Les LLM au défi; passer à l’échelle tout en réduisant leur taille
Christophe Cerisara
CNRS, LORIA, Synalp team
IA: tout est question d’échelle
- l’IA repose sur des lois fondamentales: les scaling laws
- Plus de données \(\rightarrow\) meilleures performances
- Modèles plus gros \(\rightarrow\) meilleures performances
- Plus de GPU \(\rightarrow\) meilleures performances
- Autres métriques de performance: coût, carbone, utilisabilité, transparence, privacy, souveraineté…
- \(\rightarrow\) smolLM, Lucie 7b…
![]()
Défi: améliorer ce compromis
- Réduire les coûts: optimisation, quantization
- Comprimer les LLMs de sorte que leurs performances soient meilleures
Pour la suite:
- Rappel: scaling laws
- Nouvelle méthode: compression efficace
- The more data you train on
- the more the LLM knows about
- the better the LLM generalizes
- scaling law = power law = \(y(x) = ax^{-\gamma} +b\)
- \(y(x) =\) test loss
- \(\gamma\) = slope
\(L=\) pretraining loss
![]()
Le transformer est difficile à battre !
![]()
- Mais le scaling présente 2 problèmes principaux:
- Coûts en calcul:
- Gérables: coûts training/10 tous les ans; coûts de déploiement -90% (cf. FrugalGPT)
