used to add knowledge (but not at scale)
- Choose PEFT when constrained by available hardware:
- single GPU with VRAM<40GB, LLM larger than 1b –> PEFT!
What can be done without any GPU?
- Running LLM is OK: see llama.cpp, llamafile, ollama…
- No finetuning without GPU!
- llama.cpp: qLoRA supported, but not mature
- too slow to be usable
- With enough compute, prefer full-finetuning
- HF transformer, deepspeed, llama-factory, axolotl
- With 1 “small” GPU, go for PEFT (qLoRA)
- Without any GPU: look for alternatives (ICL, RAG…)
TP PEFT
- Language adaptation for causal reasoning
- Additional PEFT exercices by Tatiana Anikina and Simon Ostermann
$ and carbon costs
- Pre-training costs:
- Llama2-70b = $5M
- $1M for training a 13b-LLM on 1.4T tokens
- Finetuning costs: $10 for finetuning 6b-LLM
- (from anyscale.com)
- How to reduce these costs?
- Break the scaling laws? no way so far…
- Algo improvement: GPT3 costed $3M in 2020
- “only” $150k in 2023
best practices
- tools to use
- common configurations, hyper-parameters
Context Length
InfLLM
- Main issues with long context:
- train/test mismatch, as LLMs have mostly been trained on small context size
- long context contains a lot of “noise” (not relevant text)
- Proposes to combine:
- sliding attention window = use only local tokens in context
- external memory
InfLLM algo
1- chunk the long seq, encode each chunk independently 2- for each token to generate: - the long-context input is composed of (long) past KV-cache + current tokens - the KV-cache is composed of: - (small) initial sequence is kept - (long) evicted sequence - evicted KV are stored in external memory - at test time, a lookup f() selects KV from external memory to add to the small context