- utilisabilité: GPUs + LLMaaS indispensable
- Objectif: déploiement on device !
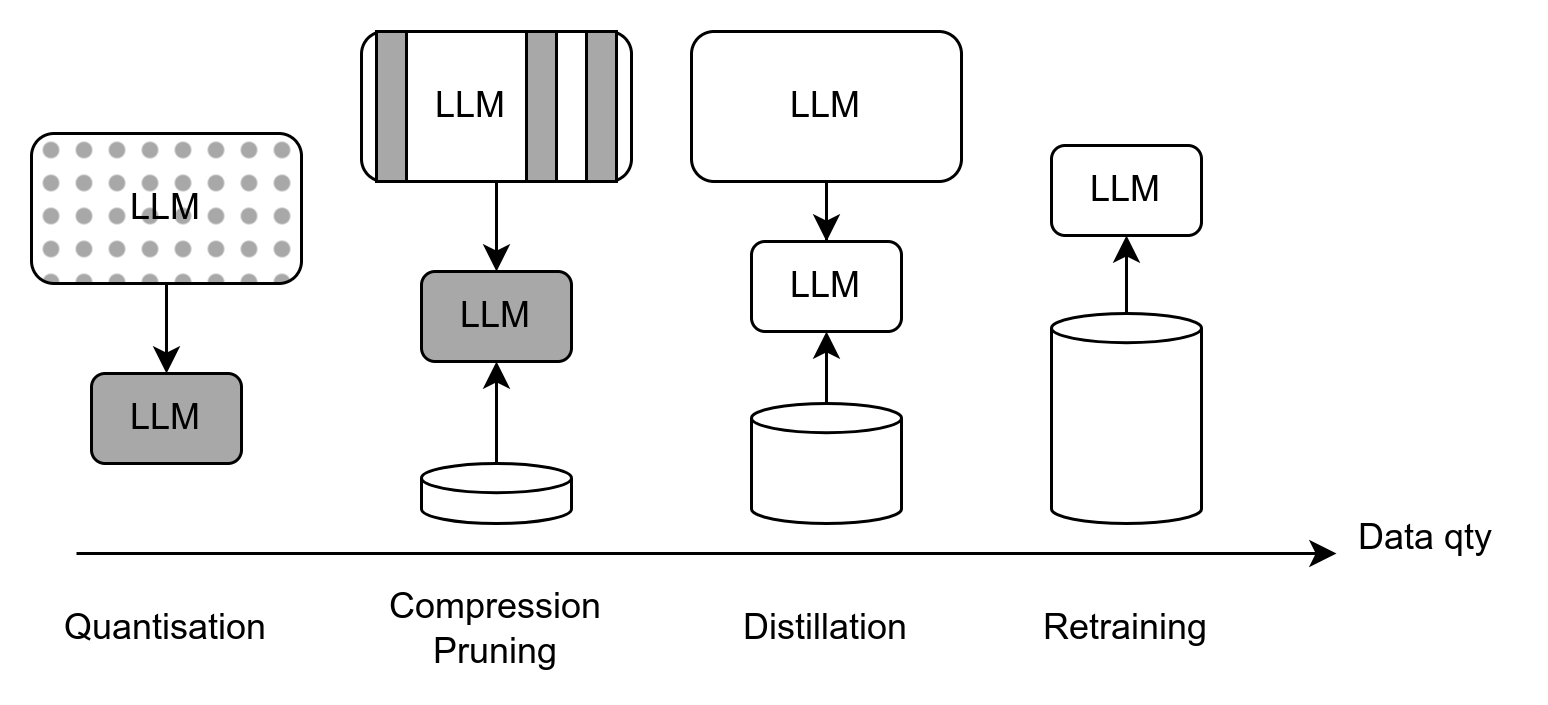
Construction de “petits” LLM
- Quantisation:
- conserve toute l’information (non sélective)
- limitée à \(\sim 4\) bits
- impossible d’entraîner
- Atteint des limites théoriques
![]()
- Distillation: très efficace mais coûteuse
- Compression: requiert qqs calibration data
![]()
LLM Pruning: motivations
- Toute la connaissance d’un LLM n’est pas toujours utile
- Ils n’utilisent peut-être pas tous leurs paramètres (parameter-efficiency)
- Pruning: supprimer les paramètres “inutilisés”
- Une mesure de l’information: rang des matrices
Low-rank matrices
- Les matrices des LLMs sont presque pleines…
![]()
- … Mais les activations \(Y=WX\) ne le sont pas
![]()
- Principe: trouver une matrice de faible rang qui minimise l’erreur de reconstruction: \[\widehat{\Delta W} = \underset{{\Delta W}}{\mathrm{argmin}} \;\; \frac{1}{N}\sum\limits_{x \in \mathcal{D}}\|Wx - {\Delta Wx}\|_{F}\]
- Solution (seulement pour des matrices): \[\Sigma = \underset{y \in \mathcal{Y}}{\mathbb{E}}\left[yy^T\right] - \mathbb{E}[y]\mathbb{E}[y]^T\]
- LORD (Kaushal,2023)
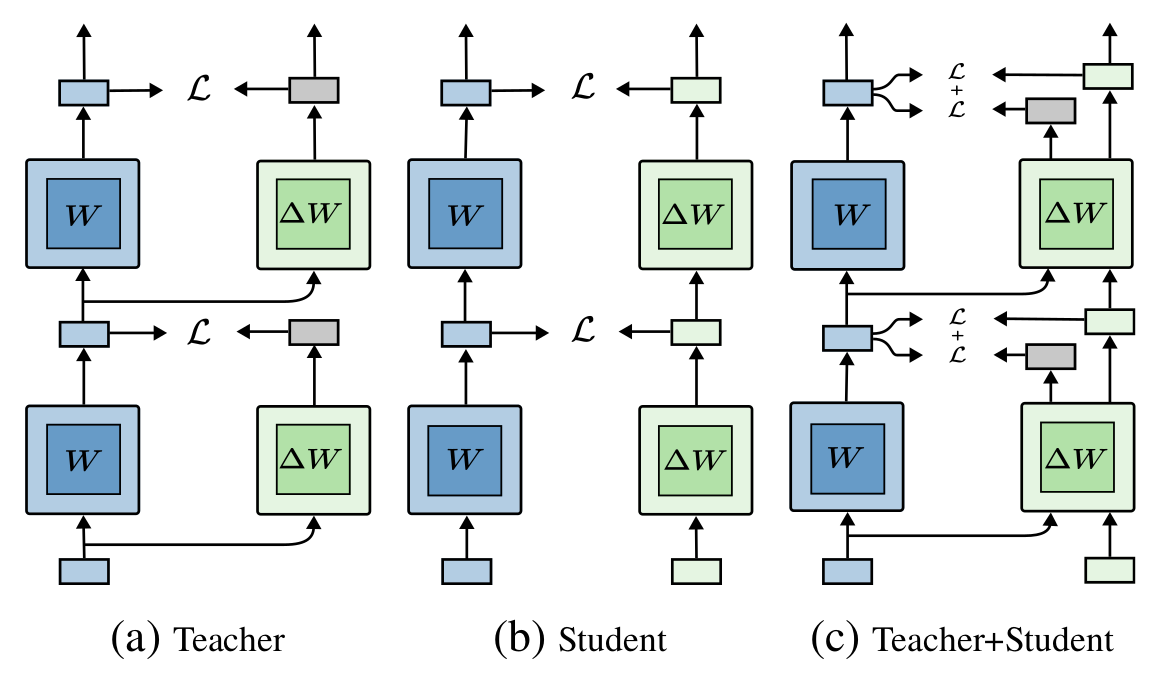
- Nos innovations:
- Généraliser aux couches non-linéaires
- Linear algebra \(\rightarrow\) Feature Distillation
- Généraliser aux modules composites:
- Local \(\rightarrow\) Flexible semi-global
- Améliorer la distillation:
- Teacher-only \(\rightarrow\) Teacher & Student supervision
- Algorithme à faible coût: bottom-first compression
- Innovation: Better teacher/student inputs compromise
![]()
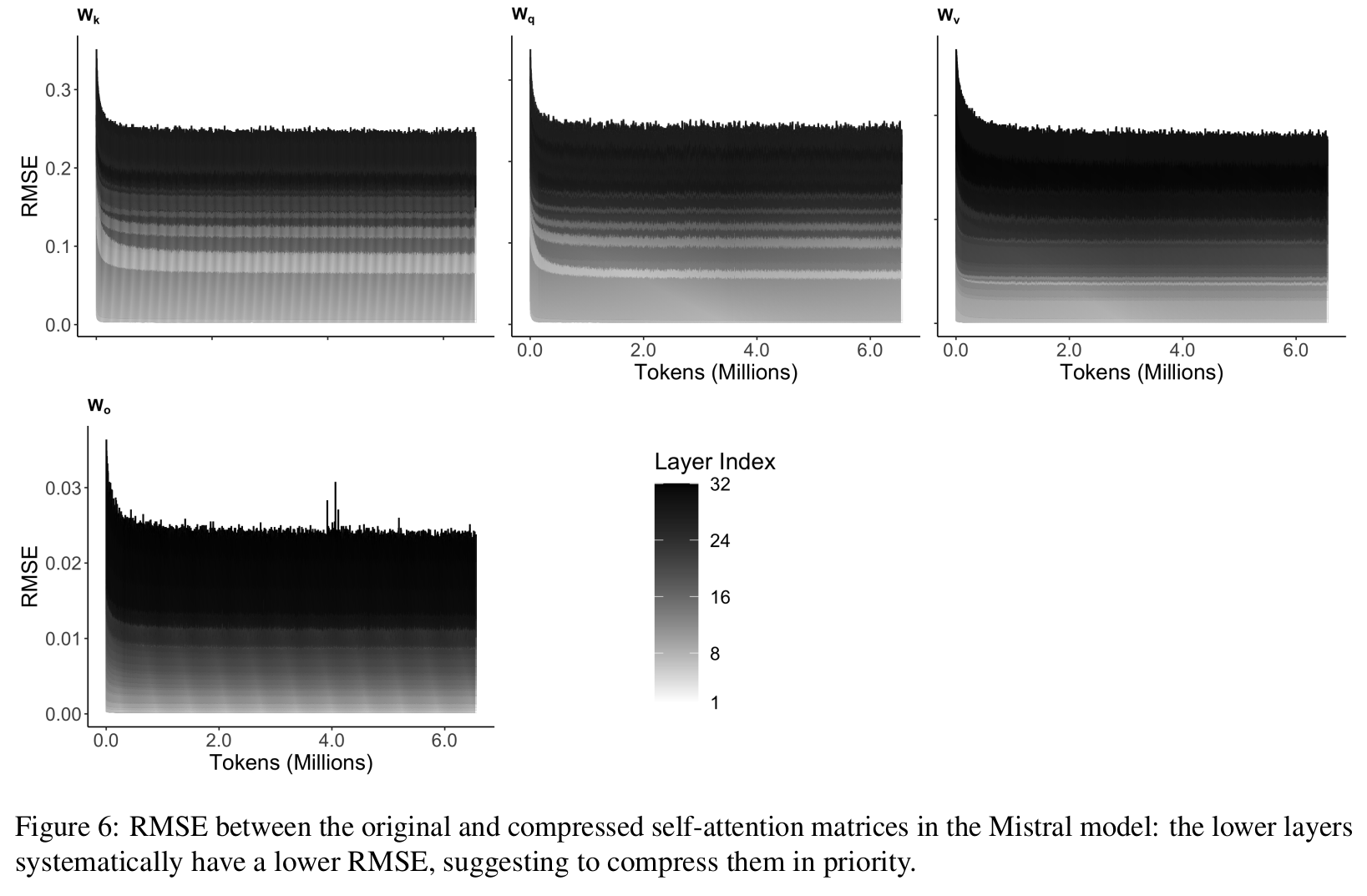
Les couches les plus basses sont les plus robustes à la compression:
![]()
- Bottom-first compression:
- Faible mémoire
- Compresser les couches 1 par 1
- Pas de backprop
- Faible coût computationnel et sample-efficient:
- Pass forward partielle
- Initialisation par la SVD: peu de données requises
Résultats
- Compression de Mixtral-48B, Gemma-27B sur 1xA100
- Bons résultats avec Phi3-14B, Phi2-3B, Mistral-7B
- Mixtral-48b peut tourner sur 1xA100 avec 2048-context & batch=4
- Compression de Mamba-3B, FalconMamba-7B, Whisper-med
Conclusions
- Optimisation du code très efficace
- Small LLM, mais giga-data ! (15T-toks)
- Défis: LLM on the edge; mise à jour
Merci !
cerisara@loria.fr
Appendix slides