- the past KV are chunked into blocks, look-up is done at the block level.
- each block is represented by r “best representative tokens”
- representative score of token m in a block = avg q(m+j) k(m)
- lookup is based on another (similar) relevance score btw q(X) and the representative tokens of a block.
- all input tokens beyond X have the same positional encoding.
Continual Learning
- Challenges:
- Catastrophic forgetting
- Evaluation: cf. realtime-QA
- Data drift towards LLM-generated texts
- How to restart training?
Catastrophic forgetting
There’s some hope though…
- May be it’s just misaligned output embeds
- Growing networks are promising to mitigate forgetting GradMax, ICLR’22
- Growing models have good geometrical properties in the parameter space
Continual training
- Sheared Llama (Princeton, 2023)
- structured pruning + cont. training w/ batch weighting
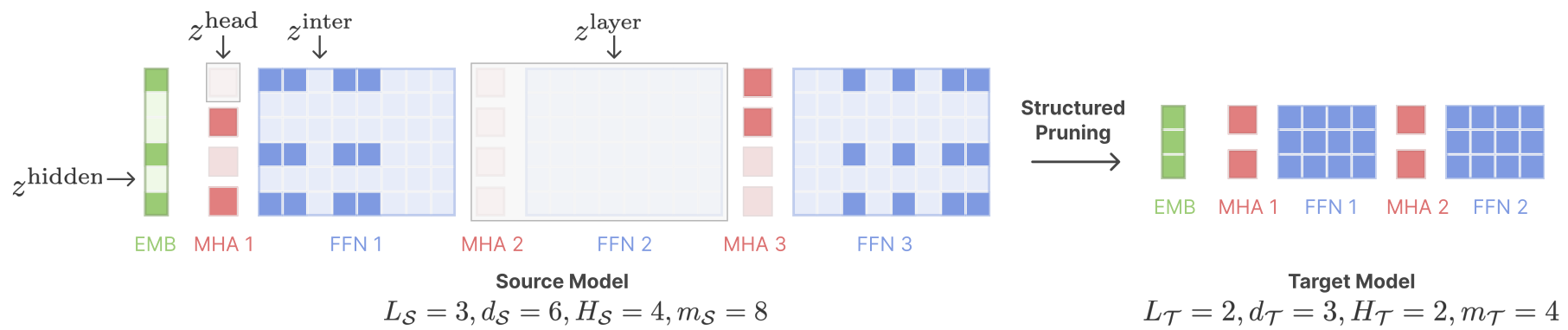
- Sheared llama: resurgence of a scaling law w/ cont. training
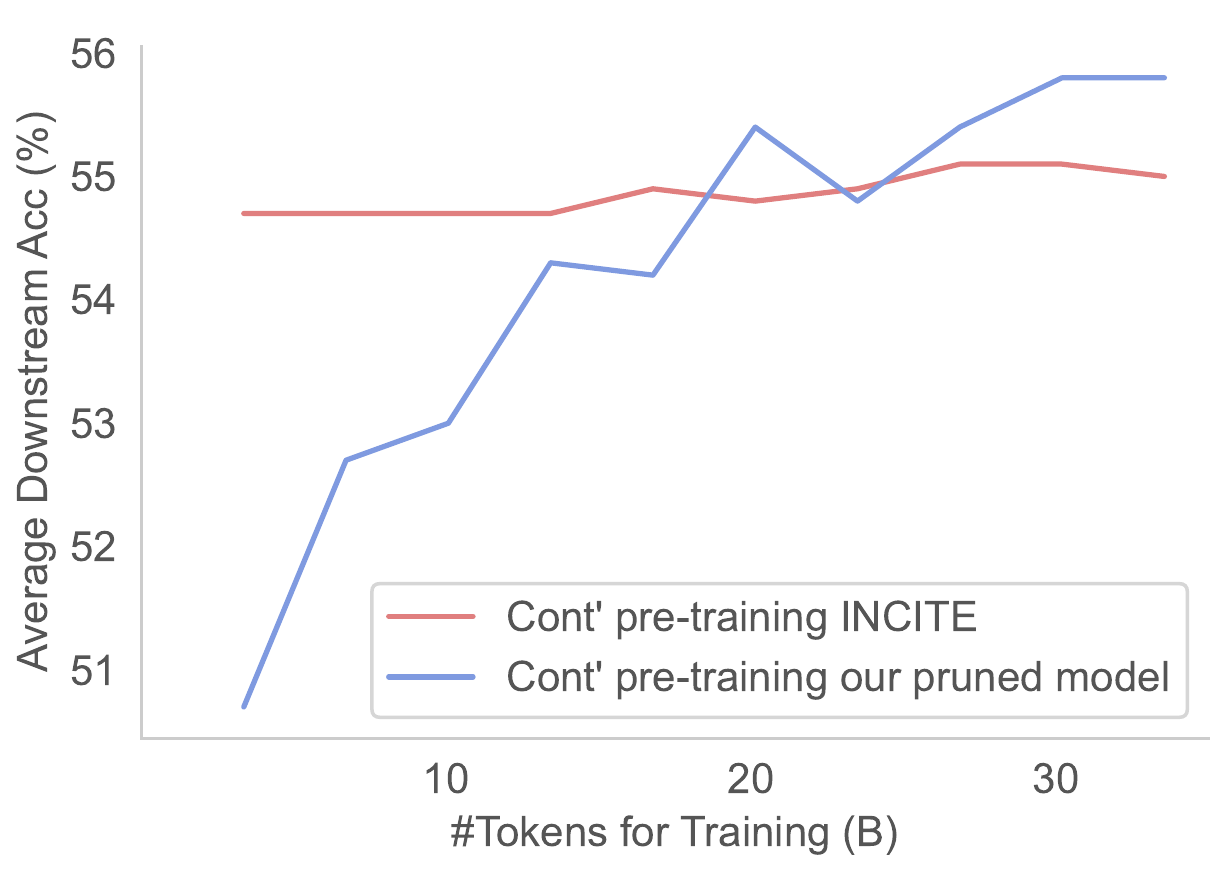
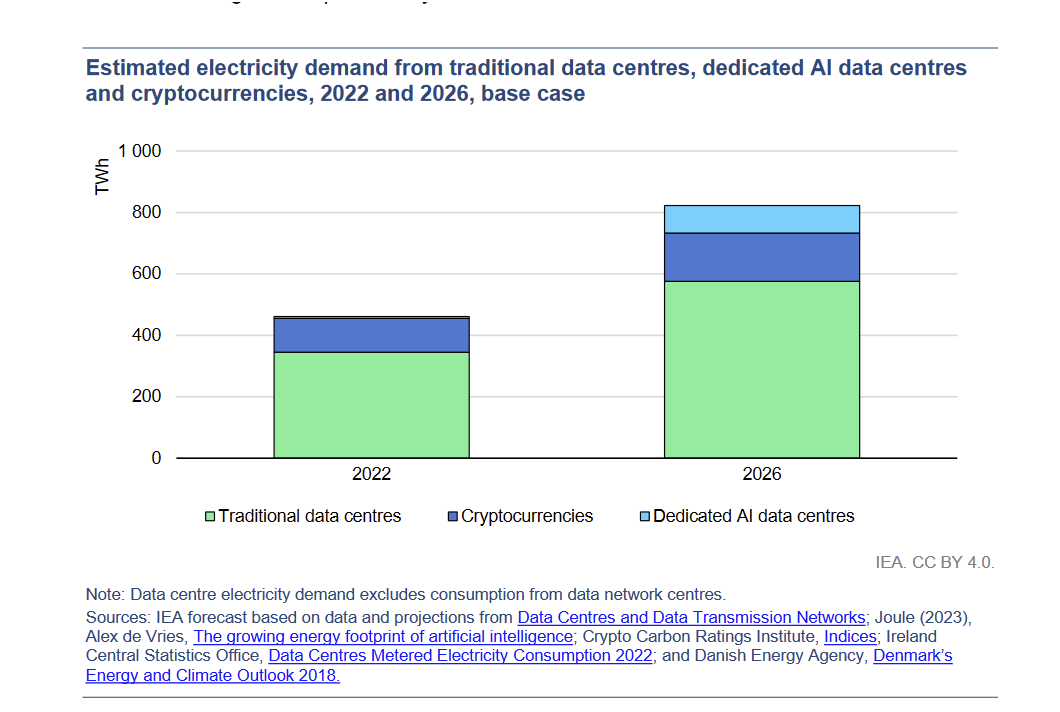
- Carbon footprint:
- many researches on reducing costs
- also on tackling climate change with AI
- BUT rebound effect: only way is through societal changes
- Relativize AI-blaming discourses, they may focus on the tree that hides the forest:
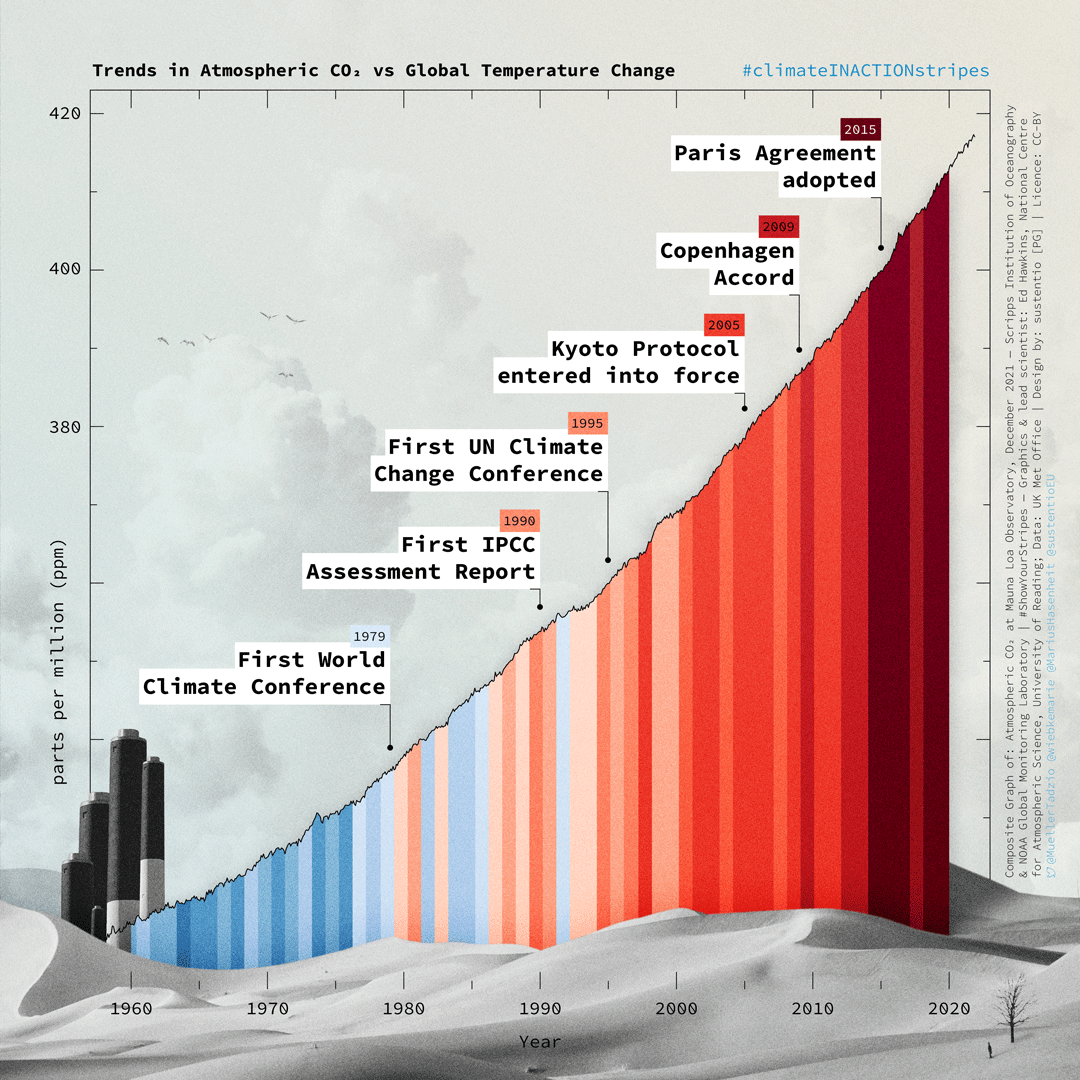
- Where is the impact of AI in this curve?
- Compare realistic carbon reduction measures:
| Cost (T.CO2) | |
|---|---|
| 560 persons virtual conf | 10 |
| 560 persons F2F conf | 274 |
| 18000 persons virtual conf | 176 |
| 18000 persons F2F conf | 10348 |
| emissions 1 car/year source | 2.2 |
| emissions cars in France/year | 65M |
| training Bloom | 25 |
- Privacy:
- models remember facts (cf. Carlini)
- user modeling
- Capture & remember long-term context
- Limits of “pure text”: multimodal, grounded
Carbon footprint
- Costs of LLMs:
- training on GPU clusters
- usage requires powerful machines
- Many ways to reduce cost:
- algorithms improvement
- developing “heritage” (soft + hard)
- hardware improvement
- using LLM to reduce impact of other activies
- e.g., less bugs, shorten dev cycles, reduce waste…
- …
Algorithms improvement
- Quantization
- reducing nb of bits per parameter
- standard: 32 (cpu), 16 & bf16 (gpu)
- quantized: 8, prospect: 4, 2, 1
- cf. bitsandbytes, ZeroQuant, SmoothQuant, LLM.int()…
- GLM-130B requires VRAM: 550GB (32b), 300GB(16b), 150GB (8b)
- Pruning
- Principle: remove some neurons and/or connections
- Example:
- remove all connections which weight is close to 0
- then finetune on target task, and iterate
- Hard to do on large LM
- Many pruning methods:
- data-free criteria:
- magnitude pruning
- data-driven criteria:
- movement pruning
- post-training pruning
- pruning with retraining
- structured pruning
- unstructured pruning (sparsity)
- …
- data-free criteria:
- distillation
- Principle: train a small student model to reproduce the outputs of a large teacher model
- Problems:
- Limited by the (usually) small corpus used: does it generalize well?
- Otherwise, very costly: why not training from scratch?
- Parameter-efficient finetuning:
- Principle: fine-tune only a small number of parameters
- Adapters
- Prompt tuning
- Train faster, in less epochs, with less FLOPs
- Exploit best practices:
- Layer Normalization stabilizes training
- Exploit scaling law:
- use accurate sizes, stop before convergence
- Train larger models then compress
- Progressive training
Loss: UL2
MAGMAX: Leveraging Model Merging for Seamless Continual Learning
Forgetting by finetuning does not work: LLMs don’t forget internally: https://arxiv.org/abs/2409.02228
Heritage & low-end computers
- offloading
- see deepspeed Zero
- see accelerate
- Collaborative training:
- TogetherComputer: GPT-JT
- PETALS & Hivemind
- Mixture of experts
- Challenge: privacy
- Models remember facts (cf. Carlini)
- Hard to solve ?
- Differential Privacy: impact usefulness
- Post-edit model
- find private info + delete it from model
- Pre-clean data
- Challenge: frugal AI
- Vision, Signal processing with small models
- Pruning, distillation, SAM, firefly NN…
- Impossible? in NLP
- Needs to store huge amount of information
- Federated model ?
- Continual learning ?
- Sub-model editing ? (“FROTE”)
- Capturing longer contexts
- model structured state spaces (Annotated S4 on github)
- Limit of text accessibility ?
- Grounding language: vision, haptic, games…
- Annotate other tasks with language:
- industrial data, maths proof…
Analyzing LLM Training
- Tools to analyze training curves:
- Tensorboard
- Weights And Biases (wandb)
- print() then gnuplot
Tensorboard
- Assuming log files have been generated with the tensorboard format,
the tool does:
- Extract the training curves from log files
- Open a web server to visualize them
- Most training libraries create by default tensorboard-compliant
logs:
- pytorch lightning
- ms-swift
- …
Logging for tensorboard
- The following code shows how to directly create a log for tensorboard
- copy-paste it and observe the curve
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import random
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
print(tokenizer.special_tokens_map)
class Traindata(torch.utils.data.Dataset):
def __init__(self):
super().__init__()
d = ['a','b']
self.y = [0,1]
self.x = tokenizer.batch_encode_plus(d,return_tensors='pt')['input_ids'].split(1)
print("tokenization done",len(self.x))
def __len__(self):
return len(self.x)
def __getitem__(self,i):
return self.x[i], self.y[i]
model = AutoModelForSequenceClassification.from_pretrained('distilbert-base-uncased')
for n,p in model.named_parameters():
if not '.layer.5' in n: p.requires_grad=False
print(n,p.shape)
opt = torch.optim.SGD(model.parameters(), lr = 1e+5)
traindata = Traindata()
trainloader = torch.utils.data.DataLoader(traindata, batch_size=1, shuffle=True)
for ep in range(100):
totl = 0.
for x,y in trainloader:
opt.zero_grad()
x = x.view(1,-1)
yy = torch.LongTensor(y)
pred = model(x)
loss = torch.nn.functional.cross_entropy(pred['logits'],yy)
totl += loss.item()
loss.backward()
opt.step()
print(ep,totl)
writer.add_scalar("trainloss", totl, ep)
writer.flush()
exit()
# to view the curves:
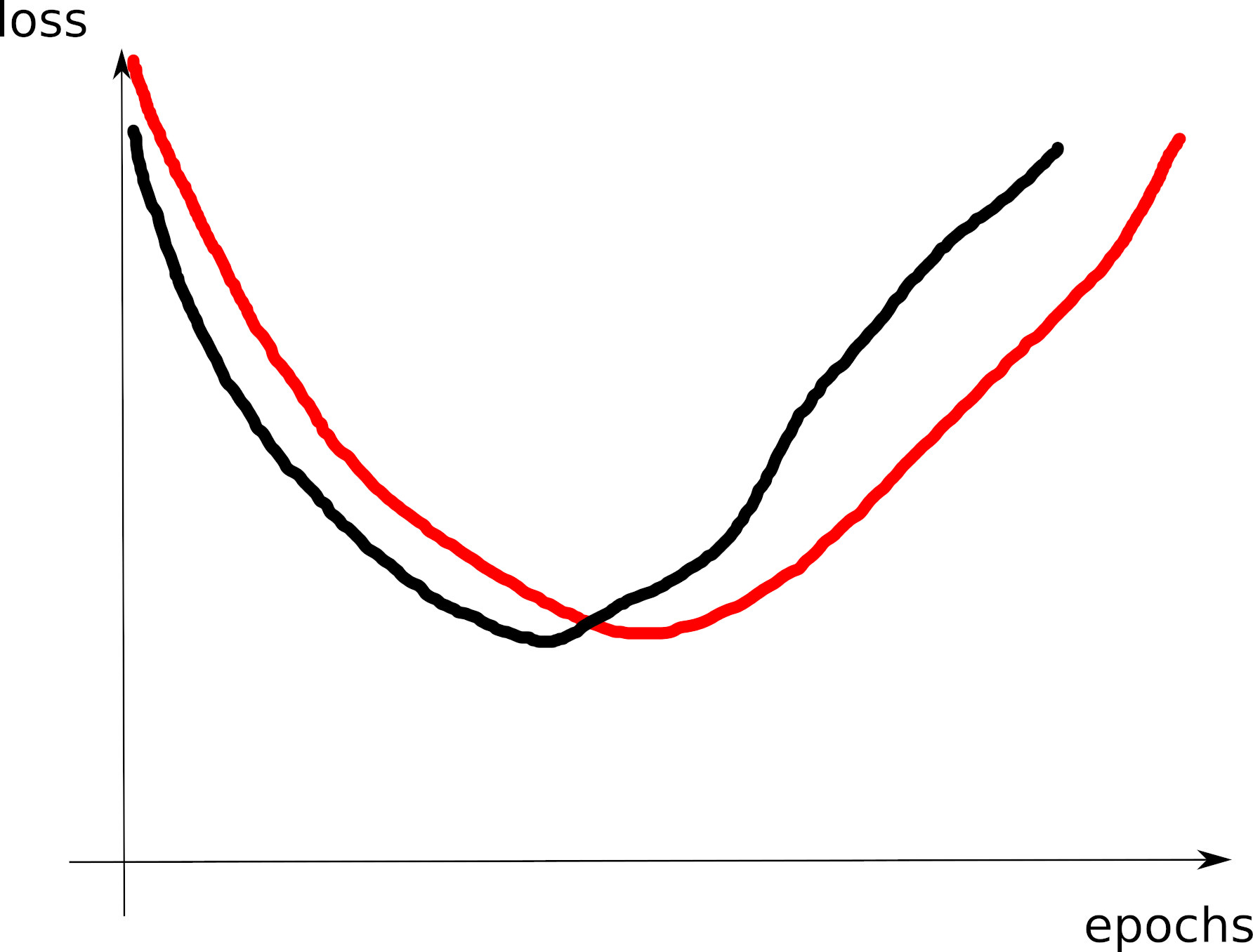
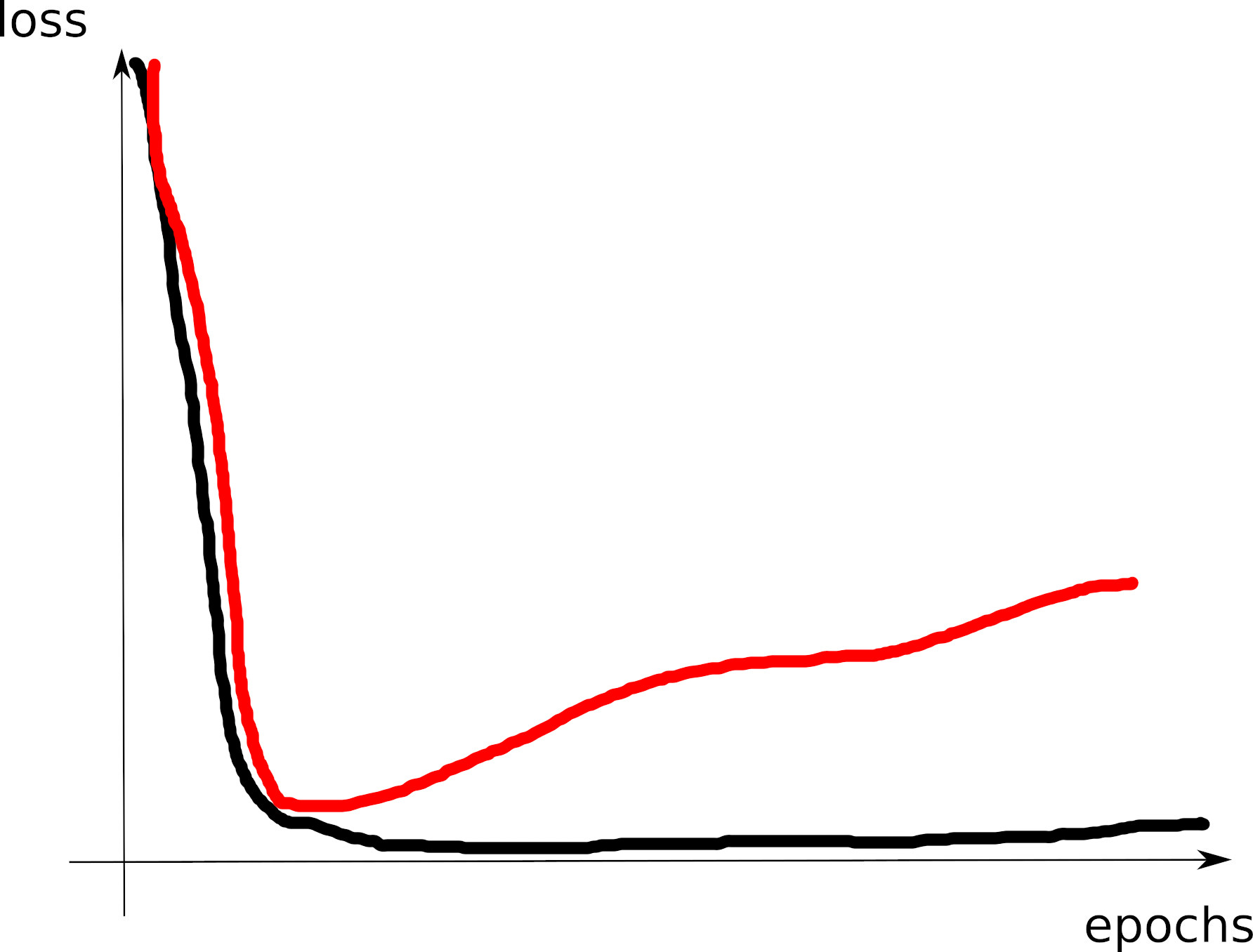
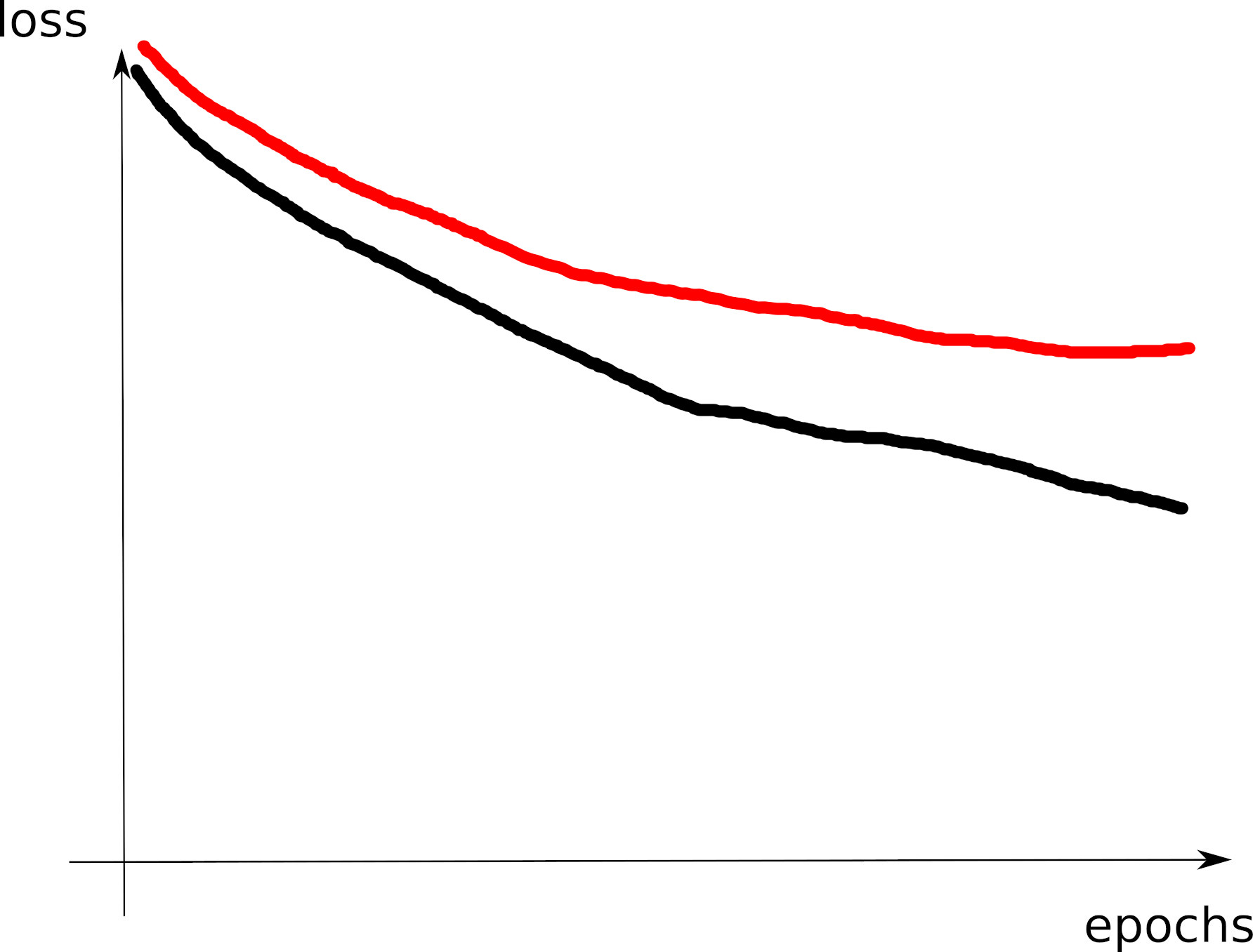
# tensorboard --logdir=runs/- Look at the training loss curve: what’s going on?
Curve 1
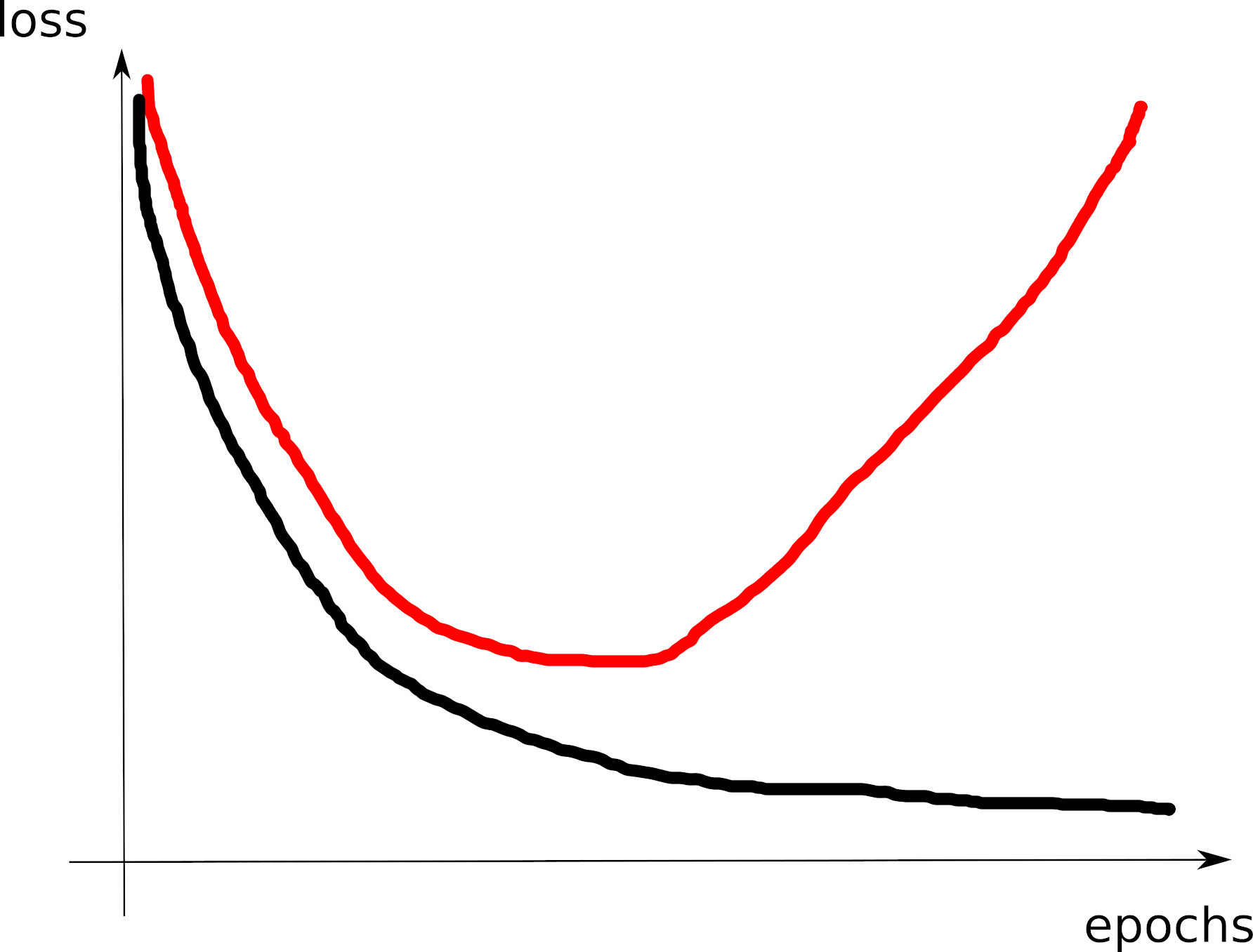
Curve 2
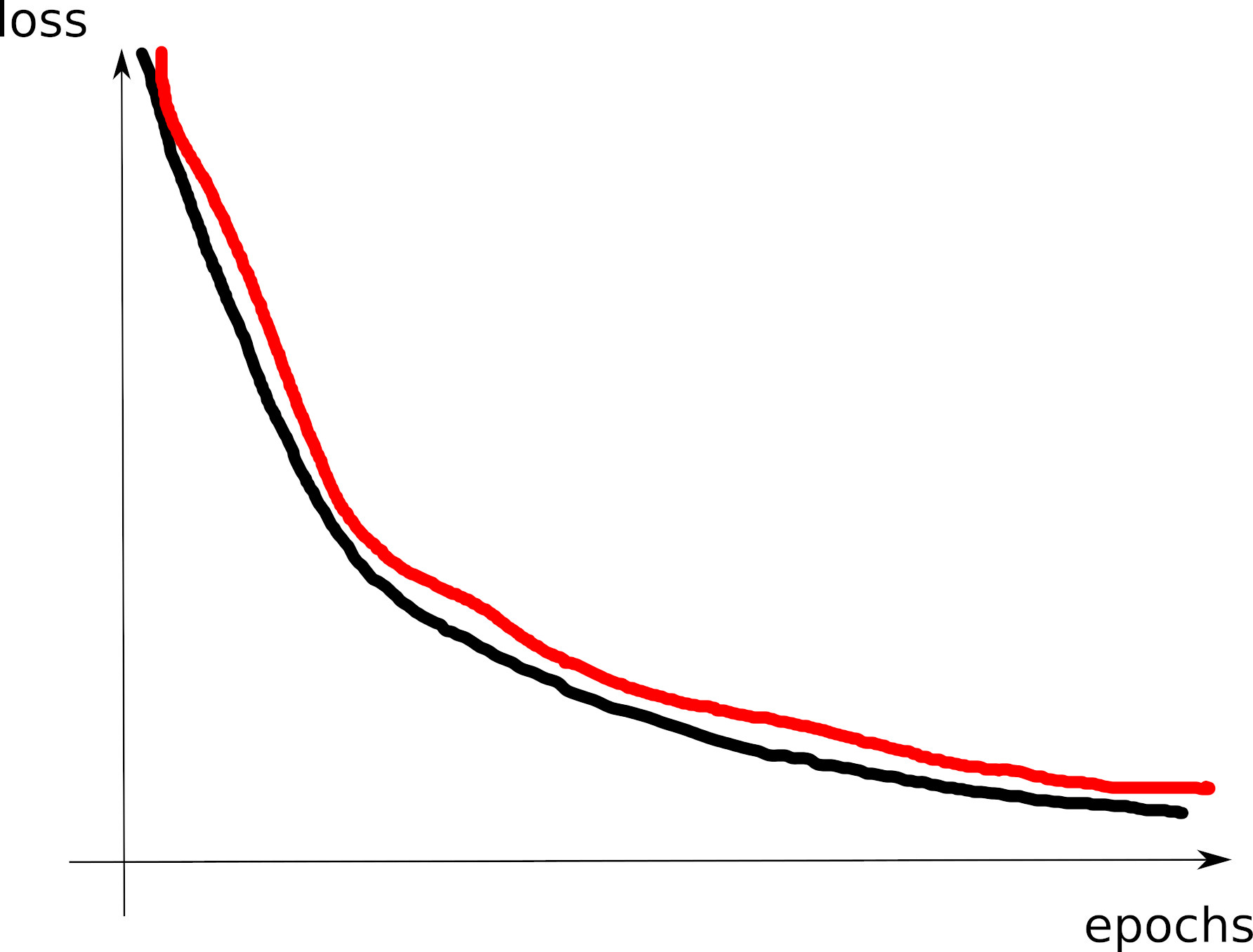
Curve 3
Curve 4
Curve 5
Curve 6
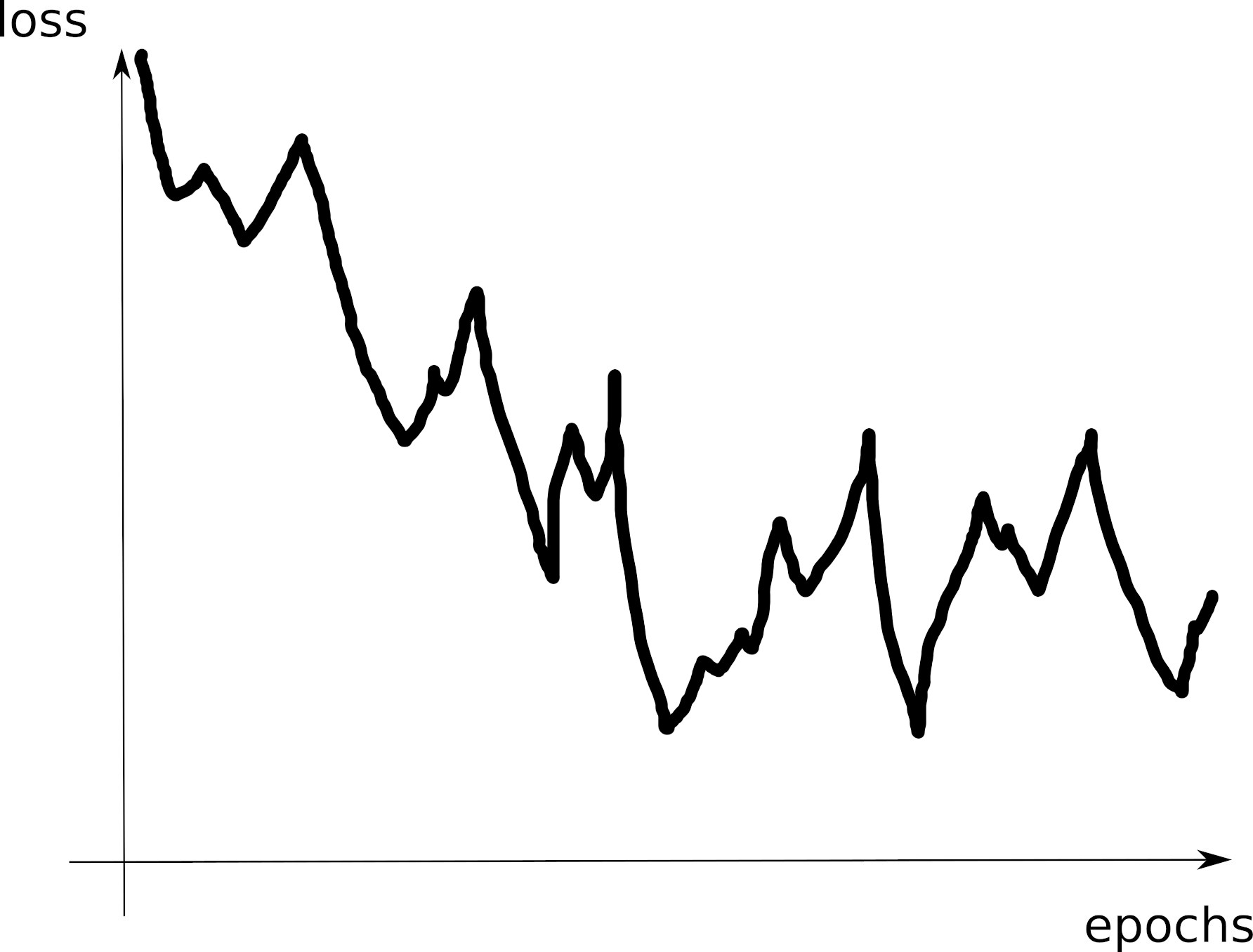
Curve 7
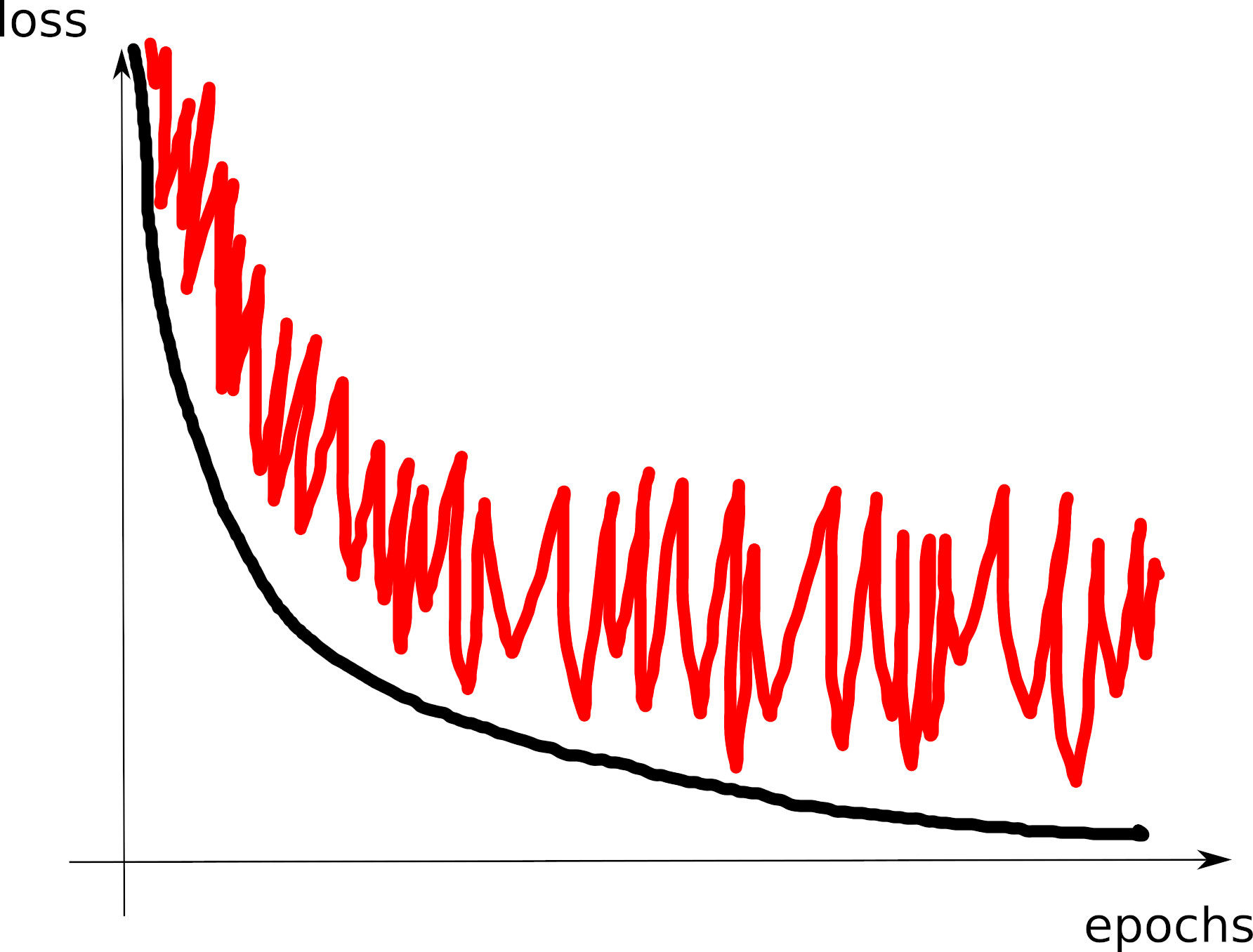
Curve 8
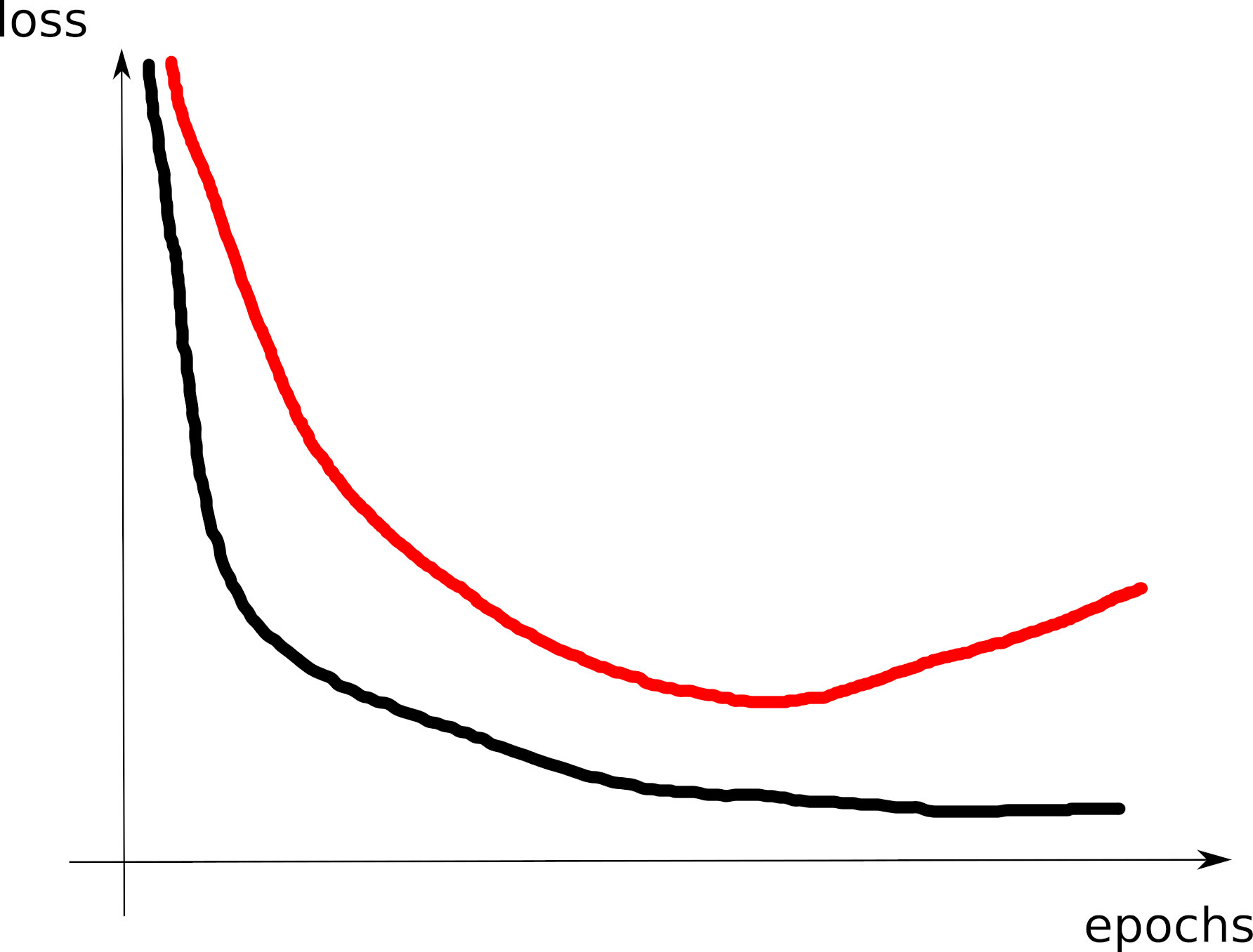
Visible effects
- Learning rate too large
- Learning rate too small
- Training loss not averaged enough
- Training and val losses not comparable
- Overfitting
- Underfitting
- Training too short / Convergence too slow
- Grokking
- \(x\perp\!\!\!\!\perp y\) (bug? bad data? ill-posed problem?)
- no shuffling of training set
- mismatch of train and val distributions
- LLM pretraining curves
- spikes in gradients (LR or optimization issues)
- too much variability across runs (saddle? init?)
- not enough variability across runs (seed issue?)
- saddle point ? (multiple runs plateau at various levels)
- pretraining instabilities: tune weights initialization
- not enough regularization
- too much regularization
- exploding / vanishing gradients
- ill-conditioning (Hessian issue -> sharp valleys)
What can go wrong
- Solutions against saddle points:
- try other optimizers (Adam, Adagrad, RMSProp… family)
- LR scheduler
- Batch norm: smooths loss landscape
- Noise injection
- Tracking weights change:
- Large weights change is normal for rare words with Adam
- Track variance of gradient mini-batch:
- large spike at 0, small elsewhere: vanishing gradient
- bimodal, too flat, not centered distribution: exploding gradient
- solved with batch norm, gradient clipping
- correlation traps
- Exploding gradients: check gradient norm
- sudden jump in the training loss: may be due to a “cliff” in loss landscape, with very large gradients resulting in large jumps (see paper )
- compare the gradient norm with parameter norm:
- grad norm is proportional to parm norm
- so it’s OK that grad norm increases when parm norm increases as well
- If the activations in one layer become close to 0, very slow
training in the deepest layers
- see Glorot paper
- momentum, ill-conditioning: see blog
- momentum speeds-up SGD quadratically
- ill-conditioned Hessian = curvature much larger in one dim than in another => sharp valley
- SGD will “bounce” between walls of this sharp valley
Loss landscape
- In the loss landscape:
- minima are connected together through “valleys”
- all local minima are also global minima
- See Kawaguchi
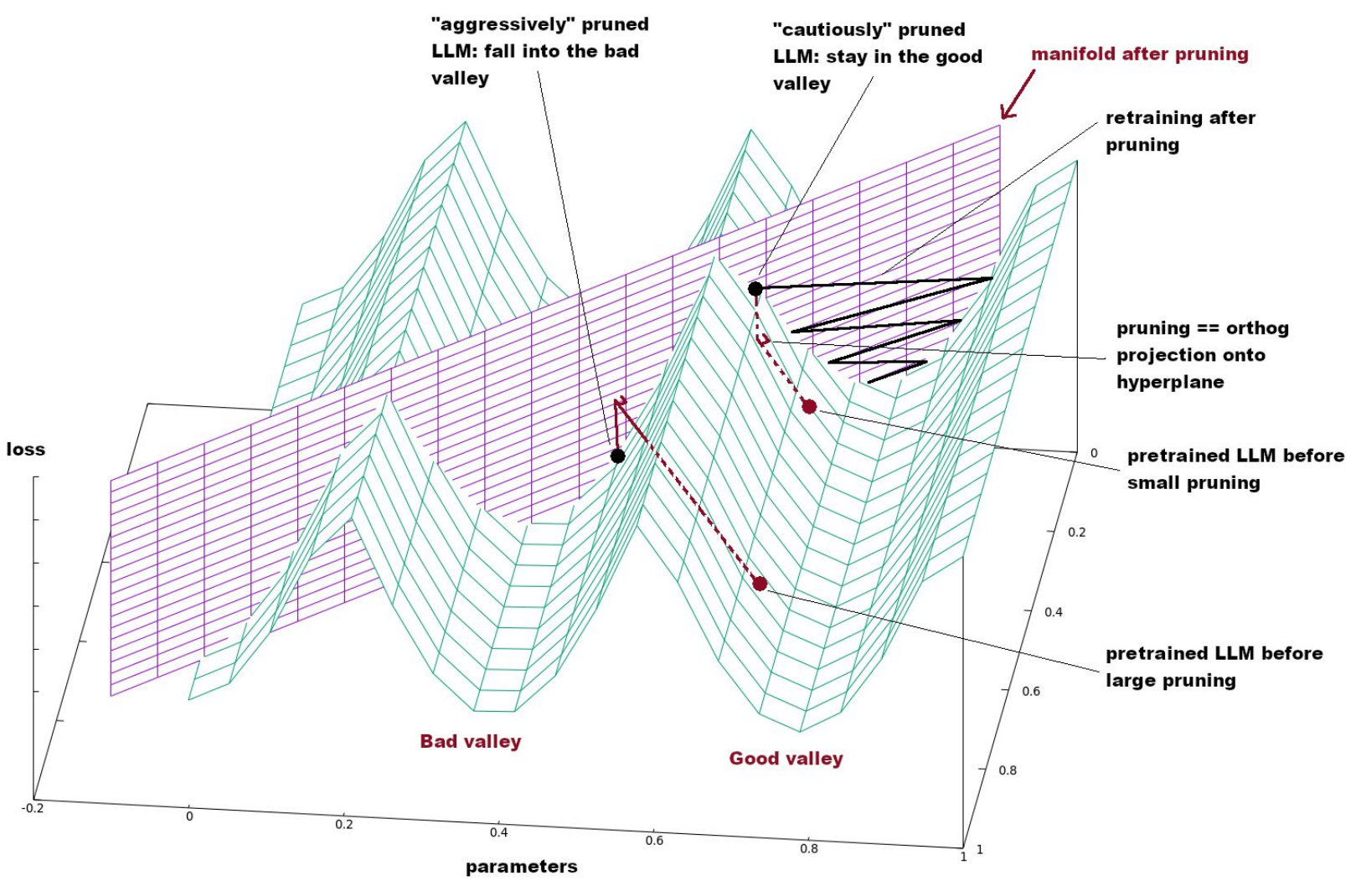
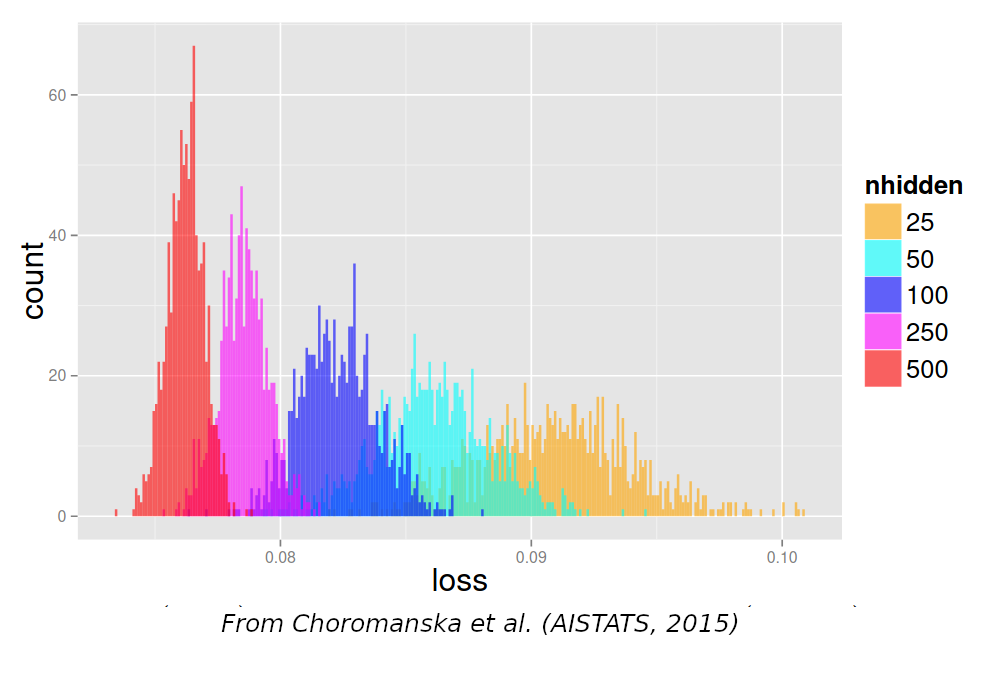
- Understanding the loss landscape is useful for:
- Optimizers: Adam, saddle points…
- Model merging: linearly connected models
- SGD convergence: edges, flatness
- Pruning, compression:
- Why iterative pruning?
- Why is calibration data required?
- …
Additional references
Great pedagogical point of view about LLM by Sasha Rush: video
calcul des Flops: https://kipp.ly/transformer-inference-arithmetic/
- Images from
- https://e2eml.school/transformers.html
- paper “Attention is all you need”
- Best blog ever about transformers
- Great talk on maths theory about transformers
- Great talk about ZSL